 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Field-Based Approach for View Computation & Data Exploration in 3D Urban Environments
Nov 18, 2025Despite the growing availability of 3D urban datasets, extracting insights remains challenging due to computational bottlenecks and the complexity of interacting with data. In fact, the intricate geometry of 3D urban environments results in high degrees of occlusion and requires extensive manual viewpoint adjustments that make large-scale exploration inefficient. To address this, we propose a view-based approach for 3D data exploration, where a vector field encodes views from the environment. To support this approach, we introduce a neural field-based method that constructs an efficient implicit representation of 3D environments. This representation enables both faster direct queries, which consist of the computation of view assessment indices, and inverse queries, which help avoid occlusion and facilitate the search for views that match desired data patterns. Our approach supports key urban analysis tasks such as visibility assessments, solar exposure evaluation, and assessing the visual impact of new developments. We validate our method through quantitative experiments, case studies informed by real-world urban challenges, and feedback from domain experts. Results show its effectiveness in finding desirable viewpoints, analyzing building facade visibility, and evaluating views from outdoor spaces. Code and data are publicly available at https://urbantk.org/neural-3d.
Urbanite: A Dataflow-Based Framework for Human-AI Interactive Alignment in Urban Visual Analytics
Aug 10, 2025With the growing availability of urban data and the increasing complexity of societal challenges, visual analytics has become essential for deriving insights into pressing real-world problems. However, analyzing such data is inherently complex and iterative, requiring expertise across multiple domains. The need to manage diverse datasets, distill intricate workflows, and integrate various analytical methods presents a high barrier to entry, especially for researchers and urban experts who lack proficiency in data management, machine learning, and visualization. Advancements in large language models offer a promising solution to lower the barriers to the construction of analytics systems by enabling users to specify intent rather than define precise computational operations. However, this shift from explicit operations to intent-based interaction introduces challenges in ensuring alignment throughout the design and development process. Without proper mechanisms, gaps can emerge between user intent, system behavior, and analytical outcomes. To address these challenges, we propose Urbanite, a framework for human-AI collaboration in urban visual analytics. Urbanite leverages a dataflow-based model that allows users to specify intent at multiple scopes, enabling interactive alignment across the specification, process, and evaluation stages of urban analytics. Based on findings from a survey to uncover challenges, Urbanite incorporates features to facilitate explainability, multi-resolution definition of tasks across dataflows, nodes, and parameters, while supporting the provenance of interactions. We demonstrate Urbanite's effectiveness through usage scenarios created in collaboration with urban experts. Urbanite is available at https://urbantk.org/urbanite.
VA-Blueprint: Uncovering Building Blocks for Visual Analytics System Design
Aug 10, 2025Designing and building visual analytics (VA) systems is a complex, iterative process that requires the seamless integration of data processing, analytics capabilities, and visualization techniques. While prior research has extensively examined the social and collaborative aspects of VA system authoring, the practical challenges of developing these systems remain underexplored. As a result, despite the growing number of VA systems, there are only a few structured knowledge bases to guide their design and development. To tackle this gap, we propose VA-Blueprint, a methodology and knowledge base that systematically reviews and categorizes the fundamental building blocks of urban VA systems, a domain particularly rich and representative due to its intricate data and unique problem sets. Applying this methodology to an initial set of 20 systems, we identify and organize their core components into a multi-level structure, forming an initial knowledge base with a structured blueprint for VA system development. To scale this effort, we leverage a large language model to automate the extraction of these components for other 81 papers (completing a corpus of 101 papers), assessing its effectiveness in scaling knowledge base construction. We evaluate our method through interviews with experts and a quantitative analysis of annotation metrics. Our contributions provide a deeper understanding of VA systems' composition and establish a practical foundation to support more structured, reproducible, and efficient system development. VA-Blueprint is available at https://urbantk.org/va-blueprint.
