 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Long Roll-outs of Auto-regressive Neural Operators for the Compressible Navier-Stokes Equations with Conserved Quantity Correction
Jan 30, 2026Deep learning has been proposed as an efficient alternative for the numerical approximation of PDE solutions, offering fast, iterative simulation of PDEs through the approximation of solution operators. However, deep learning solutions have struggle to perform well over long prediction durations due to the accumulation of auto-regressive error, which is compounded by the inability of models to conserve physical quantities. In this work, we present conserved quantity correction, a model-agnostic technique for incorporation physical conservation criteria within deep learning models. Our results demonstrate consistent improvement in the long-term stability of auto-regressive neural operator models, regardless of the model architecture. Furthermore, we analyze the performance of neural operators from the spectral domain, highlighting significant limitations of present architectures. These results highlight the need for future work to consider architectures that place specific emphasis on high frequency components, which are integral to the understanding and modeling of turbulent flows.
Stage Aware Diagnosis of Diabetic Retinopathy via Ordinal Regression
Nov 18, 2025Diabetic Retinopathy (DR) has emerged as a major cause of preventable blindness in recent times. With timely screening and intervention, the condition can be prevented from causing irreversible damage. The work introduces a state-of-the-art Ordinal Regression-based DR Detection framework that uses the APTOS-2019 fundus image dataset. A widely accepted combination of preprocessing methods: Green Channel (GC) Extraction, Noise Masking, and CLAHE, was used to isolate the most relevant features for DR classification. Model performance was evaluated using the Quadratic Weighted Kappa, with a focus on agreement between results and clinical grading. Our Ordinal Regression approach attained a QWK score of 0.8992, setting a new benchmark on the APTOS dataset.
Supervised Multilabel Image Classification Using Residual Networks with Probabilistic Reasoning
Nov 15, 2025Multilabel image categorization has drawn interest recently because of its numerous computer vision applications. The proposed work introduces a novel method for classifying multilabel images using the COCO-2014 dataset and a modified ResNet-101 architecture. By simulating label dependencies and uncertainties, the approach uses probabilistic reasoning to improve prediction accuracy. Extensive tests show that the model outperforms earlier techniques and approaches to state-of-the-art outcomes in multilabel categorization. The work also thoroughly assesses the model's performance using metrics like precision-recall score and achieves 0.794 mAP on COCO-2014, outperforming ResNet-SRN (0.771) and Vision Transformer baselines (0.785). The novelty of the work lies in integrating probabilistic reasoning into deep learning models to effectively address the challenges presented by multilabel scenarios.
DeiTFake: Deepfake Detection Model using DeiT Multi-Stage Training
Nov 15, 2025
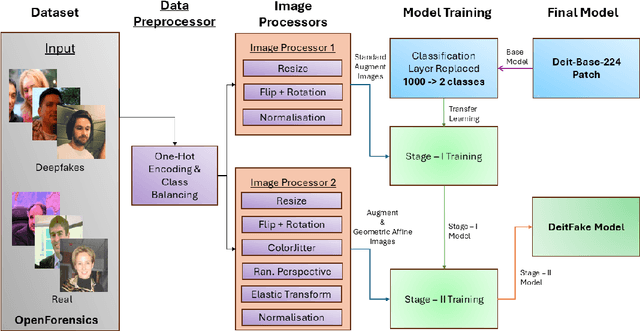


Deepfakes are major threats to the integrity of digital media. We propose DeiTFake, a DeiT-based transformer and a novel two-stage progressive training strategy with increasing augmentation complexity. The approach applies an initial transfer-learning phase with standard augmentations followed by a fine-tuning phase using advanced affine and deepfake-specific augmentations. DeiT's knowledge distillation model captures subtle manipulation artifacts, increasing robustness of the detection model. Trained on the OpenForensics dataset (190,335 images), DeiTFake achieves 98.71\% accuracy after stage one and 99.22\% accuracy with an AUROC of 0.9997, after stage two, outperforming the latest OpenForensics baselines. We analyze augmentation impact and training schedules, and provide practical benchmarks for facial deepfake detection.
