 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAWS: Contrastive Learning with hard Attention and Weak Supervision
Dec 01, 2021
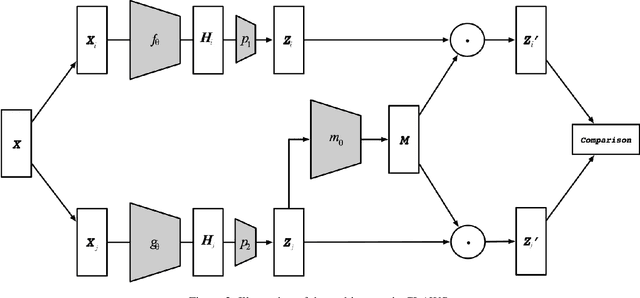
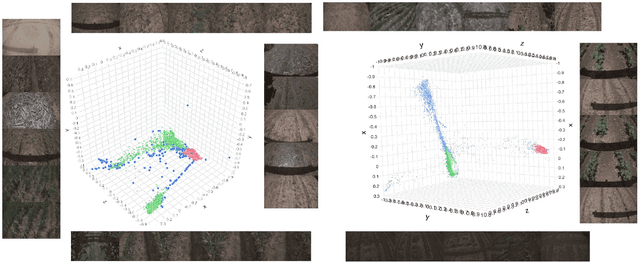
Learning effective visual representations without human supervision is a long-standing problem in computer vision. Recent advances in self-supervised learning algorithms have utilized contrastive learning, with methods such as SimCLR, which applies a composition of augmentations to an image, and minimizes a contrastive loss between the two augmented images. In this paper, we present CLAWS, an annotation-efficient learning framework, addressing the problem of manually labeling large-scale agricultural datasets along with potential applications such as anomaly detection and plant growth analytics. CLAWS uses a network backbone inspired by SimCLR and weak supervision to investigate the effect of contrastive learning within class clusters. In addition, we inject a hard attention mask to the cropped input image before maximizing agreement between the image pairs using a contrastive loss function. This mask forces the network to focus on pertinent object features and ignore background features. We compare results between a supervised SimCLR and CLAWS using an agricultural dataset with 227,060 samples consisting of 11 different crop classes. Our experiments and extensive evaluations show that CLAWS achieves a competitive NMI score of 0.7325. Furthermore, CLAWS engenders the creation of low dimensional representations of very large datasets with minimal parameter tuning and forming well-defined clusters, which lends themselves to using efficient, transparent, and highly interpretable clustering methods such as Gaussian Mixture Models.
Cluster Analysis with Deep Embeddings and Contrastive Learning
Oct 02, 2021
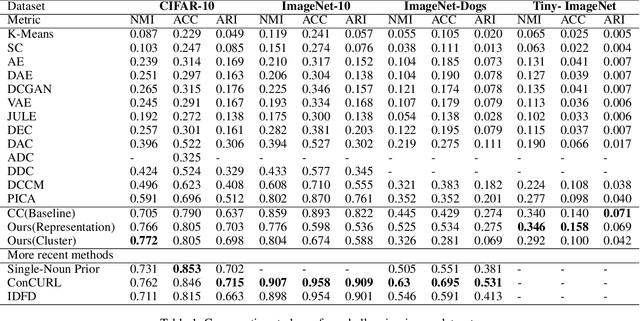


Unsupervised disentangled representation learning is a long-standing problem in computer vision. This work proposes a novel framework for performing image clustering from deep embeddings by combining instance-level contrastive learning with a deep embedding based cluster center predictor. Our approach jointly learns representations and predicts cluster centers in an end-to-end manner. This is accomplished via a three-pronged approach that combines a clustering loss, an instance-wise contrastive loss, and an anchor loss. Our fundamental intuition is that using an ensemble loss that incorporates instance-level features and a clustering procedure focusing on semantic similarity reinforces learning better representations in the latent space. We observe that our method performs exceptionally well on popular vision datasets when evaluated using standard clustering metrics such as Normalized Mutual Information (NMI), in addition to producing geometrically well-separated cluster embeddings as defined by the Euclidean distance. Our framework performs on par with widely accepted clustering methods and outperforms the state-of-the-art contrastive learning method on the CIFAR-10 dataset with an NMI score of 0.772, a 7-8% improvement on the strong baseline.