 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Range Characterization of Open Text-to-Audio Models
Oct 31, 2025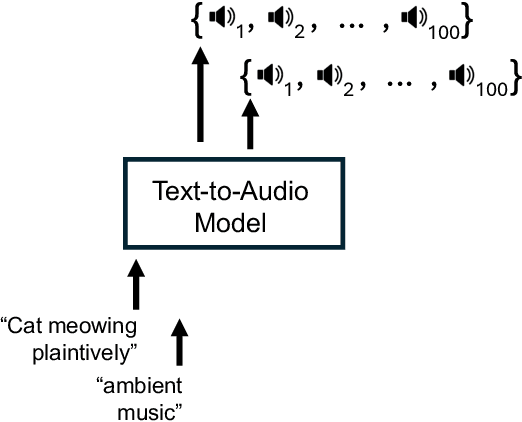
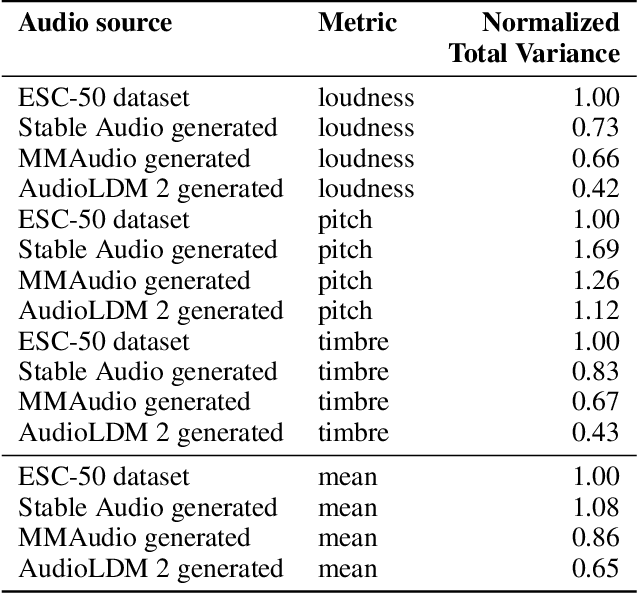
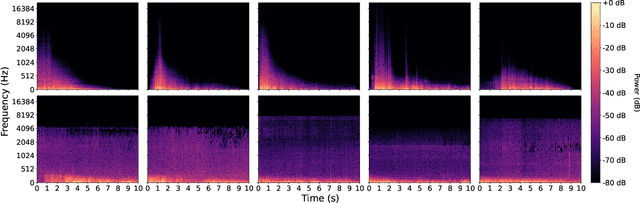
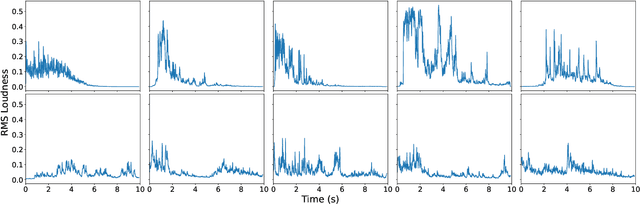
Text-to-audio models are a type of generative model that produces audio output in response to a given textual prompt. Although level generators and the properties of the functional content that they create (e.g., playability) dominate most discourse in procedurally generated content (PCG), games that emotionally resonate with players tend to weave together a range of creative and multimodal content (e.g., music, sounds, visuals, narrative tone), and multimodal models have begun seeing at least experimental use for this purpose. However, it remains unclear what exactly such models generate, and with what degree of variability and fidelity: audio is an extremely broad class of output for a generative system to target. Within the PCG community, expressive range analysis (ERA) has been used as a quantitative way to characterize generators' output space, especially for level generators. This paper adapts ERA to text-to-audio models, making the analysis tractable by looking at the expressive range of outputs for specific, fixed prompts. Experiments are conducted by prompting the models with several standardized prompts derived from the Environmental Sound Classification (ESC-50) dataset. The resulting audio is analyzed along key acoustic dimensions (e.g., pitch, loudness, and timbre). More broadly, this paper offers a framework for ERA-based exploratory evaluation of generative audio models.
