 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak or Stay Silent: Context-Aware Turn-Taking in Multi-Party Dialogue
Mar 12, 2026Existing voice AI assistants treat every detected pause as an invitation to speak. This works in dyadic dialogue, but in multi-party settings, where an AI assistant participates alongside multiple speakers, pauses are abundant and ambiguous. An assistant that speaks on every pause becomes disruptive rather than useful. In this work, we formulate context-aware turn-taking: at every detected pause, given the full conversation context, our method decides whether the assistant should speak or stay silent. We introduce a benchmark of over 120K labeled conversations spanning three multi-party corpora. Evaluating eight recent large language models, we find that they consistently fail at context-aware turn-taking under zero-shot prompting. We then propose a supervised fine-tuning approach with reasoning traces, improving balanced accuracy by up to 23 percentage points. Our findings suggest that context-aware turn-taking is not an emergent capability; it must be explicitly trained.
Tables to LaTeX: structure and content extraction from scientific tables
Oct 31, 2022Scientific documents contain tables that list important information in a concise fashion. Structure and content extraction from tables embedded within PDF research documents is a very challenging task due to the existence of visual features like spanning cells and content features like mathematical symbols and equations. Most existing table structure identification methods tend to ignore these academic writing features. In this paper, we adapt the transformer-based language modeling paradigm for scientific table structure and content extraction. Specifically, the proposed model converts a tabular image to its corresponding LaTeX source code. Overall, we outperform the current state-of-the-art baselines and achieve an exact match accuracy of 70.35 and 49.69% on table structure and content extraction, respectively. Further analysis demonstrates that the proposed models efficiently identify the number of rows and columns, the alphanumeric characters, the LaTeX tokens, and symbols.
HDRVideo-GAN: Deep Generative HDR Video Reconstruction
Nov 03, 2021


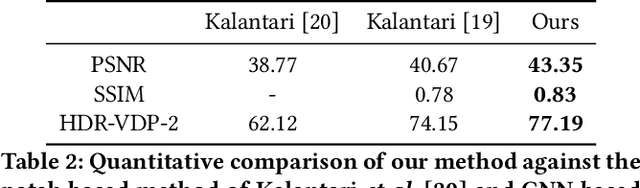
High dynamic range (HDR) videos provide a more visually realistic experience than the standard low dynamic range (LDR) videos. Despite having significant progress in HDR imaging, it is still a challenging task to capture high-quality HDR video with a conventional off-the-shelf camera. Existing approaches rely entirely on using dense optical flow between the neighboring LDR sequences to reconstruct an HDR frame. However, they lead to inconsistencies in color and exposure over time when applied to alternating exposures with noisy frames. In this paper, we propose an end-to-end GAN-based framework for HDR video reconstruction from LDR sequences with alternating exposures. We first extract clean LDR frames from noisy LDR video with alternating exposures with a denoising network trained in a self-supervised setting. Using optical flow, we then align the neighboring alternating-exposure frames to a reference frame and then reconstruct high-quality HDR frames in a complete adversarial setting. To further improve the robustness and quality of generated frames, we incorporate temporal stability-based regularization term along with content and style-based losses in the cost function during the training procedure. Experimental results demonstrate that our framework achieves state-of-the-art performance and generates superior quality HDR frames of a video over the existing methods.
