 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn and Search: An Elegant Technique for Object Lookup using Contrastive Learning
Mar 12, 2024The rapid proliferation of digital content and the ever-growing need for precise object recognition and segmentation have driven the advancement of cutting-edge techniques in the field of object classification and segmentation. This paper introduces "Learn and Search", a novel approach for object lookup that leverages the power of contrastive learning to enhance the efficiency and effectiveness of retrieval systems. In this study, we present an elegant and innovative methodology that integrates deep learning principles and contrastive learning to tackle the challenges of object search. Our extensive experimentation reveals compelling results, with "Learn and Search" achieving superior Similarity Grid Accuracy, showcasing its efficacy in discerning regions of utmost similarity within an image relative to a cropped image. The seamless fusion of deep learning and contrastive learning to address the intricacies of object identification not only promises transformative applications in image recognition, recommendation systems, and content tagging but also revolutionizes content-based search and retrieval. The amalgamation of these techniques, as exemplified by "Learn and Search," represents a significant stride in the ongoing evolution of methodologies in the dynamic realm of object classification and segmentation.
Unsupervised learning based object detection using Contrastive Learning
Feb 21, 2024Training image-based object detectors presents formidable challenges, as it entails not only the complexities of object detection but also the added intricacies of precisely localizing objects within potentially diverse and noisy environments. However, the collection of imagery itself can often be straightforward; for instance, cameras mounted in vehicles can effortlessly capture vast amounts of data in various real-world scenarios. In light of this, we introduce a groundbreaking method for training single-stage object detectors through unsupervised/self-supervised learning. Our state-of-the-art approach has the potential to revolutionize the labeling process, substantially reducing the time and cost associated with manual annotation. Furthermore, it paves the way for previously unattainable research opportunities, particularly for large, diverse, and challenging datasets lacking extensive labels. In contrast to prevalent unsupervised learning methods that primarily target classification tasks, our approach takes on the unique challenge of object detection. We pioneer the concept of intra-image contrastive learning alongside inter-image counterparts, enabling the acquisition of crucial location information essential for object detection. The method adeptly learns and represents this location information, yielding informative heatmaps. Our results showcase an outstanding accuracy of \textbf{89.2\%}, marking a significant breakthrough of approximately \textbf{15x} over random initialization in the realm of unsupervised object detection within the field of computer vision.
Productive Crop Field Detection: A New Dataset and Deep Learning Benchmark Results
May 19, 2023



In precision agriculture, detecting productive crop fields is an essential practice that allows the farmer to evaluate operating performance separately and compare different seed varieties, pesticides, and fertilizers. However, manually identifying productive fields is often a time-consuming and error-prone task. Previous studies explore different methods to detect crop fields using advanced machine learning algorithms, but they often lack good quality labeled data. In this context, we propose a high-quality dataset generated by machine operation combined with Sentinel-2 images tracked over time. As far as we know, it is the first one to overcome the lack of labeled samples by using this technique. In sequence, we apply a semi-supervised classification of unlabeled data and state-of-the-art supervised and self-supervised deep learning methods to detect productive crop fields automatically. Finally, the results demonstrate high accuracy in Positive Unlabeled learning, which perfectly fits the problem where we have high confidence in the positive samples. Best performances have been found in Triplet Loss Siamese given the existence of an accurate dataset and Contrastive Learning considering situations where we do not have a comprehensive labeled dataset available.