Deep Umbra: A Generative Approach for Sunlight Access Computation in Urban Spaces
Feb 27, 2024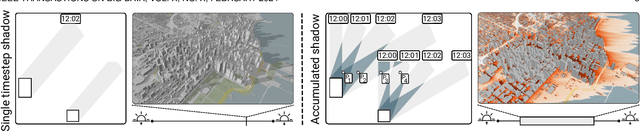
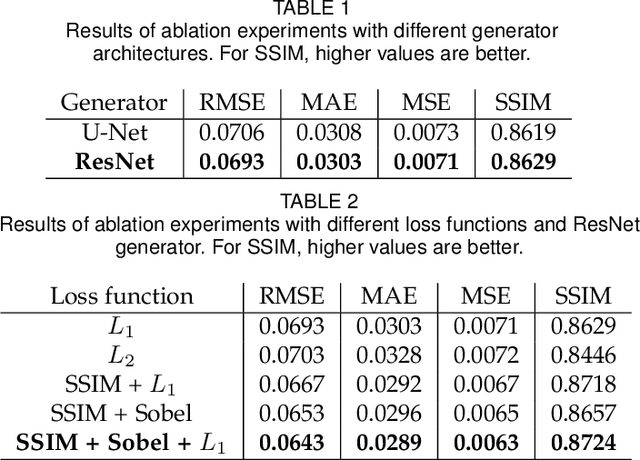
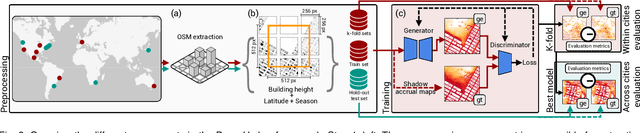
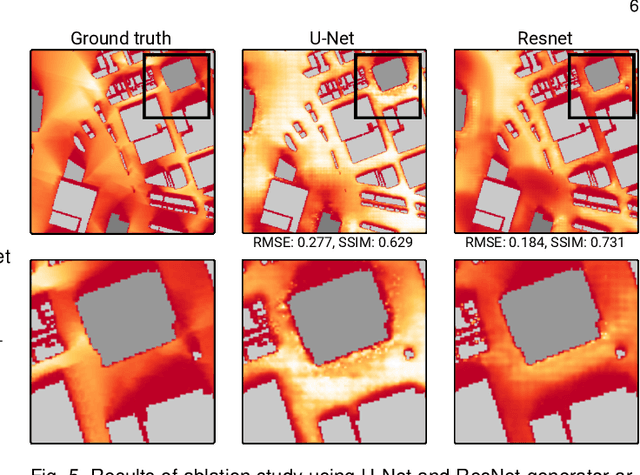
Sunlight and shadow play critical roles in how urban spaces are utilized, thrive, and grow. While access to sunlight is essential to the success of urban environments, shadows can provide shaded places to stay during the hot seasons, mitigate heat island effect, and increase pedestrian comfort levels. Properly quantifying sunlight access and shadows in large urban environments is key in tackling some of the important challenges facing cities today. In this paper, we propose Deep Umbra, a novel computational framework that enables the quantification of sunlight access and shadows at a global scale. Our framework is based on a conditional generative adversarial network that considers the physical form of cities to compute high-resolution spatial information of accumulated sunlight access for the different seasons of the year. We use data from seven different cities to train our model, and show, through an extensive set of experiments, its low overall RMSE (below 0.1) as well as its extensibility to cities that were not part of the training set. Additionally, we contribute a set of case studies and a comprehensive dataset with sunlight access information for more than 100 cities across six continents of the world. Deep Umbra is available at https://urbantk.org/shadows.
