 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Source-Specific Sound Level Estimation in Noisy Soundscapes
May 06, 2021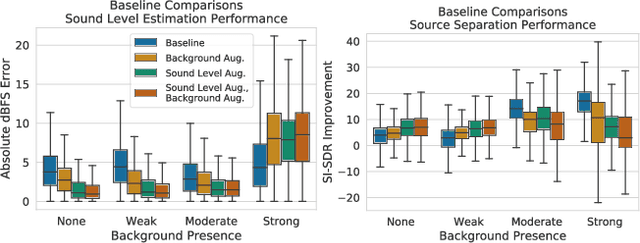
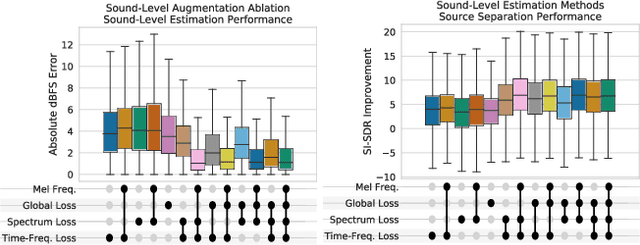
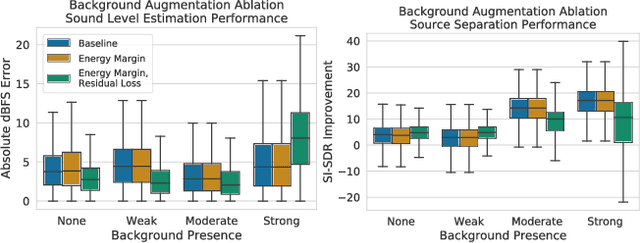
While the estimation of what sound sources are, when they occur, and from where they originate has been well-studied, the estimation of how loud these sound sources are has been often overlooked. Current solutions to this task, which we refer to as source-specific sound level estimation (SSSLE), suffer from challenges due to the impracticality of acquiring realistic data and a lack of robustness to realistic recording conditions. Recently proposed weakly supervised source separation offer a means of leveraging clip-level source annotations to train source separation models, which we augment with modified loss functions to bridge the gap between source separation and SSSLE and to address the presence of background. We show that our approach improves SSSLE performance compared to baseline source separation models and provide an ablation analysis to explore our method's design choices, showing that SSSLE in practical recording and annotation scenarios is possible.
Finding Strength in Weakness: Learning to Separate Sounds with Weak Supervision
Nov 06, 2019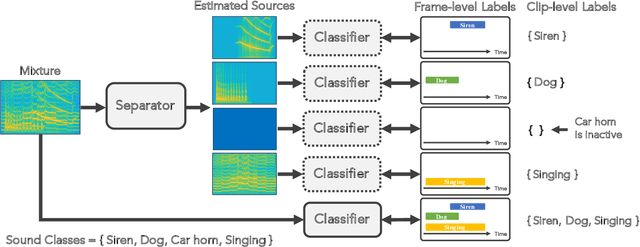
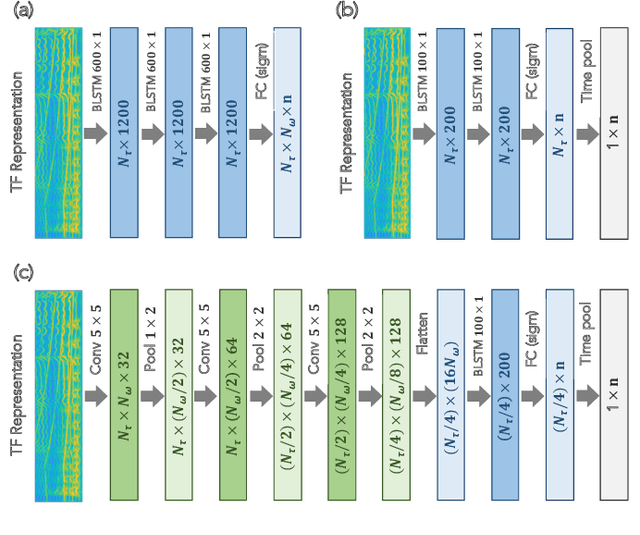
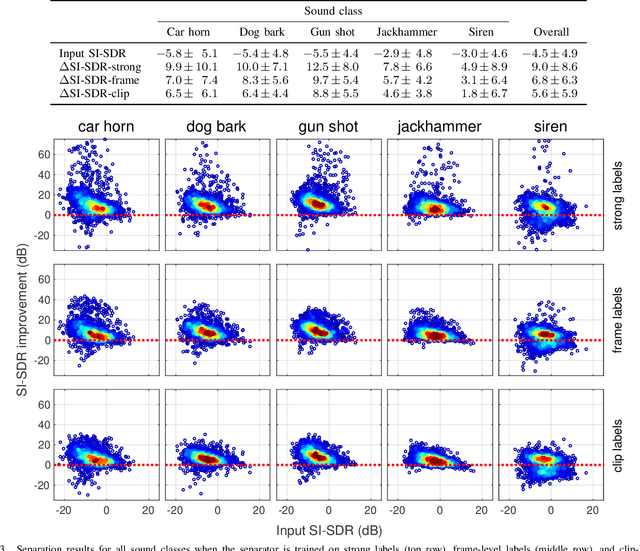
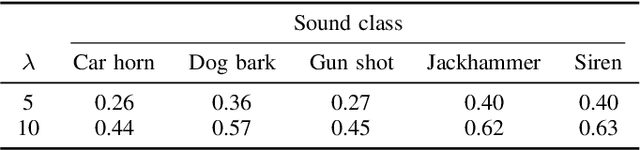
While there has been much recent progress using deep learning techniques to separate speech and music audio signals, these systems typically require large collections of isolated sources during the training process. When extending audio source separation algorithms to more general domains such as environmental monitoring, it may not be possible to obtain isolated signals for training. Here, we propose objective functions and network architectures that enable training a source separation system with weak labels. In this scenario, weak labels are defined in contrast with strong time-frequency (TF) labels such as those obtained from isolated sources, and refer either to frame-level weak labels where one only has access to the time periods when different sources are active in an audio mixture, or to clip-level weak labels that only indicate the presence or absence of sounds in an entire audio clip. We train a separator that estimates a TF mask for each type of sound event, using a sound event classifier as an assessor of the separator's performance to bridge the gap between the TF-level separation and the ground truth weak labels only available at the frame or clip level. Our objective function requires the classifier applied to a separated source to assign high probability to the class corresponding to that source and low probability to all other classes. The objective function also enforces that the separated sources sum up to the mixture. We benchmark the performance of our algorithm using synthetic mixtures of overlapping events created from a database of sounds recorded in urban environments. Compared to training a network using isolated sources, our model achieves somewhat lower but still significant SI-SDR improvement, even in scenarios with significant sound event overlap.