 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSONYC-UST-V2: An Urban Sound Tagging Dataset with Spatiotemporal Context
Sep 11, 2020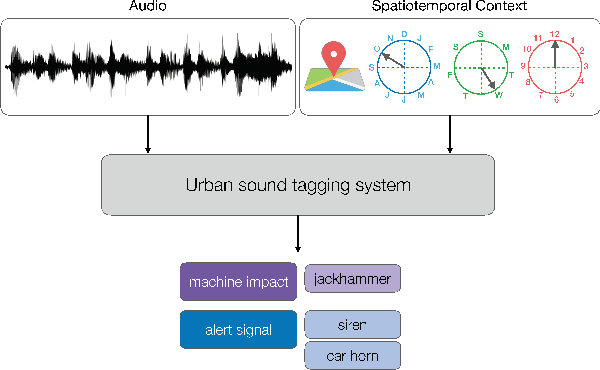
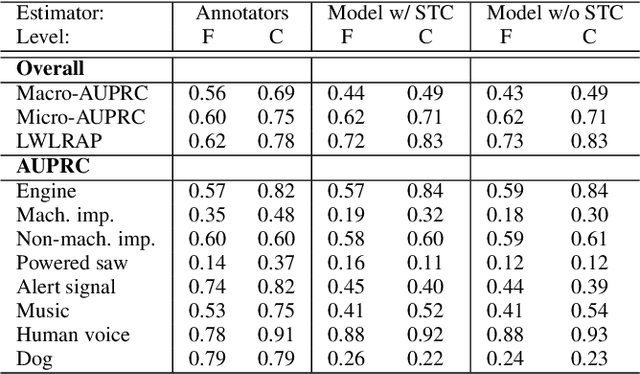
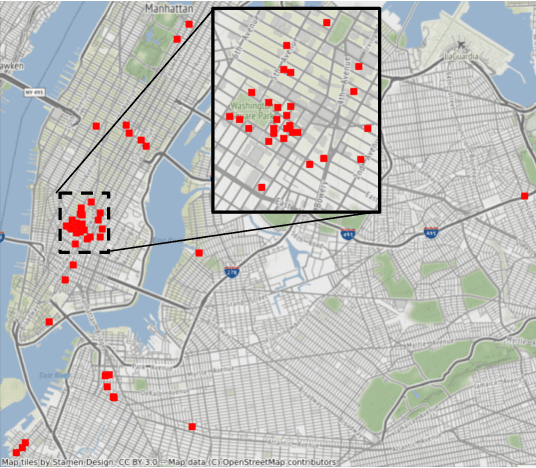
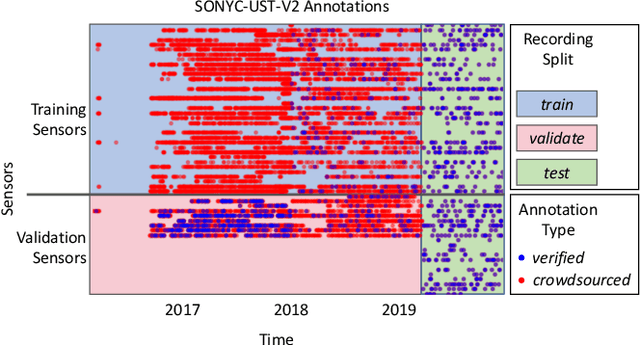
We present SONYC-UST-V2, a dataset for urban sound tagging with spatiotemporal information. This dataset is aimed for the development and evaluation of machine listening systems for real-world urban noise monitoring. While datasets of urban recordings are available, this dataset provides the opportunity to investigate how spatiotemporal metadata can aid in the prediction of urban sound tags. SONYC-UST-V2 consists of 18510 audio recordings from the "Sounds of New York City" (SONYC) acoustic sensor network, including the timestamp of audio acquisition and location of the sensor. The dataset contains annotations by volunteers from the Zooniverse citizen science platform, as well as a two-stage verification with our team. In this article, we describe our data collection procedure and propose evaluation metrics for multilabel classification of urban sound tags. We report the results of a simple baseline model that exploits spatiotemporal information.
Multi-label Sound Event Retrieval Using a Deep Learning-based Siamese Structure with a Pairwise Presence Matrix
Feb 20, 2020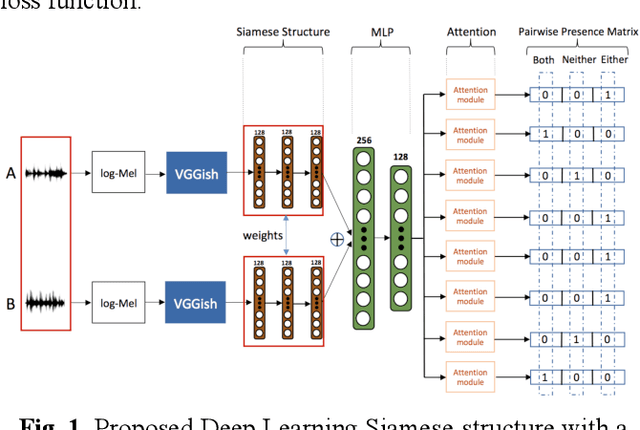
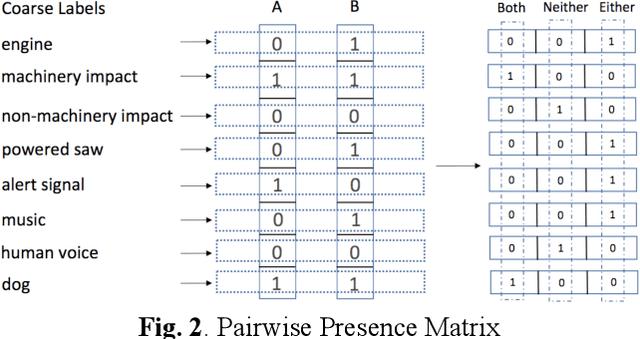
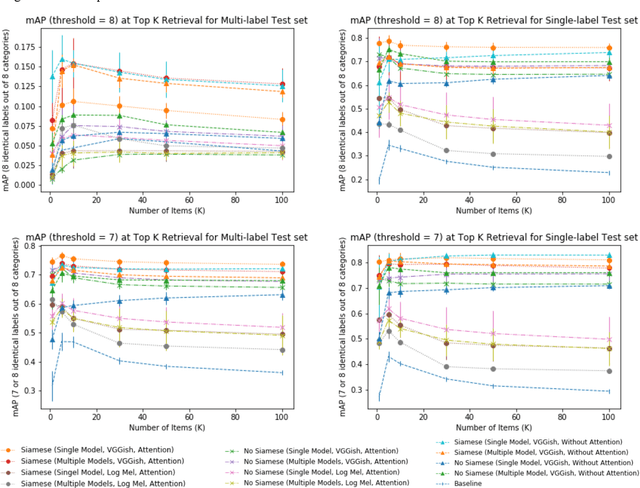
Realistic recordings of soundscapes often have multiple sound events co-occurring, such as car horns, engine and human voices. Sound event retrieval is a type of content-based search aiming at finding audio samples, similar to an audio query based on their acoustic or semantic content. State of the art sound event retrieval models have focused on single-label audio recordings, with only one sound event occurring, rather than on multi-label audio recordings (i.e., multiple sound events occur in one recording). To address this latter problem, we propose different Deep Learning architectures with a Siamese-structure and a Pairwise Presence Matrix. The networks are trained and evaluated using the SONYC-UST dataset containing both single- and multi-label soundscape recordings. The performance results show the effectiveness of our proposed model.