 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Robustness to Perturbations for Representations of Environmental Sound
Paper and Code
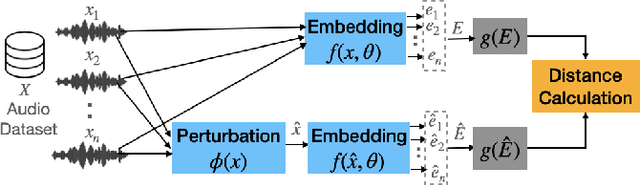
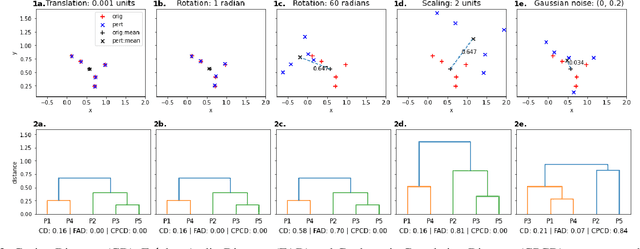
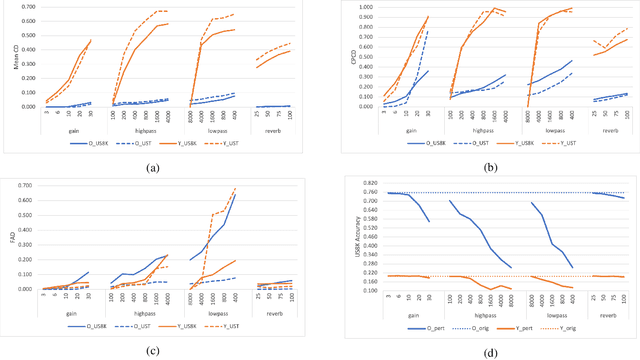
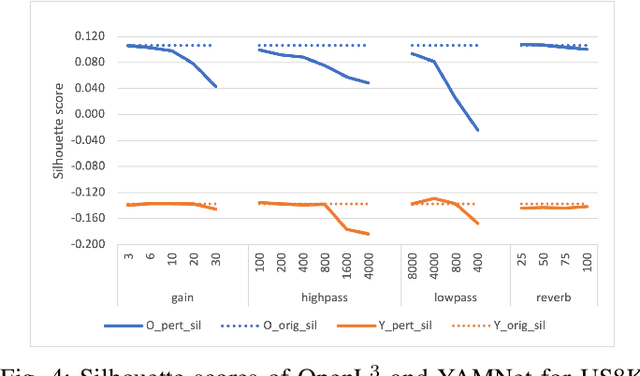
Audio applications involving environmental sound analysis increasingly use general-purpose audio representations, also known as embeddings, for transfer learning. Recently, Holistic Evaluation of Audio Representations (HEAR) evaluated twenty-nine embedding models on nineteen diverse tasks. However, the evaluation's effectiveness depends on the variation already captured within a given dataset. Therefore, for a given data domain, it is unclear how the representations would be affected by the variations caused by myriad microphones' range and acoustic conditions -- commonly known as channel effects. We aim to extend HEAR to evaluate invariance to channel effects in this work. To accomplish this, we imitate channel effects by injecting perturbations to the audio signal and measure the shift in the new (perturbed) embeddings with three distance measures, making the evaluation domain-dependent but not task-dependent. Combined with the downstream performance, it helps us make a more informed prediction of how robust the embeddings are to the channel effects. We evaluate two embeddings -- YAMNet, and OpenL$^3$ on monophonic (UrbanSound8K) and polyphonic (SONYC UST) datasets. We show that one distance measure does not suffice in such task-independent evaluation. Although Fr\'echet Audio Distance (FAD) correlates with the trend of the performance drop in the downstream task most accurately, we show that we need to study this in conjunction with the other distances to get a clear understanding of the overall effect of the perturbation. In terms of the embedding performance, we find OpenL$^3$ to be more robust to YAMNet, which aligns with the HEAR evaluation.