CLAWS: Contrastive Learning with hard Attention and Weak Supervision
Dec 01, 2021
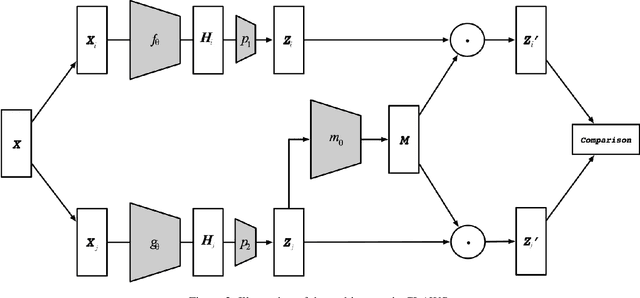
Learning effective visual representations without human supervision is a long-standing problem in computer vision. Recent advances in self-supervised learning algorithms have utilized contrastive learning, with methods such as SimCLR, which applies a composition of augmentations to an image, and minimizes a contrastive loss between the two augmented images. In this paper, we present CLAWS, an annotation-efficient learning framework, addressing the problem of manually labeling large-scale agricultural datasets along with potential applications such as anomaly detection and plant growth analytics. CLAWS uses a network backbone inspired by SimCLR and weak supervision to investigate the effect of contrastive learning within class clusters. In addition, we inject a hard attention mask to the cropped input image before maximizing agreement between the image pairs using a contrastive loss function. This mask forces the network to focus on pertinent object features and ignore background features. We compare results between a supervised SimCLR and CLAWS using an agricultural dataset with 227,060 samples consisting of 11 different crop classes. Our experiments and extensive evaluations show that CLAWS achieves a competitive NMI score of 0.7325. Furthermore, CLAWS engenders the creation of low dimensional representations of very large datasets with minimal parameter tuning and forming well-defined clusters, which lends themselves to using efficient, transparent, and highly interpretable clustering methods such as Gaussian Mixture Models.
Cluster Analysis with Deep Embeddings and Contrastive Learning
Oct 02, 2021
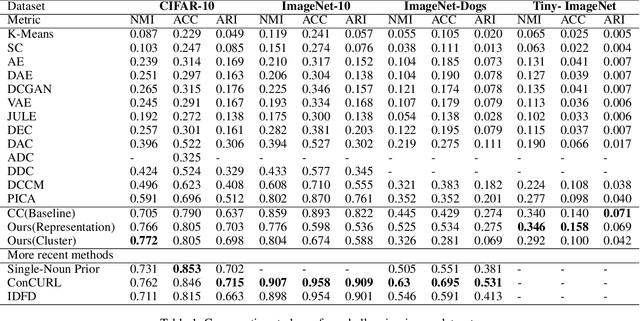


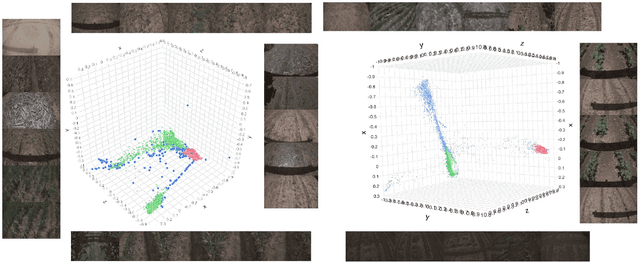
Unsupervised disentangled representation learning is a long-standing problem in computer vision. This work proposes a novel framework for performing image clustering from deep embeddings by combining instance-level contrastive learning with a deep embedding based cluster center predictor. Our approach jointly learns representations and predicts cluster centers in an end-to-end manner. This is accomplished via a three-pronged approach that combines a clustering loss, an instance-wise contrastive loss, and an anchor loss. Our fundamental intuition is that using an ensemble loss that incorporates instance-level features and a clustering procedure focusing on semantic similarity reinforces learning better representations in the latent space. We observe that our method performs exceptionally well on popular vision datasets when evaluated using standard clustering metrics such as Normalized Mutual Information (NMI), in addition to producing geometrically well-separated cluster embeddings as defined by the Euclidean distance. Our framework performs on par with widely accepted clustering methods and outperforms the state-of-the-art contrastive learning method on the CIFAR-10 dataset with an NMI score of 0.772, a 7-8% improvement on the strong baseline.
Generalizable semi-supervised learning method to estimate mass from sparsely annotated images
Mar 05, 2020



Mass flow estimation is of great importance to several industries, and it can be quite challenging to obtain accurate estimates due to limitation in expense or general infeasibility. In the context of agricultural applications, yield monitoring is a key component to precision agriculture and mass flow is the critical factor to measure. Measuring mass flow allows for field productivity analysis, cost minimization, and adjustments to machine efficiency. Methods such as volume or force-impact have been used to measure mass flow; however, these methods are limited in application and accuracy. In this work, we use deep learning to develop and test a vision system that can accurately estimate the mass of sugarcane while running in real-time on a sugarcane harvester during operation. The deep learning algorithm that is used to estimate mass flow is trained using very sparsely annotated images (semi-supervised) using only final load weights (aggregated weights over a certain period of time). The deep neural network (DNN) succeeds in capturing the mass of sugarcane accurately and surpasses older volumetric-based methods, despite highly varying lighting and material colors in the images. The deep neural network is initially trained to predict mass on laboratory data (bamboo) and then transfer learning is utilized to apply the same methods to estimate mass of sugarcane. Using a vision system with a relatively lightweight deep neural network we are able to estimate mass of bamboo with an average error of 4.5% and 5.9% for a select season of sugarcane.
