 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESSR: An 8K@30FPS Super-Resolution Accelerator With Edge Selective Network
Paper and Code
Mar 26, 2025
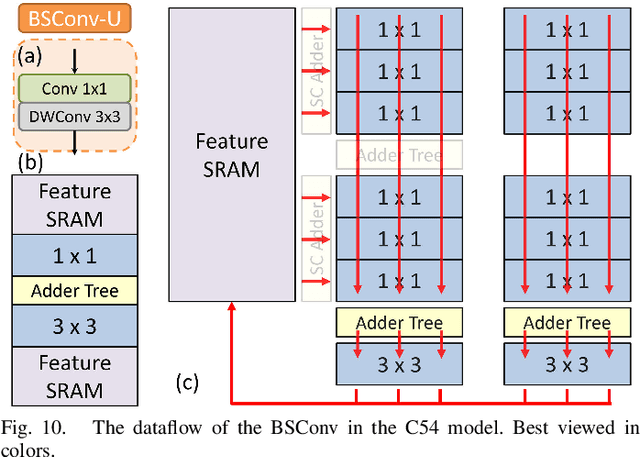
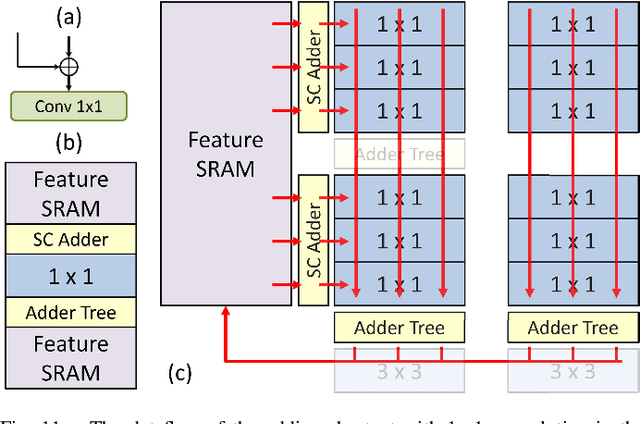
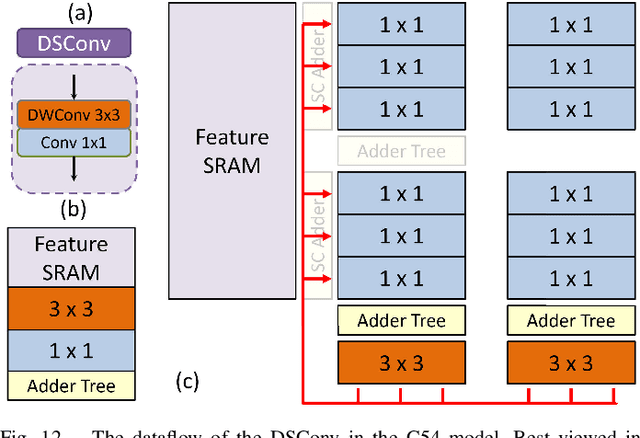
Deep learning-based super-resolution (SR) is challenging to implement in resource-constrained edge devices for resolutions beyond full HD due to its high computational complexity and memory bandwidth requirements. This paper introduces an 8K@30FPS SR accelerator with edge-selective dynamic input processing. Dynamic processing chooses the appropriate subnets for different patches based on simple input edge criteria, achieving a 50\% MAC reduction with only a 0.1dB PSNR decrease. The quality of reconstruction images is guaranteed and maximized its potential with \textit{resource adaptive model switching} even under resource constraints. In conjunction with hardware-specific refinements, the model size is reduced by 84\% to 51K, but with a decrease of less than 0.6dB PSNR. Additionally, to support dynamic processing with high utilization, this design incorporates a \textit{configurable group of layer mapping} that synergizes with the \textit{structure-friendly fusion block}, resulting in 77\% hardware utilization and up to 79\% reduction in feature SRAM access. The implementation, using the TSMC 28nm process, can achieve 8K@30FPS throughput at 800MHz with a gate count of 2749K, 0.2075W power consumption, and 4797Mpixels/J energy efficiency, exceeding previous work.