 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptFix: Few-shot Backdoor Removal via Adversarial Prompt Tuning
Jun 06, 2024Pre-trained language models (PLMs) have attracted enormous attention over the past few years with their unparalleled performances. Meanwhile, the soaring cost to train PLMs as well as their amazing generalizability have jointly contributed to few-shot fine-tuning and prompting as the most popular training paradigms for natural language processing (NLP) models. Nevertheless, existing studies have shown that these NLP models can be backdoored such that model behavior is manipulated when trigger tokens are presented. In this paper, we propose PromptFix, a novel backdoor mitigation strategy for NLP models via adversarial prompt-tuning in few-shot settings. Unlike existing NLP backdoor removal methods, which rely on accurate trigger inversion and subsequent model fine-tuning, PromptFix keeps the model parameters intact and only utilizes two extra sets of soft tokens which approximate the trigger and counteract it respectively. The use of soft tokens and adversarial optimization eliminates the need to enumerate possible backdoor configurations and enables an adaptive balance between trigger finding and preservation of performance. Experiments with various backdoor attacks validate the effectiveness of the proposed method and the performances when domain shift is present further shows PromptFix's applicability to models pretrained on unknown data source which is the common case in prompt tuning scenarios.
Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization
May 28, 2024



Researchers have been studying approaches to steer the behavior of Large Language Models (LLMs) and build personalized LLMs tailored for various applications. While fine-tuning seems to be a direct solution, it requires substantial computational resources and may significantly affect the utility of the original LLM. Recent endeavors have introduced more lightweight strategies, focusing on extracting "steering vectors" to guide the model's output toward desired behaviors by adjusting activations within specific layers of the LLM's transformer architecture. However, such steering vectors are directly extracted from the activations of human preference data and thus often lead to suboptimal results and occasional failures, especially in alignment-related scenarios. This work proposes an innovative approach that could produce more effective steering vectors through bi-directional preference optimization. Our method is designed to allow steering vectors to directly influence the generation probability of contrastive human preference data pairs, thereby offering a more precise representation of the target behavior. By carefully adjusting the direction and magnitude of the steering vector, we enabled personalized control over the desired behavior across a spectrum of intensities. Extensive experimentation across various open-ended generation tasks, particularly focusing on steering AI personas, has validated the efficacy of our approach. Moreover, we comprehensively investigate critical alignment-concerning scenarios, such as managing truthfulness, mitigating hallucination, and addressing jailbreaking attacks. Remarkably, our method can still demonstrate outstanding steering effectiveness across these scenarios. Furthermore, we showcase the transferability of our steering vectors across different models/LoRAs and highlight the synergistic benefits of applying multiple vectors simultaneously.
WordGame: Efficient & Effective LLM Jailbreak via Simultaneous Obfuscation in Query and Response
May 22, 2024



The recent breakthrough in large language models (LLMs) such as ChatGPT has revolutionized production processes at an unprecedented pace. Alongside this progress also comes mounting concerns about LLMs' susceptibility to jailbreaking attacks, which leads to the generation of harmful or unsafe content. While safety alignment measures have been implemented in LLMs to mitigate existing jailbreak attempts and force them to become increasingly complicated, it is still far from perfect. In this paper, we analyze the common pattern of the current safety alignment and show that it is possible to exploit such patterns for jailbreaking attacks by simultaneous obfuscation in queries and responses. Specifically, we propose WordGame attack, which replaces malicious words with word games to break down the adversarial intent of a query and encourage benign content regarding the games to precede the anticipated harmful content in the response, creating a context that is hardly covered by any corpus used for safety alignment. Extensive experiments demonstrate that WordGame attack can break the guardrails of the current leading proprietary and open-source LLMs, including the latest Claude-3, GPT-4, and Llama-3 models. Further ablation studies on such simultaneous obfuscation in query and response provide evidence of the merits of the attack strategy beyond an individual attack.
