 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.R.I.S.: Automated Recycling Identification System for E-Waste Classification Using Deep Learning
Feb 19, 2026Traditional electronic recycling processes suffer from significant resource loss due to inadequate material separation and identification capabilities, limiting material recovery. We present A.R.I.S. (Automated Recycling Identification System), a low-cost, portable sorter for shredded e-waste that addresses this efficiency gap. The system employs a YOLOx model to classify metals, plastics, and circuit boards in real time, achieving low inference latency with high detection accuracy. Experimental evaluation yielded 90% overall precision, 82.2% mean average precision (mAP), and 84% sortation purity. By integrating deep learning with established sorting methods, A.R.I.S. enhances material recovery efficiency and lowers barriers to advanced recycling adoption. This work complements broader initiatives in extending product life cycles, supporting trade-in and recycling programs, and reducing environmental impact across the supply chain.
Tables to LaTeX: structure and content extraction from scientific tables
Oct 31, 2022Scientific documents contain tables that list important information in a concise fashion. Structure and content extraction from tables embedded within PDF research documents is a very challenging task due to the existence of visual features like spanning cells and content features like mathematical symbols and equations. Most existing table structure identification methods tend to ignore these academic writing features. In this paper, we adapt the transformer-based language modeling paradigm for scientific table structure and content extraction. Specifically, the proposed model converts a tabular image to its corresponding LaTeX source code. Overall, we outperform the current state-of-the-art baselines and achieve an exact match accuracy of 70.35 and 49.69% on table structure and content extraction, respectively. Further analysis demonstrates that the proposed models efficiently identify the number of rows and columns, the alphanumeric characters, the LaTeX tokens, and symbols.
ICDAR 2021 Competition on Scientific Table Image Recognition to LaTeX
May 30, 2021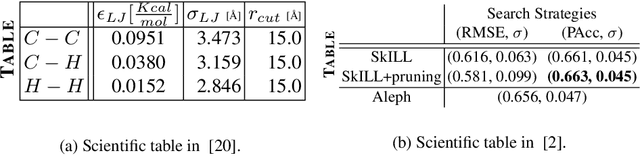


Tables present important information concisely in many scientific documents. Visual features like mathematical symbols, equations, and spanning cells make structure and content extraction from tables embedded in research documents difficult. This paper discusses the dataset, tasks, participants' methods, and results of the ICDAR 2021 Competition on Scientific Table Image Recognition to LaTeX. Specifically, the task of the competition is to convert a tabular image to its corresponding LaTeX source code. We proposed two subtasks. In Subtask 1, we ask the participants to reconstruct the LaTeX structure code from an image. In Subtask 2, we ask the participants to reconstruct the LaTeX content code from an image. This report describes the datasets and ground truth specification, details the performance evaluation metrics used, presents the final results, and summarizes the participating methods. Submission by team VCGroup got the highest Exact Match accuracy score of 74% for Subtask 1 and 55% for Subtask 2, beating previous baselines by 5% and 12%, respectively. Although improvements can still be made to the recognition capabilities of models, this competition contributes to the development of fully automated table recognition systems by challenging practitioners to solve problems under specific constraints and sharing their approaches; the platform will remain available for post-challenge submissions at https://competitions.codalab.org/competitions/26979 .
* Competition on Scientific Table Image Recognition to LaTeX
TabLeX: A Benchmark Dataset for Structure and Content Information Extraction from Scientific Tables
May 12, 2021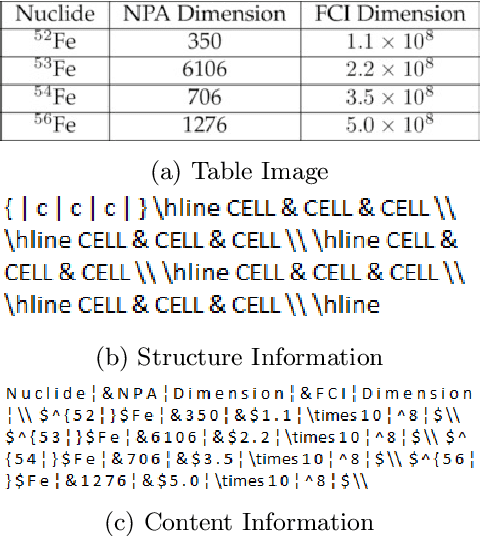
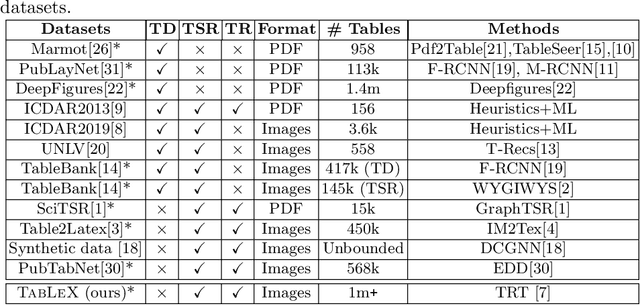
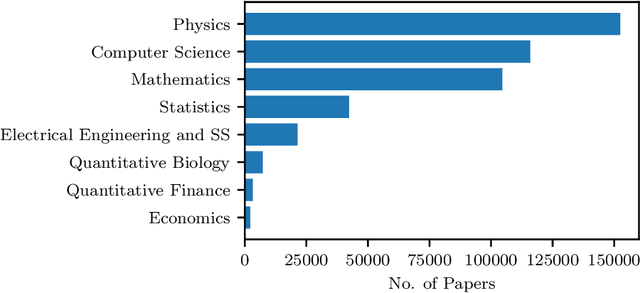
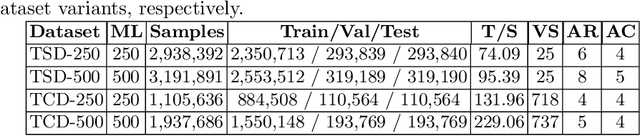
Information Extraction (IE) from the tables present in scientific articles is challenging due to complicated tabular representations and complex embedded text. This paper presents TabLeX, a large-scale benchmark dataset comprising table images generated from scientific articles. TabLeX consists of two subsets, one for table structure extraction and the other for table content extraction. Each table image is accompanied by its corresponding LATEX source code. To facilitate the development of robust table IE tools, TabLeX contains images in different aspect ratios and in a variety of fonts. Our analysis sheds light on the shortcomings of current state-of-the-art table extraction models and shows that they fail on even simple table images. Towards the end, we experiment with a transformer-based existing baseline to report performance scores. In contrast to the static benchmarks, we plan to augment this dataset with more complex and diverse tables at regular intervals.