Exploring AI in Steganography and Steganalysis: Trends, Clusters, and Sustainable Development Potential
Nov 15, 2025Steganography and steganalysis are strongly related subjects of information security. Over the past decade, many powerful and efficient artificial intelligence (AI) - driven techniques have been designed and presented during research into steganography as well as steganalysis. This study presents a scientometric analysis of AI-driven steganography-based data hiding techniques using a thematic modelling approach. A total of 654 articles within the time span of 2017 to 2023 have been considered. Experimental evaluation of the study reveals that 69% of published articles are from Asian countries. The China is on top (TP:312), followed by India (TP-114). The study mainly identifies seven thematic clusters: steganographic image data hiding, deep image steganalysis, neural watermark robustness, linguistic steganography models, speech steganalysis algorithms, covert communication networks, and video steganography techniques. The proposed study also assesses the scope of AI-steganography under the purview of sustainable development goals (SDGs) to present the interdisciplinary reciprocity between them. It has been observed that only 18 of the 654 articles are aligned with one of the SDGs, which shows that limited studies conducted in alignment with SDG goals. SDG9 which is Industry, Innovation, and Infrastructure is leading among 18 SDGs mapped articles. To the top of our insight, this study is the unique one to present a scientometric study on AI-driven steganography-based data hiding techniques. In the context of descriptive statistics, the study breaks down the underlying causes of observed trends, including the influence of DL developments, trends in East Asia and maturity of foundational methods. The work also stresses upon the critical gaps in societal alignment, particularly the SDGs, ultimately working on unveiling the field's global impact on AI security challenges.
Learn and Search: An Elegant Technique for Object Lookup using Contrastive Learning
Mar 12, 2024The rapid proliferation of digital content and the ever-growing need for precise object recognition and segmentation have driven the advancement of cutting-edge techniques in the field of object classification and segmentation. This paper introduces "Learn and Search", a novel approach for object lookup that leverages the power of contrastive learning to enhance the efficiency and effectiveness of retrieval systems. In this study, we present an elegant and innovative methodology that integrates deep learning principles and contrastive learning to tackle the challenges of object search. Our extensive experimentation reveals compelling results, with "Learn and Search" achieving superior Similarity Grid Accuracy, showcasing its efficacy in discerning regions of utmost similarity within an image relative to a cropped image. The seamless fusion of deep learning and contrastive learning to address the intricacies of object identification not only promises transformative applications in image recognition, recommendation systems, and content tagging but also revolutionizes content-based search and retrieval. The amalgamation of these techniques, as exemplified by "Learn and Search," represents a significant stride in the ongoing evolution of methodologies in the dynamic realm of object classification and segmentation.
Unsupervised learning based object detection using Contrastive Learning
Feb 21, 2024Training image-based object detectors presents formidable challenges, as it entails not only the complexities of object detection but also the added intricacies of precisely localizing objects within potentially diverse and noisy environments. However, the collection of imagery itself can often be straightforward; for instance, cameras mounted in vehicles can effortlessly capture vast amounts of data in various real-world scenarios. In light of this, we introduce a groundbreaking method for training single-stage object detectors through unsupervised/self-supervised learning. Our state-of-the-art approach has the potential to revolutionize the labeling process, substantially reducing the time and cost associated with manual annotation. Furthermore, it paves the way for previously unattainable research opportunities, particularly for large, diverse, and challenging datasets lacking extensive labels. In contrast to prevalent unsupervised learning methods that primarily target classification tasks, our approach takes on the unique challenge of object detection. We pioneer the concept of intra-image contrastive learning alongside inter-image counterparts, enabling the acquisition of crucial location information essential for object detection. The method adeptly learns and represents this location information, yielding informative heatmaps. Our results showcase an outstanding accuracy of \textbf{89.2\%}, marking a significant breakthrough of approximately \textbf{15x} over random initialization in the realm of unsupervised object detection within the field of computer vision.