EmotionCaps: Enhancing Audio Captioning Through Emotion-Augmented Data Generation
Oct 15, 2024



Recent progress in audio-language modeling, such as automated audio captioning, has benefited from training on synthetic data generated with the aid of large-language models. However, such approaches for environmental sound captioning have primarily focused on audio event tags and have not explored leveraging emotional information that may be present in recordings. In this work, we explore the benefit of generating emotion-augmented synthetic audio caption data by instructing ChatGPT with additional acoustic information in the form of estimated soundscape emotion. To do so, we introduce EmotionCaps, an audio captioning dataset comprised of approximately 120,000 audio clips with paired synthetic descriptions enriched with soundscape emotion recognition (SER) information. We hypothesize that this additional information will result in higher-quality captions that match the emotional tone of the audio recording, which will, in turn, improve the performance of captioning models trained with this data. We test this hypothesis through both objective and subjective evaluation, comparing models trained with the EmotionCaps dataset to multiple baseline models. Our findings challenge current approaches to captioning and suggest new directions for developing and assessing captioning models.
Compositional Audio Representation Learning
Sep 15, 2024



Human auditory perception is compositional in nature -- we identify auditory streams from auditory scenes with multiple sound events. However, such auditory scenes are typically represented using clip-level representations that do not disentangle the constituent sound sources. In this work, we learn source-centric audio representations where each sound source is represented using a distinct, disentangled source embedding in the audio representation. We propose two novel approaches to learning source-centric audio representations: a supervised model guided by classification and an unsupervised model guided by feature reconstruction, both of which outperform the baselines. We thoroughly evaluate the design choices of both approaches using an audio classification task. We find that supervision is beneficial to learn source-centric representations, and that reconstructing audio features is more useful than reconstructing spectrograms to learn unsupervised source-centric representations. Leveraging source-centric models can help unlock the potential of greater interpretability and more flexible decoding in machine listening.
Multi-label Open-set Audio Classification
Oct 20, 2023



Current audio classification models have small class vocabularies relative to the large number of sound event classes of interest in the real world. Thus, they provide a limited view of the world that may miss important yet unexpected or unknown sound events. To address this issue, open-set audio classification techniques have been developed to detect sound events from unknown classes. Although these methods have been applied to a multi-class context in audio, such as sound scene classification, they have yet to be investigated for polyphonic audio in which sound events overlap, requiring the use of multi-label models. In this study, we establish the problem of multi-label open-set audio classification by creating a dataset with varying unknown class distributions and evaluating baseline approaches built upon existing techniques.
A General Framework for Learning Procedural Audio Models of Environmental Sounds
Mar 04, 2023This paper introduces the Procedural (audio) Variational autoEncoder (ProVE) framework as a general approach to learning Procedural Audio PA models of environmental sounds with an improvement to the realism of the synthesis while maintaining provision of control over the generated sound through adjustable parameters. The framework comprises two stages: (i) Audio Class Representation, in which a latent representation space is defined by training an audio autoencoder, and (ii) Control Mapping, in which a joint function of static/temporal control variables derived from the audio and a random sample of uniform noise is learned to replace the audio encoder. We demonstrate the use of ProVE through the example of footstep sound effects on various surfaces. Our results show that ProVE models outperform both classical PA models and an adversarial-based approach in terms of sound fidelity, as measured by Fr\'echet Audio Distance (FAD), Maximum Mean Discrepancy (MMD), and subjective evaluations, making them feasible tools for sound design workflows.