Granular Learning with Deep Generative Models using Highly Contaminated Data
Jan 06, 2020
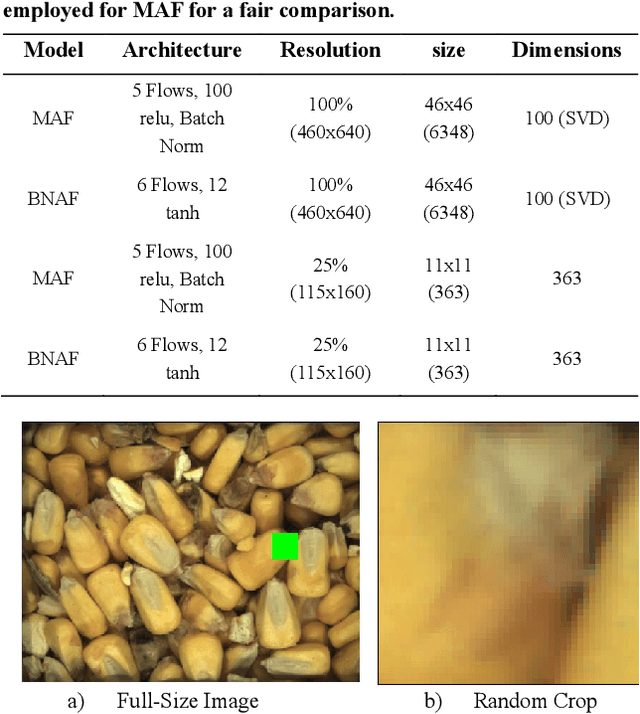
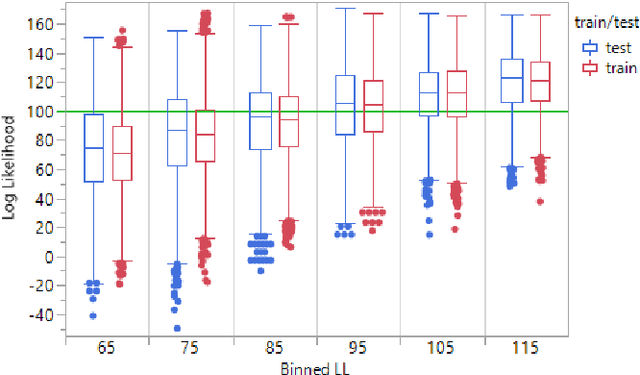

An approach to utilize recent advances in deep generative models for anomaly detection in a granular (continuous) sense on a real-world image dataset with quality issues is detailed using recent normalizing flow models, with implications in many other applications/domains/data types. The approach is completely unsupervised (no annotations available) but qualitatively shown to provide accurate semantic labeling for images via heatmaps of the scaled log-likelihood overlaid on the images. When sorted based on the median values per image, clear trends in quality are observed. Furthermore, downstream classification is shown to be possible and effective via a weakly supervised approach using the log-likelihood output from a normalizing flow model as a training signal for a feature-extracting convolutional neural network. The pre-linear dense layer outputs on the CNN are shown to disentangle high level representations and efficiently cluster various quality issues. Thus, an entirely non-annotated (fully unsupervised) approach is shown possible for accurate estimation and classification of quality issues..