Pattern Based Multivariable Regression using Deep Learning (PBMR-DP)
Mar 09, 2022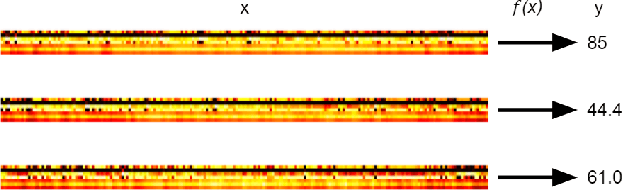
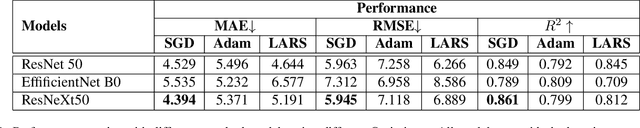
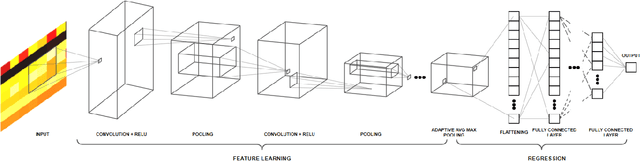

We propose a deep learning methodology for multivariate regression that is based on pattern recognition that triggers fast learning over sensor data. We used a conversion of sensors-to-image which enables us to take advantage of Computer Vision architectures and training processes. In addition to this data preparation methodology, we explore the use of state-of-the-art architectures to generate regression outputs to predict agricultural crop continuous yield information. Finally, we compare with some of the top models reported in MLCAS2021. We found that using a straightforward training process, we were able to accomplish an MAE of 4.394, RMSE of 5.945, and R^2 of 0.861.
HDRVideo-GAN: Deep Generative HDR Video Reconstruction
Nov 03, 2021


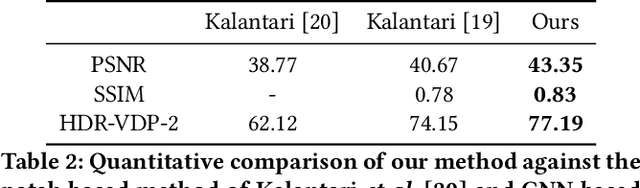
High dynamic range (HDR) videos provide a more visually realistic experience than the standard low dynamic range (LDR) videos. Despite having significant progress in HDR imaging, it is still a challenging task to capture high-quality HDR video with a conventional off-the-shelf camera. Existing approaches rely entirely on using dense optical flow between the neighboring LDR sequences to reconstruct an HDR frame. However, they lead to inconsistencies in color and exposure over time when applied to alternating exposures with noisy frames. In this paper, we propose an end-to-end GAN-based framework for HDR video reconstruction from LDR sequences with alternating exposures. We first extract clean LDR frames from noisy LDR video with alternating exposures with a denoising network trained in a self-supervised setting. Using optical flow, we then align the neighboring alternating-exposure frames to a reference frame and then reconstruct high-quality HDR frames in a complete adversarial setting. To further improve the robustness and quality of generated frames, we incorporate temporal stability-based regularization term along with content and style-based losses in the cost function during the training procedure. Experimental results demonstrate that our framework achieves state-of-the-art performance and generates superior quality HDR frames of a video over the existing methods.
Bayesian Optimization -- Multi-Armed Bandit Problem
Dec 14, 2020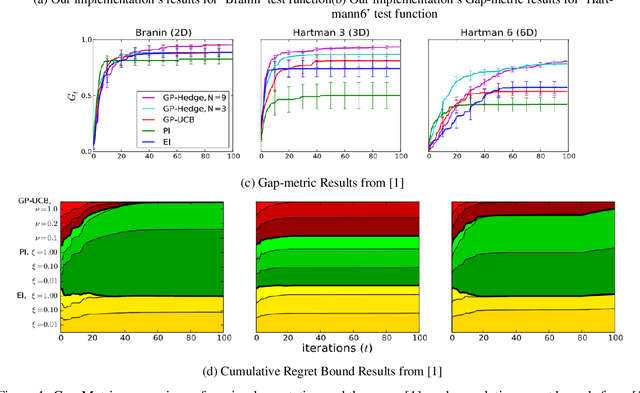
In this report, we survey Bayesian Optimization methods focussed on the Multi-Armed Bandit Problem. We take the help of the paper "Portfolio Allocation for Bayesian Optimization". We report a small literature survey on the acquisition functions and the types of portfolio strategies used in papers discussing Bayesian Optimization. We also replicate the experiments and report our findings and compare them to the results in the paper. Code link: https://colab.research.google.com/drive/1GZ14klEDoe3dcBeZKo5l8qqrKf_GmBDn?usp=sharing#scrollTo=XgIBau3O45_V.