 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Adversarial Robustness of Synthetic Code Generation
Paper and Code

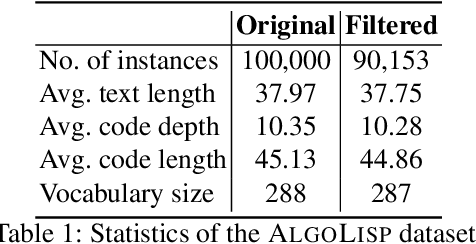
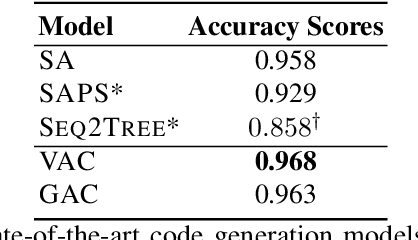
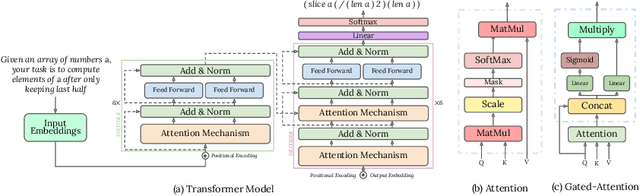
Automatic code synthesis from natural language descriptions is a challenging task. We witness massive progress in developing code generation systems for domain-specific languages (DSLs) employing sequence-to-sequence deep learning techniques in the recent past. In this paper, we specifically experiment with \textsc{AlgoLisp} DSL-based generative models and showcase the existence of significant dataset bias through different classes of adversarial examples. We also experiment with two variants of Transformer-based models that outperform all existing \textsc{AlgoLisp} DSL-based code generation baselines. Consistent with the current state-of-the-art systems, our proposed models, too, achieve poor performance under adversarial settings. Therefore, we propose several dataset augmentation techniques to reduce bias and showcase their efficacy using robust experimentation.