Recent Advancements in Self-Supervised Paradigms for Visual Feature Representation
Nov 03, 2021
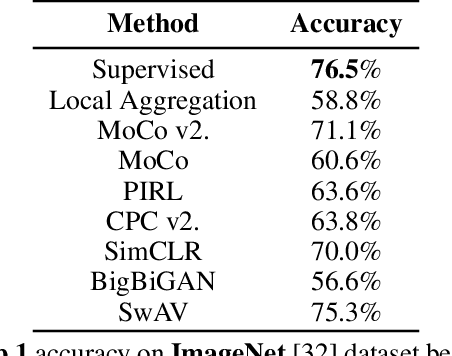
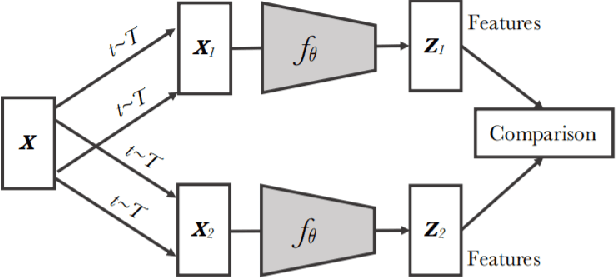
We witnessed a massive growth in the supervised learning paradigm in the past decade. Supervised learning requires a large amount of labeled data to reach state-of-the-art performance. However, labeling the samples requires a lot of human annotation. To avoid the cost of labeling data, self-supervised methods were proposed to make use of largely available unlabeled data. This study conducts a comprehensive and insightful survey and analysis of recent developments in the self-supervised paradigm for feature representation. In this paper, we investigate the factors affecting the usefulness of self-supervision under different settings. We present some of the key insights concerning two different approaches in self-supervision, generative and contrastive methods. We also investigate the limitations of supervised adversarial training and how self-supervision can help overcome those limitations. We then move on to discuss the limitations and challenges in effectively using self-supervision for visual tasks. Finally, we highlight some open problems and point out future research directions.
On Adversarial Robustness of Synthetic Code Generation
Jun 22, 2021
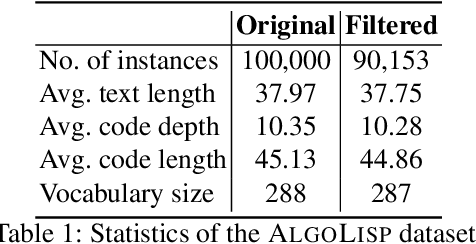
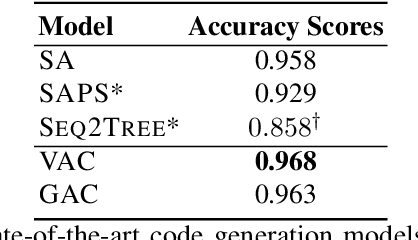
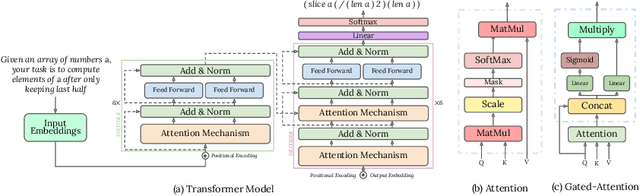
Automatic code synthesis from natural language descriptions is a challenging task. We witness massive progress in developing code generation systems for domain-specific languages (DSLs) employing sequence-to-sequence deep learning techniques in the recent past. In this paper, we specifically experiment with \textsc{AlgoLisp} DSL-based generative models and showcase the existence of significant dataset bias through different classes of adversarial examples. We also experiment with two variants of Transformer-based models that outperform all existing \textsc{AlgoLisp} DSL-based code generation baselines. Consistent with the current state-of-the-art systems, our proposed models, too, achieve poor performance under adversarial settings. Therefore, we propose several dataset augmentation techniques to reduce bias and showcase their efficacy using robust experimentation.
ICDAR 2021 Competition on Scientific Table Image Recognition to LaTeX
May 30, 2021


Tables present important information concisely in many scientific documents. Visual features like mathematical symbols, equations, and spanning cells make structure and content extraction from tables embedded in research documents difficult. This paper discusses the dataset, tasks, participants' methods, and results of the ICDAR 2021 Competition on Scientific Table Image Recognition to LaTeX. Specifically, the task of the competition is to convert a tabular image to its corresponding LaTeX source code. We proposed two subtasks. In Subtask 1, we ask the participants to reconstruct the LaTeX structure code from an image. In Subtask 2, we ask the participants to reconstruct the LaTeX content code from an image. This report describes the datasets and ground truth specification, details the performance evaluation metrics used, presents the final results, and summarizes the participating methods. Submission by team VCGroup got the highest Exact Match accuracy score of 74% for Subtask 1 and 55% for Subtask 2, beating previous baselines by 5% and 12%, respectively. Although improvements can still be made to the recognition capabilities of models, this competition contributes to the development of fully automated table recognition systems by challenging practitioners to solve problems under specific constraints and sharing their approaches; the platform will remain available for post-challenge submissions at https://competitions.codalab.org/competitions/26979 .
* Competition on Scientific Table Image Recognition to LaTeX