 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Audio Representation Learning
Sep 15, 2024



Human auditory perception is compositional in nature -- we identify auditory streams from auditory scenes with multiple sound events. However, such auditory scenes are typically represented using clip-level representations that do not disentangle the constituent sound sources. In this work, we learn source-centric audio representations where each sound source is represented using a distinct, disentangled source embedding in the audio representation. We propose two novel approaches to learning source-centric audio representations: a supervised model guided by classification and an unsupervised model guided by feature reconstruction, both of which outperform the baselines. We thoroughly evaluate the design choices of both approaches using an audio classification task. We find that supervision is beneficial to learn source-centric representations, and that reconstructing audio features is more useful than reconstructing spectrograms to learn unsupervised source-centric representations. Leveraging source-centric models can help unlock the potential of greater interpretability and more flexible decoding in machine listening.
Multi-label Open-set Audio Classification
Oct 20, 2023



Current audio classification models have small class vocabularies relative to the large number of sound event classes of interest in the real world. Thus, they provide a limited view of the world that may miss important yet unexpected or unknown sound events. To address this issue, open-set audio classification techniques have been developed to detect sound events from unknown classes. Although these methods have been applied to a multi-class context in audio, such as sound scene classification, they have yet to be investigated for polyphonic audio in which sound events overlap, requiring the use of multi-label models. In this study, we establish the problem of multi-label open-set audio classification by creating a dataset with varying unknown class distributions and evaluating baseline approaches built upon existing techniques.
Learning the helix topology of musical pitch
Oct 22, 2019
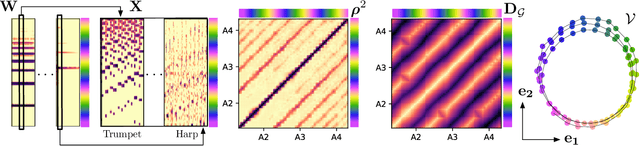
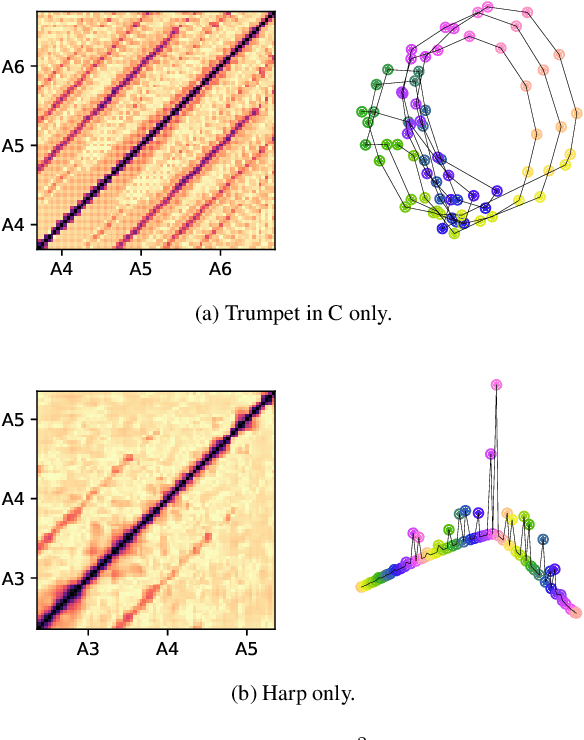
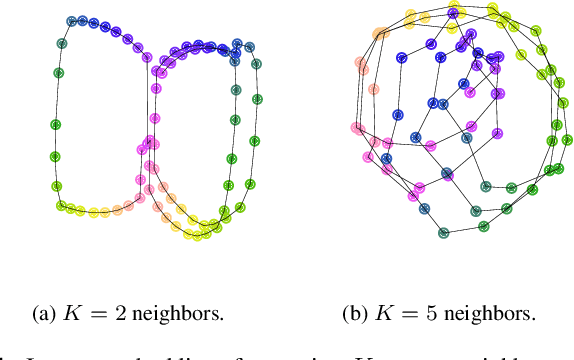
To explain the consonance of octaves, music psychologists represent pitch as a helix where azimuth and axial coordinate correspond to pitch class and pitch height respectively. This article addresses the problem of discovering this helical structure from unlabeled audio data. We measure Pearson correlations in the constant-Q transform (CQT) domain to build a K-nearest neighbor graph between frequency subbands. Then, we run the Isomap manifold learning algorithm to represent this graph in a three-dimensional space in which straight lines approximate graph geodesics. Experiments on isolated musical notes demonstrate that the resulting manifold resembles a helix which makes a full turn at every octave. A circular shape is also found in English speech, but not in urban noise. We discuss the impact of various design choices on the visualization: instrumentarium, loudness mapping function, and number of neighbors K.