 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advancements in Self-Supervised Paradigms for Visual Feature Representation
Paper and Code
Nov 03, 2021
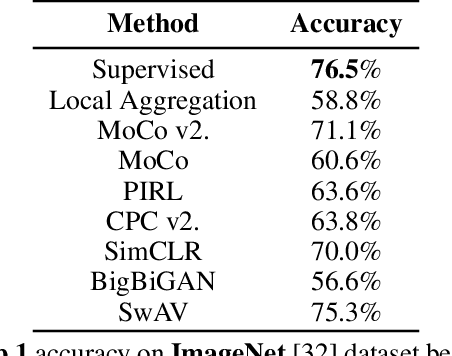
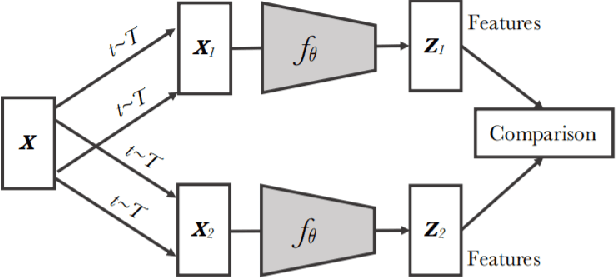
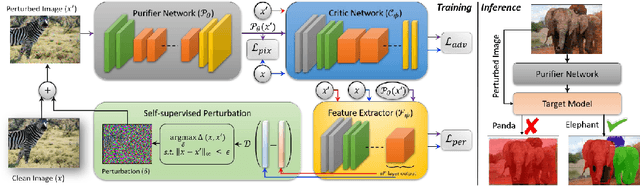
We witnessed a massive growth in the supervised learning paradigm in the past decade. Supervised learning requires a large amount of labeled data to reach state-of-the-art performance. However, labeling the samples requires a lot of human annotation. To avoid the cost of labeling data, self-supervised methods were proposed to make use of largely available unlabeled data. This study conducts a comprehensive and insightful survey and analysis of recent developments in the self-supervised paradigm for feature representation. In this paper, we investigate the factors affecting the usefulness of self-supervision under different settings. We present some of the key insights concerning two different approaches in self-supervision, generative and contrastive methods. We also investigate the limitations of supervised adversarial training and how self-supervision can help overcome those limitations. We then move on to discuss the limitations and challenges in effectively using self-supervision for visual tasks. Finally, we highlight some open problems and point out future research directions.