 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Listen? Rethinking Visual Sound Localization
Paper and Code

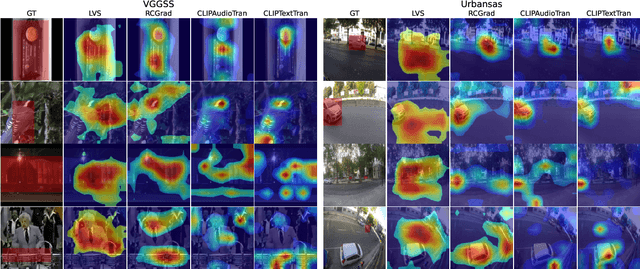

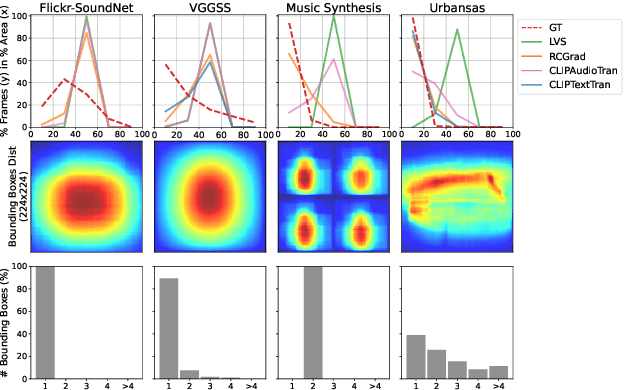
Localizing visual sounds consists on locating the position of objects that emit sound within an image. It is a growing research area with potential applications in monitoring natural and urban environments, such as wildlife migration and urban traffic. Previous works are usually evaluated with datasets having mostly a single dominant visible object, and proposed models usually require the introduction of localization modules during training or dedicated sampling strategies, but it remains unclear how these design choices play a role in the adaptability of these methods in more challenging scenarios. In this work, we analyze various model choices for visual sound localization and discuss how their different components affect the model's performance, namely the encoders' architecture, the loss function and the localization strategy. Furthermore, we study the interaction between these decisions, the model performance, and the data, by digging into different evaluation datasets spanning different difficulties and characteristics, and discuss the implications of such decisions in the context of real-world applications. Our code and model weights are open-sourced and made available for further applications.