 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Background Noise in Neural Speech Generation
Feb 23, 2021

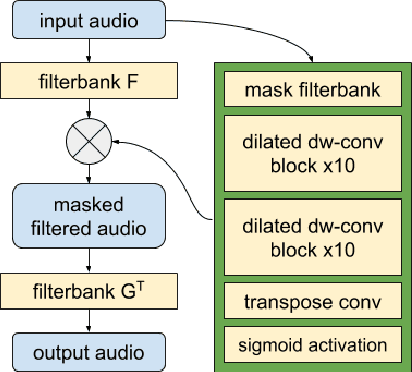

Recent advances in neural-network based generative modeling of speech has shown great potential for speech coding. However, the performance of such models drops when the input is not clean speech, e.g., in the presence of background noise, preventing its use in practical applications. In this paper we examine the reason and discuss methods to overcome this issue. Placing a denoising preprocessing stage when extracting features and target clean speech during training is shown to be the best performing strategy.
Generative Speech Coding with Predictive Variance Regularization
Feb 18, 2021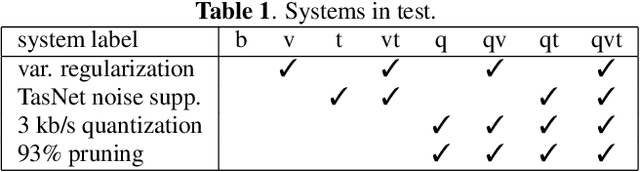
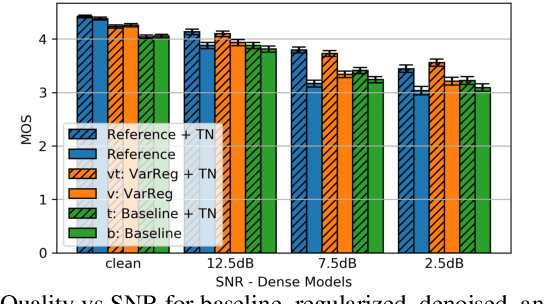
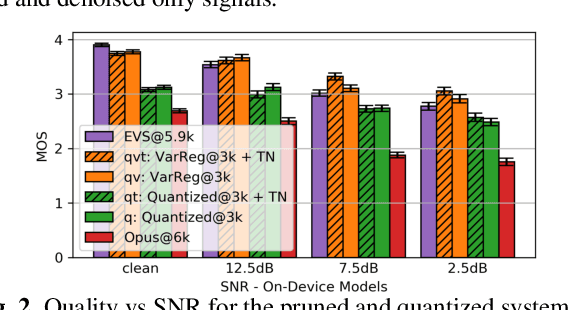
The recent emergence of machine-learning based generative models for speech suggests a significant reduction in bit rate for speech codecs is possible. However, the performance of generative models deteriorates significantly with the distortions present in real-world input signals. We argue that this deterioration is due to the sensitivity of the maximum likelihood criterion to outliers and the ineffectiveness of modeling a sum of independent signals with a single autoregressive model. We introduce predictive-variance regularization to reduce the sensitivity to outliers, resulting in a significant increase in performance. We show that noise reduction to remove unwanted signals can significantly increase performance. We provide extensive subjective performance evaluations that show that our system based on generative modeling provides state-of-the-art coding performance at 3 kb/s for real-world speech signals at reasonable computational complexity.