Urban Rhapsody: Large-scale exploration of urban soundscapes
May 25, 2022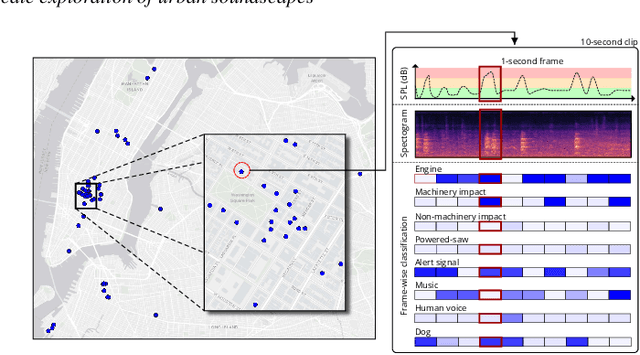
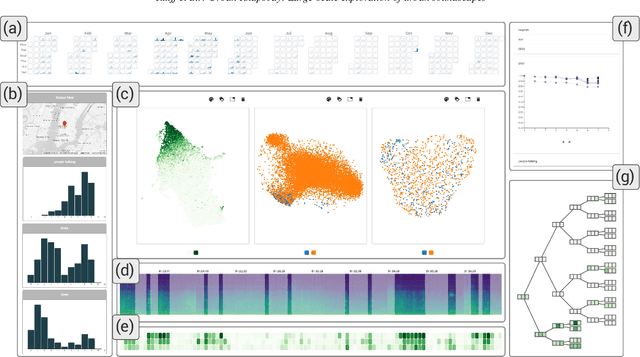
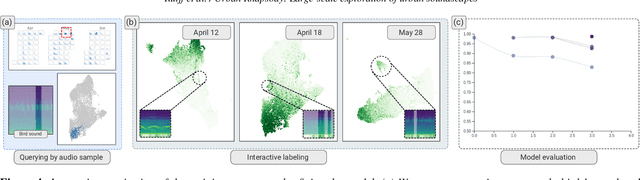
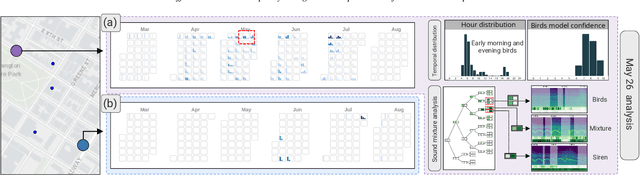
Noise is one of the primary quality-of-life issues in urban environments. In addition to annoyance, noise negatively impacts public health and educational performance. While low-cost sensors can be deployed to monitor ambient noise levels at high temporal resolutions, the amount of data they produce and the complexity of these data pose significant analytical challenges. One way to address these challenges is through machine listening techniques, which are used to extract features in attempts to classify the source of noise and understand temporal patterns of a city's noise situation. However, the overwhelming number of noise sources in the urban environment and the scarcity of labeled data makes it nearly impossible to create classification models with large enough vocabularies that capture the true dynamism of urban soundscapes In this paper, we first identify a set of requirements in the yet unexplored domain of urban soundscape exploration. To satisfy the requirements and tackle the identified challenges, we propose Urban Rhapsody, a framework that combines state-of-the-art audio representation, machine learning, and visual analytics to allow users to interactively create classification models, understand noise patterns of a city, and quickly retrieve and label audio excerpts in order to create a large high-precision annotated database of urban sound recordings. We demonstrate the tool's utility through case studies performed by domain experts using data generated over the five-year deployment of a one-of-a-kind sensor network in New York City.
A Study on Robustness to Perturbations for Representations of Environmental Sound
Mar 23, 2022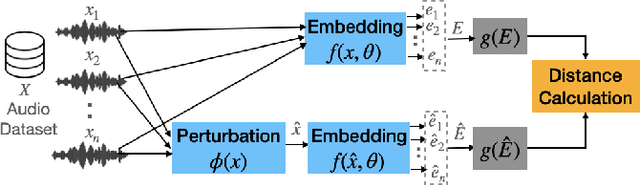
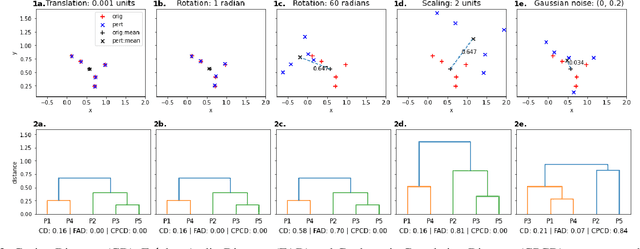
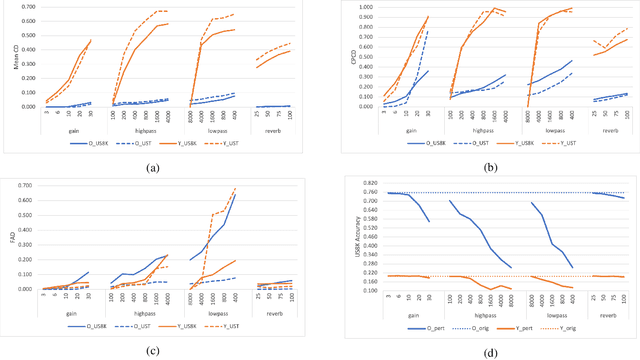
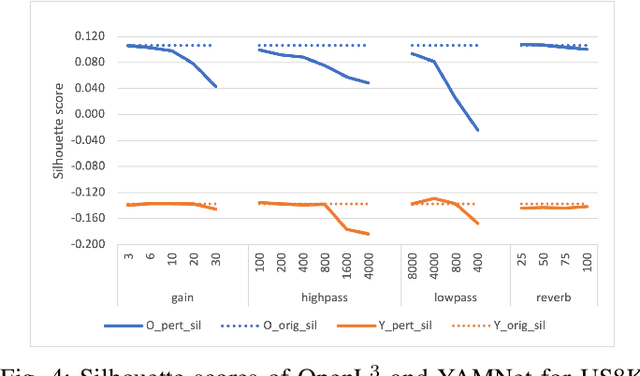
