 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNirjas: An open source framework for extracting metadata from the source code
Sep 22, 2024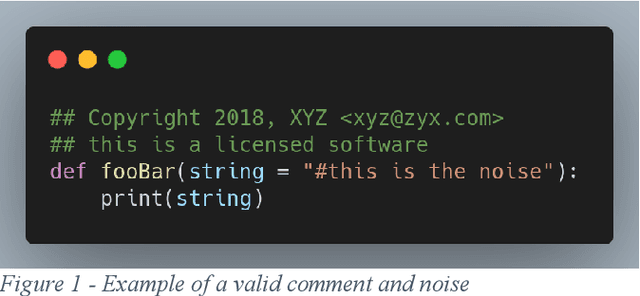
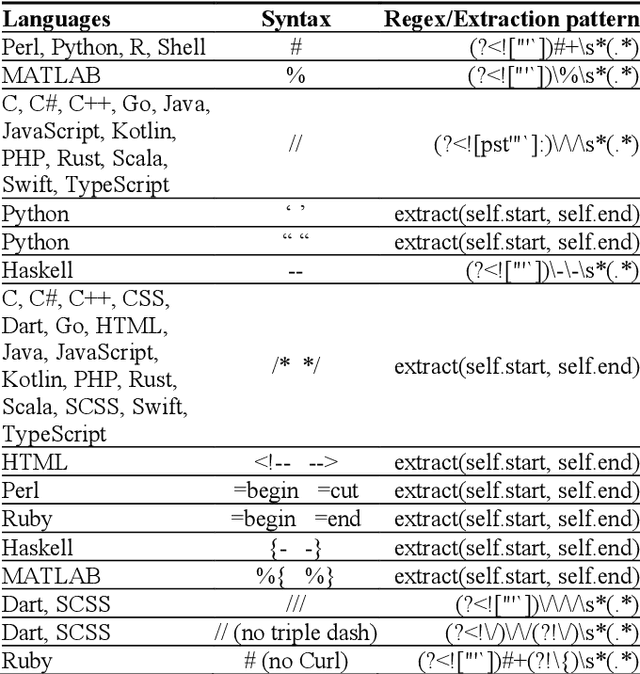
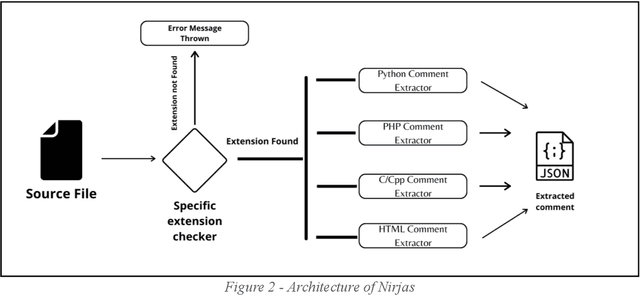
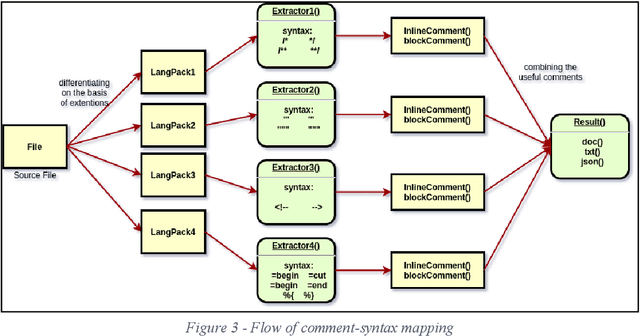
Metadata and comments are critical elements of any software development process. In this paper, we explain how metadata and comments in source code can play an essential role in comprehending software. We introduce a Python-based open-source framework, Nirjas, which helps in extracting this metadata in a structured manner. Various syntaxes, types, and widely accepted conventions exist for adding comments in source files of different programming languages. Edge cases can create noise in extraction, for which we use Regex to accurately retrieve metadata. Non-Regex methods can give results but often miss accuracy and noise separation. Nirjas also separates different types of comments, source code, and provides details about those comments, such as line number, file name, language used, total SLOC, etc. Nirjas is a standalone Python framework/library and can be easily installed via source or pip (the Python package installer). Nirjas was initially created as part of a Google Summer of Code project and is currently developed and maintained under the FOSSology organization.