Towards Global-Scale Crowd+AI Techniques to Map and Assess Sidewalks for People with Disabilities
Jun 28, 2022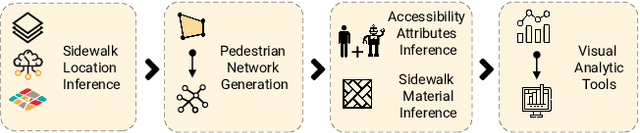


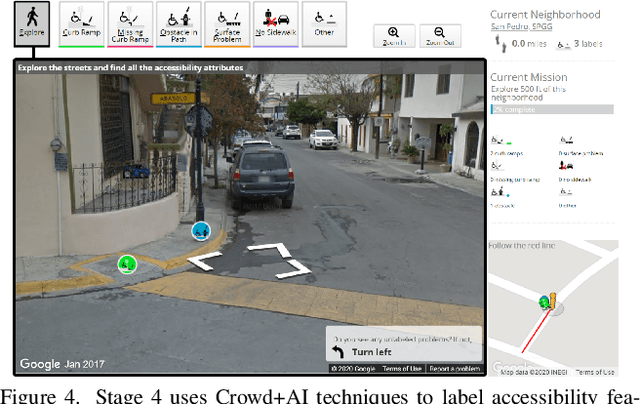
There is a lack of data on the location, condition, and accessibility of sidewalks across the world, which not only impacts where and how people travel but also fundamentally limits interactive mapping tools and urban analytics. In this paper, we describe initial work in semi-automatically building a sidewalk network topology from satellite imagery using hierarchical multi-scale attention models, inferring surface materials from street-level images using active learning-based semantic segmentation, and assessing sidewalk condition and accessibility features using Crowd+AI. We close with a call to create a database of labeled satellite and streetscape scenes for sidewalks and sidewalk accessibility issues along with standardized benchmarks.
Urban Rhapsody: Large-scale exploration of urban soundscapes
May 25, 2022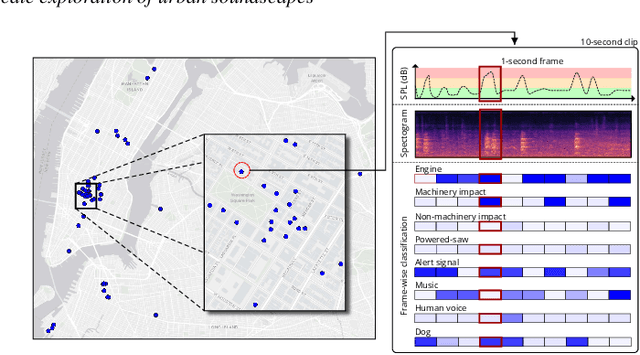
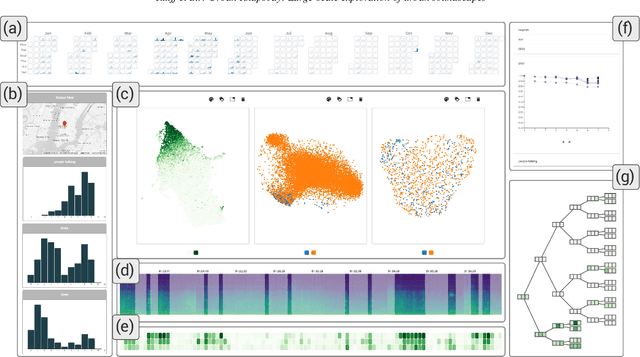
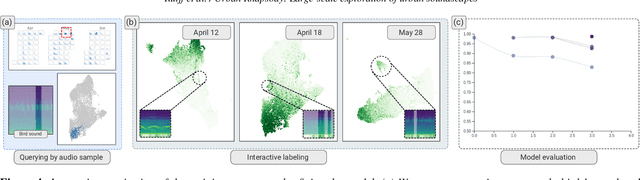
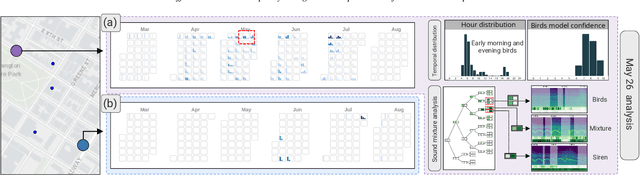
Noise is one of the primary quality-of-life issues in urban environments. In addition to annoyance, noise negatively impacts public health and educational performance. While low-cost sensors can be deployed to monitor ambient noise levels at high temporal resolutions, the amount of data they produce and the complexity of these data pose significant analytical challenges. One way to address these challenges is through machine listening techniques, which are used to extract features in attempts to classify the source of noise and understand temporal patterns of a city's noise situation. However, the overwhelming number of noise sources in the urban environment and the scarcity of labeled data makes it nearly impossible to create classification models with large enough vocabularies that capture the true dynamism of urban soundscapes In this paper, we first identify a set of requirements in the yet unexplored domain of urban soundscape exploration. To satisfy the requirements and tackle the identified challenges, we propose Urban Rhapsody, a framework that combines state-of-the-art audio representation, machine learning, and visual analytics to allow users to interactively create classification models, understand noise patterns of a city, and quickly retrieve and label audio excerpts in order to create a large high-precision annotated database of urban sound recordings. We demonstrate the tool's utility through case studies performed by domain experts using data generated over the five-year deployment of a one-of-a-kind sensor network in New York City.