Audio applications involving environmental sound analysis increasingly use general-purpose audio representations, also known as embeddings, for transfer learning. Recently, Holistic Evaluation of Audio Representations (HEAR) evaluated twenty-nine embedding models on nineteen diverse tasks. However, the evaluation's effectiveness depends on the variation already captured within a given dataset. Therefore, for a given data domain, it is unclear how the representations would be affected by the variations caused by myriad microphones' range and acoustic conditions -- commonly known as channel effects. We aim to extend HEAR to evaluate invariance to channel effects in this work. To accomplish this, we imitate channel effects by injecting perturbations to the audio signal and measure the shift in the new (perturbed) embeddings with three distance measures, making the evaluation domain-dependent but not task-dependent. Combined with the downstream performance, it helps us make a more informed prediction of how robust the embeddings are to the channel effects. We evaluate two embeddings -- YAMNet, and OpenL$^3$ on monophonic (UrbanSound8K) and polyphonic (SONYC UST) datasets. We show that one distance measure does not suffice in such task-independent evaluation. Although Fr\'echet Audio Distance (FAD) correlates with the trend of the performance drop in the downstream task most accurately, we show that we need to study this in conjunction with the other distances to get a clear understanding of the overall effect of the perturbation. In terms of the embedding performance, we find OpenL$^3$ to be more robust to YAMNet, which aligns with the HEAR evaluation.
Who calls the shots? Rethinking Few-Shot Learning for Audio
Oct 18, 2021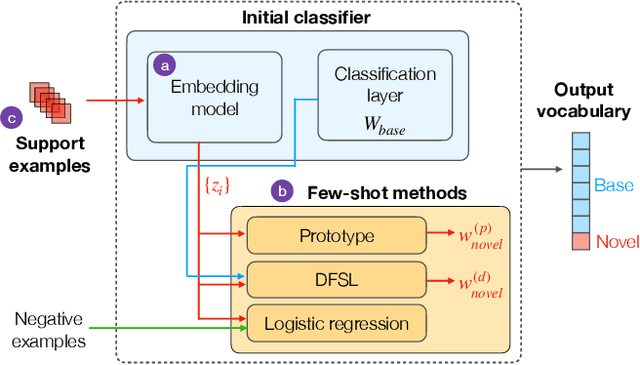
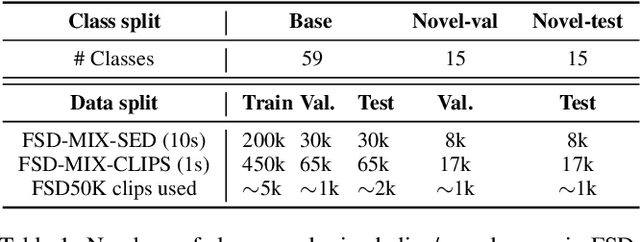
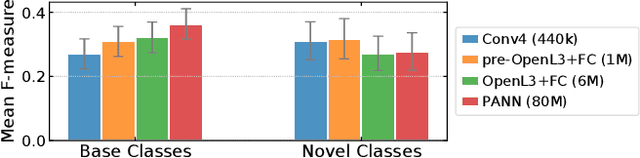
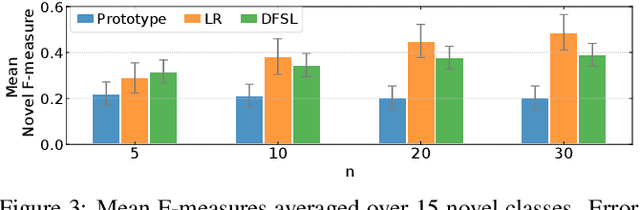
Few-shot learning aims to train models that can recognize novel classes given just a handful of labeled examples, known as the support set. While the field has seen notable advances in recent years, they have often focused on multi-class image classification. Audio, in contrast, is often multi-label due to overlapping