Persuasion Strategies in Advertisements: Dataset, Modeling, and Baselines
Aug 20, 2022
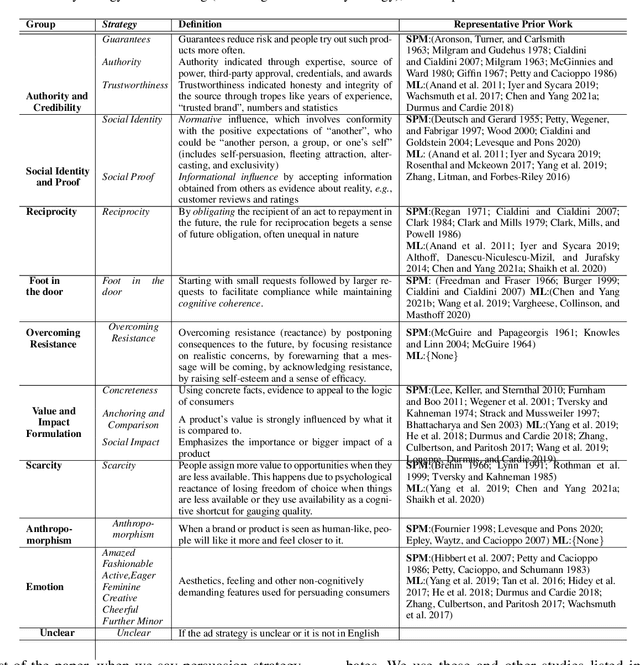
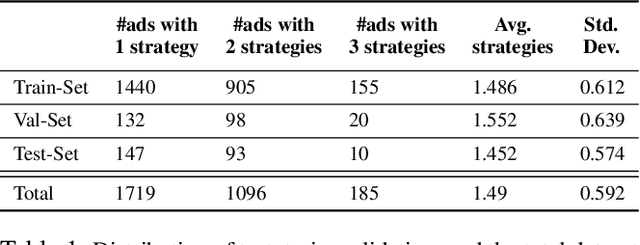

Modeling what makes an advertisement persuasive, i.e., eliciting the desired response from consumer, is critical to the study of propaganda, social psychology, and marketing. Despite its importance, computational modeling of persuasion in computer vision is still in its infancy, primarily due to the lack of benchmark datasets that can provide persuasion-strategy labels associated with ads. Motivated by persuasion literature in social psychology and marketing, we introduce an extensive vocabulary of persuasion strategies and build the first ad image corpus annotated with persuasion strategies. We then formulate the task of persuasion strategy prediction with multi-modal learning, where we design a multi-task attention fusion model that can leverage other ad-understanding tasks to predict persuasion strategies. Further, we conduct a real-world case study on 1600 advertising campaigns of 30 Fortune-500 companies where we use our model's predictions to analyze which strategies work with different demographics (age and gender). The dataset also provides image segmentation masks, which labels persuasion strategies in the corresponding ad images on the test split. We publicly release our code and dataset https://midas-research.github.io/persuasion-advertisements/.
Empowering Knowledge Distillation via Open Set Recognition for Robust 3D Point Cloud Classification
Oct 25, 2020
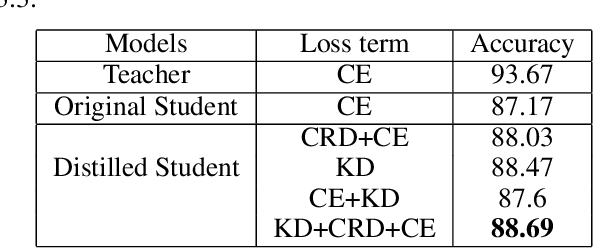
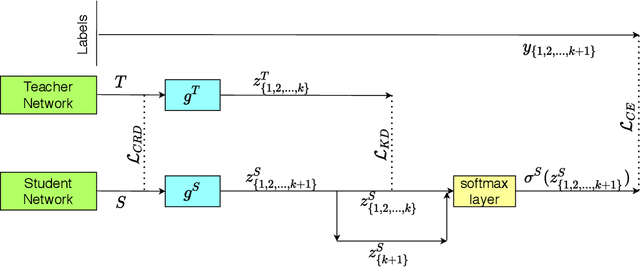

Real-world scenarios pose several challenges to deep learning based computer vision techniques despite their tremendous success in research. Deeper models provide better performance, but are challenging to deploy and knowledge distillation allows us to train smaller models with minimal loss in performance. The model also has to deal with open set samples from classes outside the ones it was trained on and should be able to identify them as unknown samples while classifying the known ones correctly. Finally, most existing image recognition research focuses only on using two-dimensional snapshots of the real world three-dimensional objects. In this work, we aim to bridge these three research fields, which have been developed independently until now, despite being deeply interrelated. We propose a joint Knowledge Distillation and Open Set recognition training methodology for three-dimensional object recognition. We demonstrate the effectiveness of the proposed method via various experiments on how it allows us to obtain a much smaller model, which takes a minimal hit in performance while being capable of open set recognition for 3D point cloud data.
Domain Aware Markov Logic Networks
Jul 07, 2018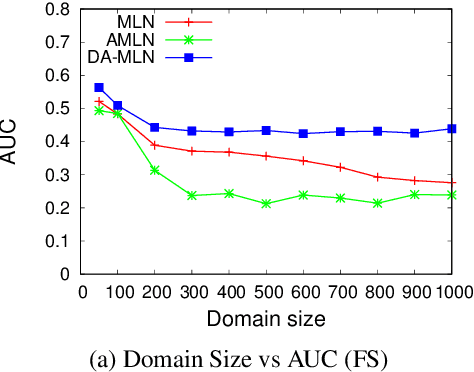
Combining logic and probability has been a long stand- ing goal of AI research. Markov Logic Networks (MLNs) achieve this by attaching weights to formulas in first-order logic, and can be seen as templates for constructing features for ground Markov networks. Most techniques for learning weights of MLNs are domain-size agnostic, i.e., the size of the domain is not explicitly taken into account while learn- ing the parameters of the model. This often results in ex- treme probabilities when testing on domain sizes different from those seen during training. In this paper, we propose Domain Aware Markov logic Networks (DA-MLNs) which present a principled solution to this problem. While defin- ing the ground network distribution, DA-MLNs divide the ground feature weight by a scaling factor which is a function of the number of connections the ground atoms appearing in the feature are involved in. We show that standard MLNs fall out as a special case of our formalism when this func- tion evaluates to a constant equal to 1. Experiments on the benchmark Friends & Smokers domain show that our ap- proach results in significantly higher accuracies compared to existing methods when testing on domains whose sizes different from those seen during training.