 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-of-the-art Small Language Coder Model: Mify-Coder
Dec 26, 2025We present Mify-Coder, a 2.5B-parameter code model trained on 4.2T tokens using a compute-optimal strategy built on the Mify-2.5B foundation model. Mify-Coder achieves comparable accuracy and safety while significantly outperforming much larger baseline models on standard coding and function-calling benchmarks, demonstrating that compact models can match frontier-grade models in code generation and agent-driven workflows. Our training pipeline combines high-quality curated sources with synthetic data generated through agentically designed prompts, refined iteratively using enterprise-grade evaluation datasets. LLM-based quality filtering further enhances data density, enabling frugal yet effective training. Through disciplined exploration of CPT-SFT objectives, data mixtures, and sampling dynamics, we deliver frontier-grade code intelligence within a single continuous training trajectory. Empirical evidence shows that principled data and compute discipline allow smaller models to achieve competitive accuracy, efficiency, and safety compliance. Quantized variants of Mify-Coder enable deployment on standard desktop environments without requiring specialized hardware.
Persuasion Strategies in Advertisements: Dataset, Modeling, and Baselines
Aug 20, 2022
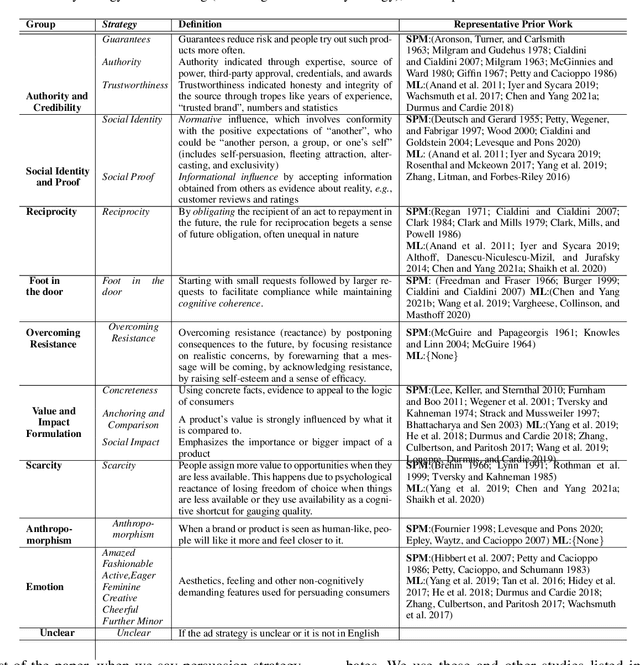
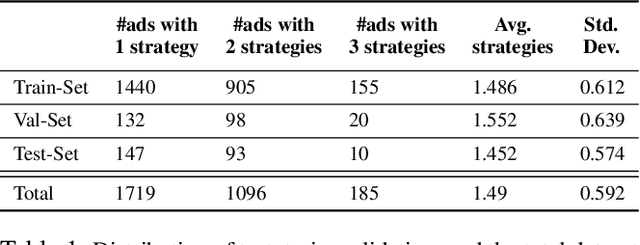

Modeling what makes an advertisement persuasive, i.e., eliciting the desired response from consumer, is critical to the study of propaganda, social psychology, and marketing. Despite its importance, computational modeling of persuasion in computer vision is still in its infancy, primarily due to the lack of benchmark datasets that can provide persuasion-strategy labels associated with ads. Motivated by persuasion literature in social psychology and marketing, we introduce an extensive vocabulary of persuasion strategies and build the first ad image corpus annotated with persuasion strategies. We then formulate the task of persuasion strategy prediction with multi-modal learning, where we design a multi-task attention fusion model that can leverage other ad-understanding tasks to predict persuasion strategies. Further, we conduct a real-world case study on 1600 advertising campaigns of 30 Fortune-500 companies where we use our model's predictions to analyze which strategies work with different demographics (age and gender). The dataset also provides image segmentation masks, which labels persuasion strategies in the corresponding ad images on the test split. We publicly release our code and dataset https://midas-research.github.io/persuasion-advertisements/.
Recent Advancements in Self-Supervised Paradigms for Visual Feature Representation
Nov 03, 2021
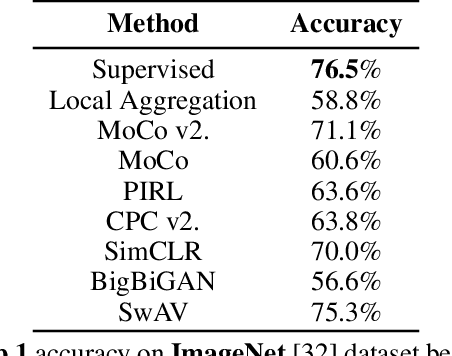
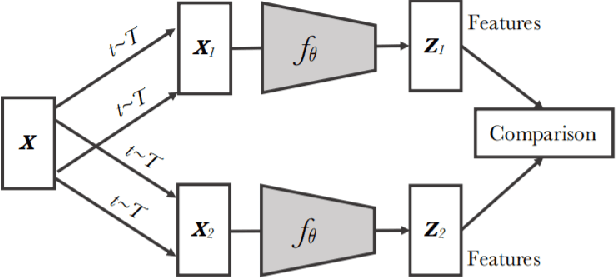
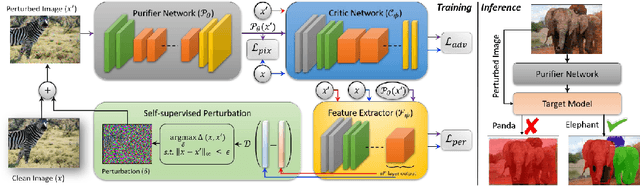
We witnessed a massive growth in the supervised learning paradigm in the past decade. Supervised learning requires a large amount of labeled data to reach state-of-the-art performance. However, labeling the samples requires a lot of human annotation. To avoid the cost of labeling data, self-supervised methods were proposed to make use of largely available unlabeled data. This study conducts a comprehensive and insightful survey and analysis of recent developments in the self-supervised paradigm for feature representation. In this paper, we investigate the factors affecting the usefulness of self-supervision under different settings. We present some of the key insights concerning two different approaches in self-supervision, generative and contrastive methods. We also investigate the limitations of supervised adversarial training and how self-supervision can help overcome those limitations. We then move on to discuss the limitations and challenges in effectively using self-supervision for visual tasks. Finally, we highlight some open problems and point out future research directions.