sounds, resulting in unique properties such as polyphony and signal-to-noise ratios (SNR). This leads to unanswered questions concerning the impact such audio properties may have on few-shot learning system design, performance, and human-computer interaction, as it is typically up to the user to collect and provide inference-time support set examples. We address these questions through a series of experiments designed to elucidate the answers to these questions. We introduce two novel datasets, FSD-MIX-CLIPS and FSD-MIX-SED, whose programmatic generation allows us to explore these questions systematically. Our experiments lead to audio-specific insights on few-shot learning, some of which are at odds with recent findings in the image domain: there is no best one-size-fits-all model, method, and support set selection criterion. Rather, it depends on the expected application scenario. Our code and data are available at https://github.com/wangyu/rethink-audio-fsl.
Weakly Supervised Source-Specific Sound Level Estimation in Noisy Soundscapes
May 06, 2021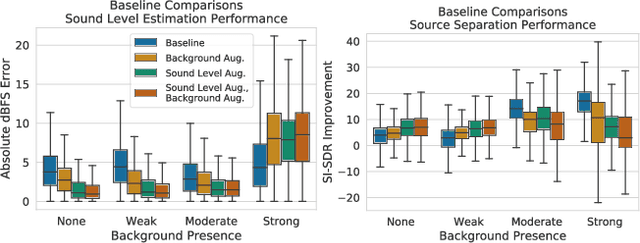
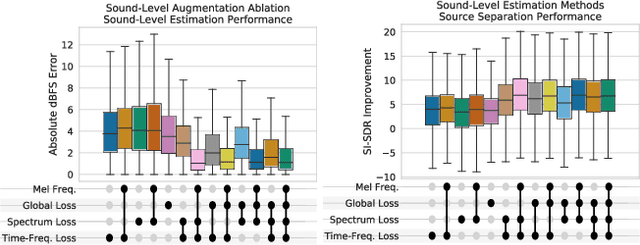
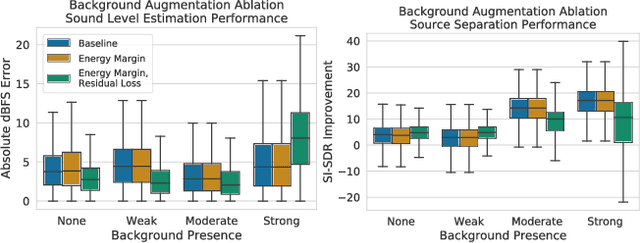
While the estimation of what sound sources are, when they occur, and from where they originate has been well-studied, the estimation of how loud these sound sources are has been often overlooked. Current solutions to this task, which we refer to as source-specific sound level estimation (SSSLE), suffer from challenges due to the impracticality of acquiring realistic data and a lack of robustness to realistic recording conditions. Recently proposed weakly supervised source separation offer a means of leveraging clip-level source annotations to train source separation models, which we augment with modified loss functions to bridge the gap between source separation and SSSLE and to address the presence of background. We show that our approach improves SSSLE performance compared to baseline source separation models and provide an ablation analysis to explore our method's design choices, showing that SSSLE in practical recording and annotation scenarios is possible.
