 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQAttack: Transferable Adversarial Attacks on Visual Question Answering via Pre-trained Models
Paper and Code
Feb 16, 2024
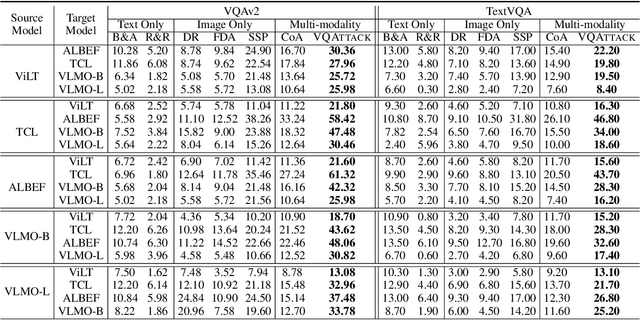
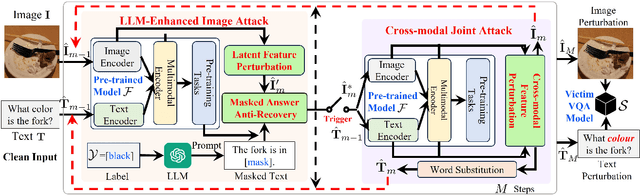
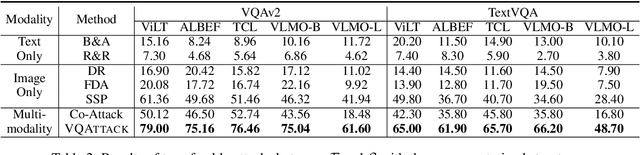
Visual Question Answering (VQA) is a fundamental task in computer vision and natural language process fields. Although the ``pre-training & finetuning'' learning paradigm significantly improves the VQA performance, the adversarial robustness of such a learning paradigm has not been explored. In this paper, we delve into a new problem: using a pre-trained multimodal source model to create adversarial image-text pairs and then transferring them to attack the target VQA models. Correspondingly, we propose a novel VQAttack model, which can iteratively generate both image and text perturbations with the designed modules: the large language model (LLM)-enhanced image attack and the cross-modal joint attack module. At each iteration, the LLM-enhanced image attack module first optimizes the latent representation-based loss to generate feature-level image perturbations. Then it incorporates an LLM to further enhance the image perturbations by optimizing the designed masked answer anti-recovery loss. The cross-modal joint attack module will be triggered at a specific iteration, which updates the image and text perturbations sequentially. Notably, the text perturbation updates are based on both the learned gradients in the word embedding space and word synonym-based substitution. Experimental results on two VQA datasets with five validated models demonstrate the effectiveness of the proposed VQAttack in the transferable attack setting, compared with state-of-the-art baselines. This work reveals a significant blind spot in the ``pre-training & fine-tuning'' paradigm on VQA tasks. Source codes will be released.