CitySurfaces: City-Scale Semantic Segmentation of Sidewalk Materials
Jan 06, 2022



While designing sustainable and resilient urban built environment is increasingly promoted around the world, significant data gaps have made research on pressing sustainability issues challenging to carry out. Pavements are known to have strong economic and environmental impacts; however, most cities lack a spatial catalog of their surfaces due to the cost-prohibitive and time-consuming nature of data collection. Recent advancements in computer vision, together with the availability of street-level images, provide new opportunities for cities to extract large-scale built environment data with lower implementation costs and higher accuracy. In this paper, we propose CitySurfaces, an active learning-based framework that leverages computer vision techniques for classifying sidewalk materials using widely available street-level images. We trained the framework on images from New York City and Boston and the evaluation results show a 90.5% mIoU score. Furthermore, we evaluated the framework using images from six different cities, demonstrating that it can be applied to regions with distinct urban fabrics, even outside the domain of the training data. CitySurfaces can provide researchers and city agencies with a low-cost, accurate, and extensible method to collect sidewalk material data which plays a critical role in addressing major sustainability issues, including climate change and surface water management.
Sidewalk Measurements from Satellite Images: Preliminary Findings
Dec 12, 2021



Large-scale analysis of pedestrian infrastructures, particularly sidewalks, is critical to human-centric urban planning and design. Benefiting from the rich data set of planimetric features and high-resolution orthoimages provided through the New York City Open Data portal, we train a computer vision model to detect sidewalks, roads, and buildings from remote-sensing imagery and achieve 83% mIoU over held-out test set. We apply shape analysis techniques to study different attributes of the extracted sidewalks. More specifically, we do a tile-wise analysis of the width, angle, and curvature of sidewalks, which aside from their general impacts on walkability and accessibility of urban areas, are known to have significant roles in the mobility of wheelchair users. The preliminary results are promising, glimpsing the potential of the proposed approach to be adopted in different cities, enabling researchers and practitioners to have a more vivid picture of the pedestrian realm.
Transportation Scenario Planning with Graph Neural Networks
Oct 25, 2021



Providing efficient human mobility services and infrastructure is one of the major concerns of most mid-sized to large cities around the world. A proper understanding of the dynamics of commuting flows is, therefore, a requisite to better plan urban areas. In this context, an important task is to study hypothetical scenarios in which possible future changes are evaluated. For instance, how the increase in residential units or transportation modes in a neighborhood will change the commuting flows to or from that region? In this paper, we propose to leverage GMEL, a recently introduced graph neural network model, to evaluate changes in commuting flows taking into account different land use and infrastructure scenarios. We validate the usefulness of our methodology through real-world case studies set in two large cities in Brazil.