SONYC-UST-V2: An Urban Sound Tagging Dataset with Spatiotemporal Context
Sep 11, 2020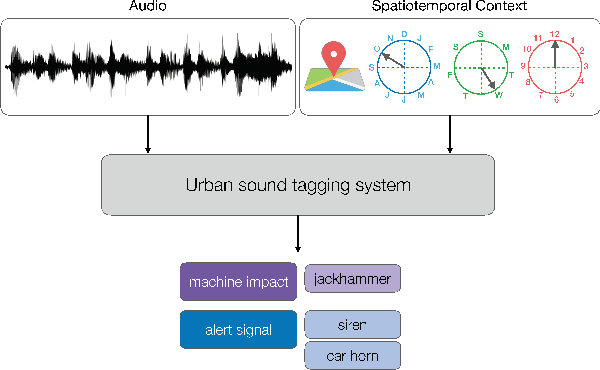
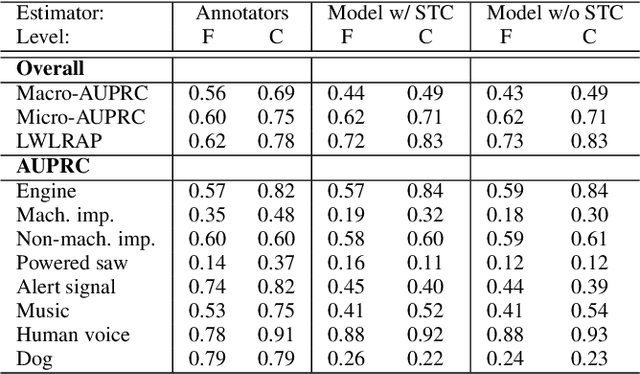
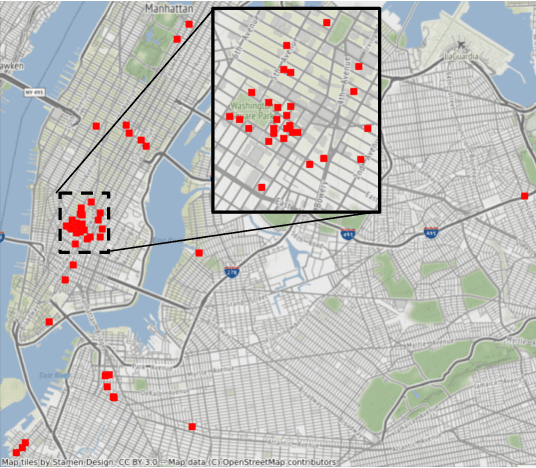
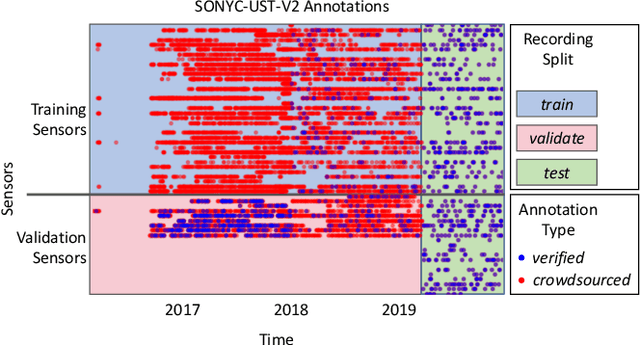
We present SONYC-UST-V2, a dataset for urban sound tagging with spatiotemporal information. This dataset is aimed for the development and evaluation of machine listening systems for real-world urban noise monitoring. While datasets of urban recordings are available, this dataset provides the opportunity to investigate how spatiotemporal metadata can aid in the prediction of urban sound tags. SONYC-UST-V2 consists of 18510 audio recordings from the "Sounds of New York City" (SONYC) acoustic sensor network, including the timestamp of audio acquisition and location of the sensor. The dataset contains annotations by volunteers from the Zooniverse citizen science platform, as well as a two-stage verification with our team. In this article, we describe our data collection procedure and propose evaluation metrics for multilabel classification of urban sound tags. We report the results of a simple baseline model that exploits spatiotemporal information.