 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Low-Rank Dilemma of Linear Attention
Paper and Code
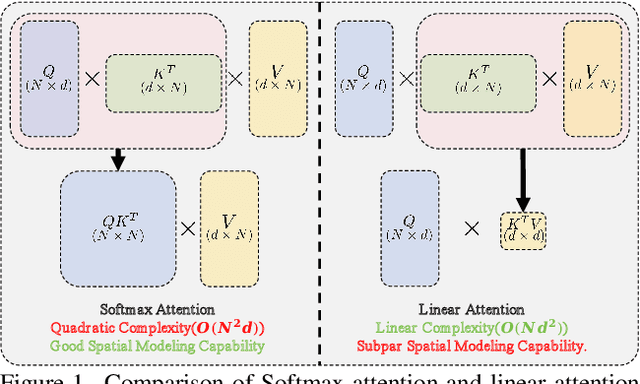

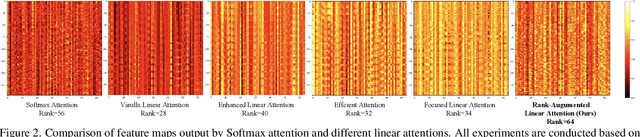

The Softmax attention mechanism in Transformer models is notoriously computationally expensive, particularly due to its quadratic complexity, posing significant challenges in vision applications. In contrast, linear attention provides a far more efficient solution by reducing the complexity to linear levels. However, compared to Softmax attention, linear attention often experiences significant performance degradation. Our experiments indicate that this performance drop is due to the low-rank nature of linear attention's feature map, which hinders its ability to adequately model complex spatial information. In this paper, to break the low-rank dilemma of linear attention, we conduct rank analysis from two perspectives: the KV buffer and the output features. Consequently, we introduce Rank-Augmented Linear Attention (RALA), which rivals the performance of Softmax attention while maintaining linear complexity and high efficiency. Based on RALA, we construct the Rank-Augmented Vision Linear Transformer (RAVLT). Extensive experiments demonstrate that RAVLT achieves excellent performance across various vision tasks. Specifically, without using any additional labels, data, or supervision during training, RAVLT achieves an 84.4% Top-1 accuracy on ImageNet-1k with only 26M parameters and 4.6G FLOPs. This result significantly surpasses previous linear attention mechanisms, fully illustrating the potential of RALA. Code will be available at https://github.com/qhfan/RALA.