Learning Geo-Contextual Embeddings for Commuting Flow Prediction
May 04, 2020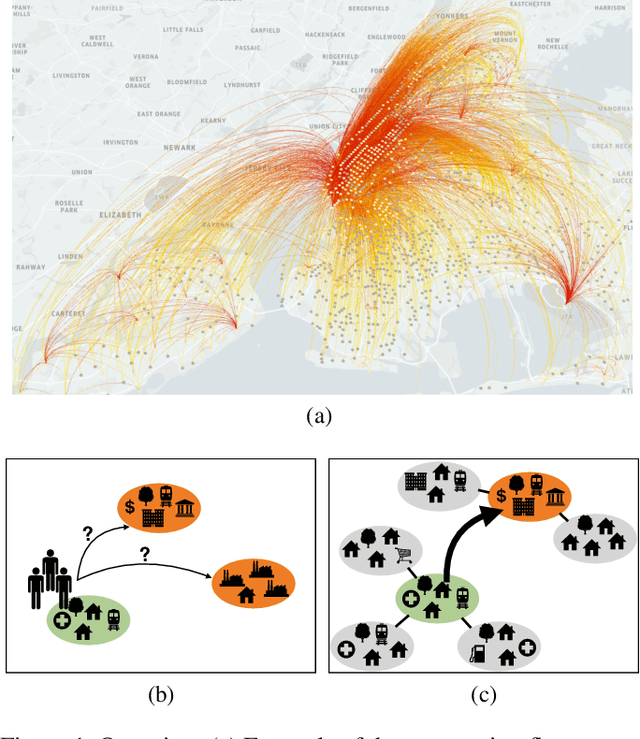
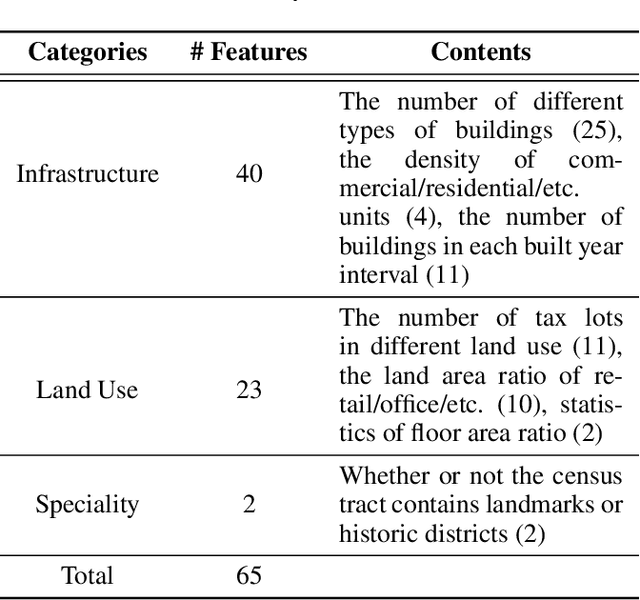
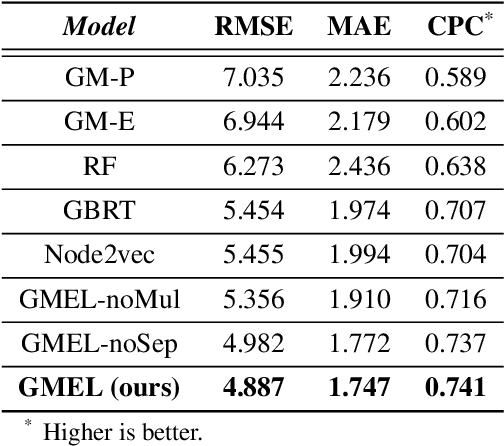
Predicting commuting flows based on infrastructure and land-use information is critical for urban planning and public policy development. However, it is a challenging task given the complex patterns of commuting flows. Conventional models, such as gravity model, are mainly derived from physics principles and limited by their predictive power in real-world scenarios where many factors need to be considered. Meanwhile, most existing machine learning-based methods ignore the spatial correlations and fail to model the influence of nearby regions. To address these issues, we propose Geo-contextual Multitask Embedding Learner (GMEL), a model that captures the spatial correlations from geographic contextual information for commuting flow prediction. Specifically, we first construct a geo-adjacency network containing the geographic contextual information. Then, an attention mechanism is proposed based on the framework of graph attention network (GAT) to capture the spatial correlations and encode geographic contextual information to embedding space. Two separate GATs are used to model supply and demand characteristics. A multitask learning framework is used to introduce stronger restrictions and enhance the effectiveness of the embedding representation. Finally, a gradient boosting machine is trained based on the learned embeddings to predict commuting flows. We evaluate our model using real-world datasets from New York City and the experimental results demonstrate the effectiveness of our proposal against the state of the art.
* Github: https://github.com/jackmiemie/GMEL