VQAttack: Transferable Adversarial Attacks on Visual Question Answering via Pre-trained Models
Feb 16, 2024
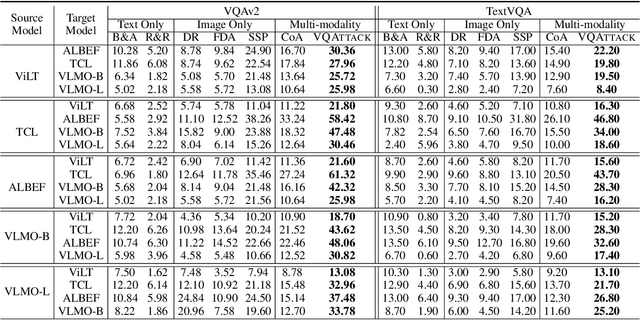
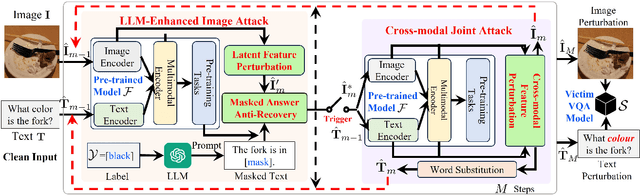
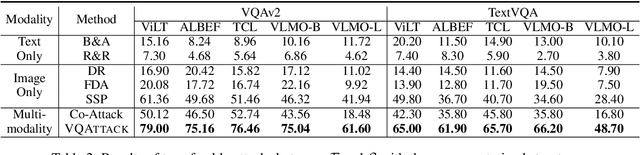
Visual Question Answering (VQA) is a fundamental task in computer vision and natural language process fields. Although the ``pre-training & finetuning'' learning paradigm significantly improves the VQA performance, the adversarial robustness of such a learning paradigm has not been explored. In this paper, we delve into a new problem: using a pre-trained multimodal source model to create adversarial image-text pairs and then transferring them to attack the target VQA models. Correspondingly, we propose a novel VQAttack model, which can iteratively generate both image and text perturbations with the designed modules: the large language model (LLM)-enhanced image attack and the cross-modal joint attack module. At each iteration, the LLM-enhanced image attack module first optimizes the latent representation-based loss to generate feature-level image perturbations. Then it incorporates an LLM to further enhance the image perturbations by optimizing the designed masked answer anti-recovery loss. The cross-modal joint attack module will be triggered at a specific iteration, which updates the image and text perturbations sequentially. Notably, the text perturbation updates are based on both the learned gradients in the word embedding space and word synonym-based substitution. Experimental results on two VQA datasets with five validated models demonstrate the effectiveness of the proposed VQAttack in the transferable attack setting, compared with state-of-the-art baselines. This work reveals a significant blind spot in the ``pre-training & fine-tuning'' paradigm on VQA tasks. Source codes will be released.
VLAttack: Multimodal Adversarial Attacks on Vision-Language Tasks via Pre-trained Models
Oct 07, 2023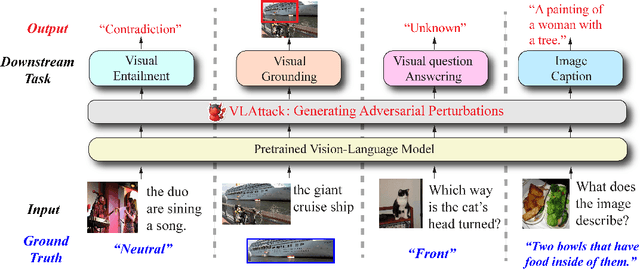
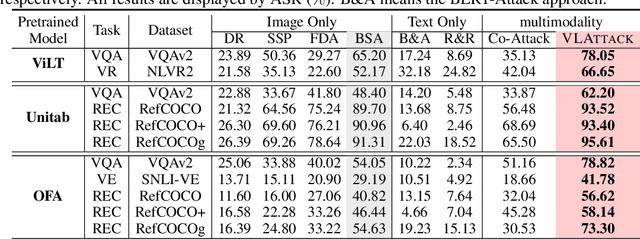
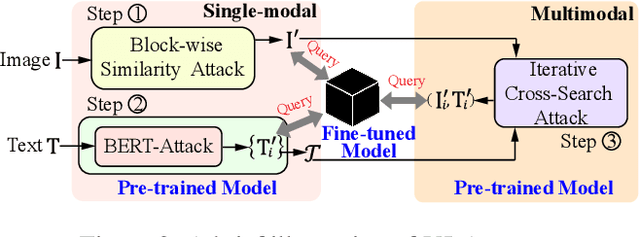
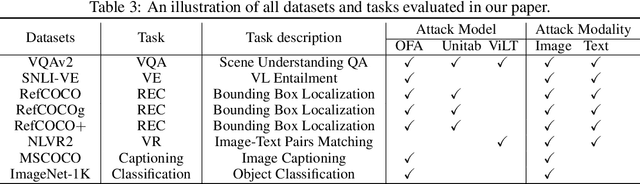
Vision-Language (VL) pre-trained models have shown their superiority on many multimodal tasks. However, the adversarial robustness of such models has not been fully explored. Existing approaches mainly focus on exploring the adversarial robustness under the white-box setting, which is unrealistic. In this paper, we aim to investigate a new yet practical task to craft image and text perturbations using pre-trained VL models to attack black-box fine-tuned models on different downstream tasks. Towards this end, we propose VLAttack to generate adversarial samples by fusing perturbations of images and texts from both single-modal and multimodal levels. At the single-modal level, we propose a new block-wise similarity attack (BSA) strategy to learn image perturbations for disrupting universal representations. Besides, we adopt an existing text attack strategy to generate text perturbations independent of the image-modal attack. At the multimodal level, we design a novel iterative cross-search attack (ICSA) method to update adversarial image-text pairs periodically, starting with the outputs from the single-modal level. We conduct extensive experiments to attack three widely-used VL pretrained models for six tasks on eight datasets. Experimental results show that the proposed VLAttack framework achieves the highest attack success rates on all tasks compared with state-of-the-art baselines, which reveals a significant blind spot in the deployment of pre-trained VL models. Codes will be released soon.