 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabLeX: A Benchmark Dataset for Structure and Content Information Extraction from Scientific Tables
Paper and Code
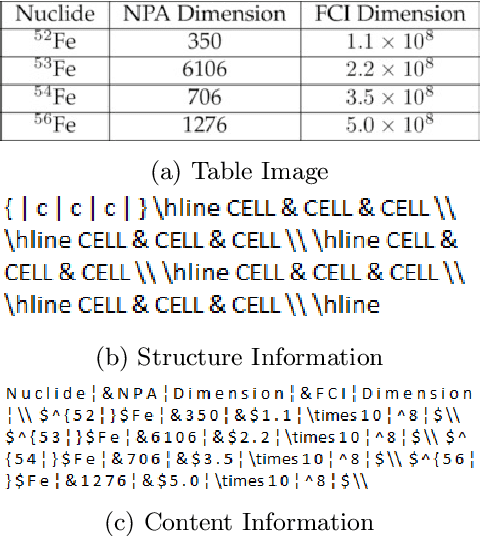
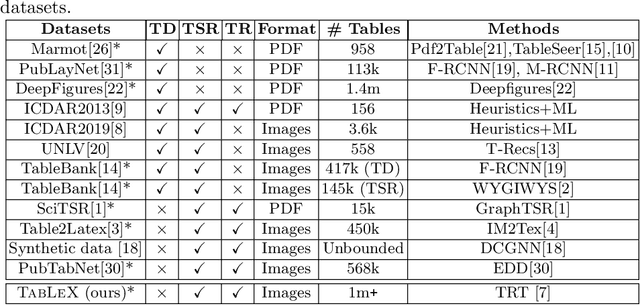
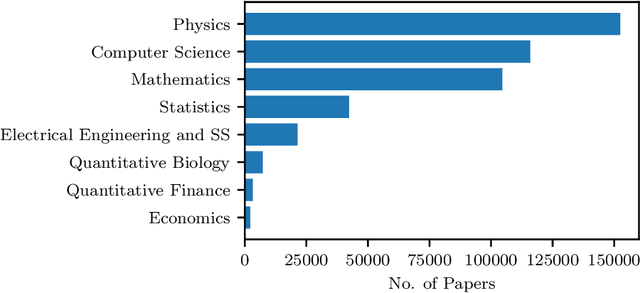
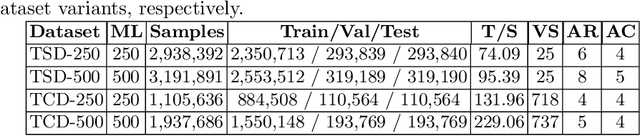
Information Extraction (IE) from the tables present in scientific articles is challenging due to complicated tabular representations and complex embedded text. This paper presents TabLeX, a large-scale benchmark dataset comprising table images generated from scientific articles. TabLeX consists of two subsets, one for table structure extraction and the other for table content extraction. Each table image is accompanied by its corresponding LATEX source code. To facilitate the development of robust table IE tools, TabLeX contains images in different aspect ratios and in a variety of fonts. Our analysis sheds light on the shortcomings of current state-of-the-art table extraction models and shows that they fail on even simple table images. Towards the end, we experiment with a transformer-based existing baseline to report performance scores. In contrast to the static benchmarks, we plan to augment this dataset with more complex and diverse tables at regular intervals.