Deep Generative Models Strike Back! Improving Understanding and Evaluation in Light of Unmet Expectations for OoD Data
Nov 12, 2019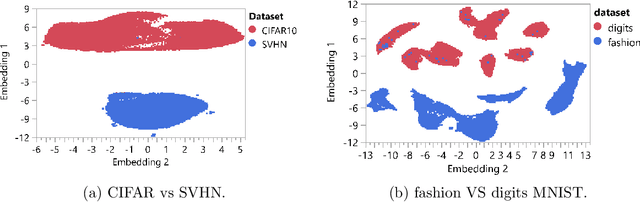


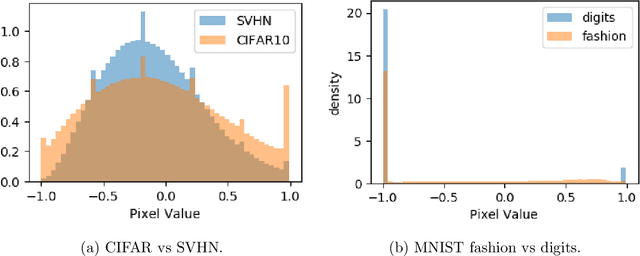
Advances in deep generative and density models have shown impressive capacity to model complex probability density functions in lower-dimensional space. Also, applying such models to high-dimensional image data to model the PDF has shown poor generalization, with out-of-distribution data being assigned equal or higher likelihood than in-sample data. Methods to deal with this have been proposed that deviate from a fully unsupervised approach, requiring large ensembles or additional knowledge about the data, not commonly available in the real-world. In this work, the previously offered reasoning behind these issues is challenged empirically, and it is shown that data-sets such as MNIST fashion/digits and CIFAR10/SVHN are trivially separable and have no overlap on their respective data manifolds that explains the higher OoD likelihood. Models like masked autoregressive flows and block neural autoregressive flows are shown to not suffer from OoD likelihood issues to the extent of GLOW, PixelCNN++, and real NVP. A new avenue is also explored which involves a change of basis to a new space of the same dimension with an orthonormal unitary basis of eigenvectors before modeling. In the test data-sets and models, this aids in pushing down the relative likelihood of the contrastive OoD data set and improve discrimination results. The significance of the density of the original space is maintained, while invertibility remains tractable. Finally, a look to the previous generation of generative models in the form of probabilistic principal component analysis is inspired, and revisited for the same data-sets and shown to work really well for discriminating anomalies based on likelihood in a fully unsupervised fashion compared with pixelCNN++, GLOW, and real NVP with less complexity and faster training. Also, dimensionality reduction using PCA is shown to improve anomaly detection in generative models.
Mass Estimation from Images using Deep Neural Network and Sparse Ground Truth
Sep 10, 2019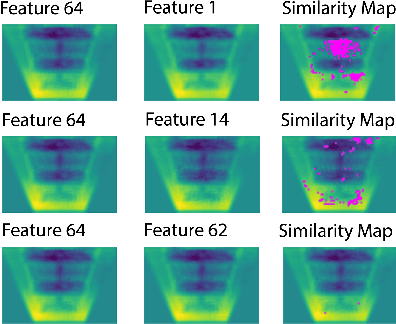


Supervised learning is the workhorse for regression and classification tasks, but the standard approach presumes ground truth for every measurement. In real world applications, limitations due to expense or general in-feasibility due to the specific application are common. In the context of agriculture applications, yield monitoring is one such example where simple-physics based measurements such as volume or force-impact have been used to quantify mass flow, which incur error due to sensor calibration. By utilizing semi-supervised deep learning with gradient aggregation and a sequence of images, in this work we can accurately estimate a physical quantity (mass) with complex data structures and sparse ground truth. Using a vision system capturing images of a sugarcane elevator and running bamboo under controlled testing as a surrogate material to harvesting sugarcane, mass is accurately predicted from images by training a DNN using only final load weights. The DNN succeeds in capturing the complex density physics of random stacking of slender rods internally as part of the mass prediction model, and surpasses older volumetric-based methods for mass prediction. Furthermore, by incorporating knowledge about the system physics through the DNN architecture and penalty terms, improvements in prediction accuracy and stability, as well as faster learning are obtained. It is shown that the classic nonlinear regression optimization can be reformulated with an aggregation term with some independence assumptions to achieve this feat. Since the number of images for any given run are too large to fit on typical GPU vRAM, an implementation is shown that compensates for the limited memory but still achieve fast training times. The same approach presented herein could be applied to other applications like yield monitoring on grain combines or other harvesters using vision or other instrumentation.