 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLA: Enhancing Security and Privacy for Generative Models with Logic-Locked Accelerators
Dec 26, 2025We introduce LLA, an effective intellectual property (IP) protection scheme for generative AI models. LLA leverages the synergy between hardware and software to defend against various supply chain threats, including model theft, model corruption, and information leakage. On the software side, it embeds key bits into neurons that can trigger outliers to degrade performance and applies invariance transformations to obscure the key values. On the hardware side, it integrates a lightweight locking module into the AI accelerator while maintaining compatibility with various dataflow patterns and toolchains. An accelerator with a pre-stored secret key acts as a license to access the model services provided by the IP owner. The evaluation results show that LLA can withstand a broad range of oracle-guided key optimization attacks, while incurring a minimal computational overhead of less than 0.1% for 7,168 key bits.
Certifying Global Robustness for Deep Neural Networks
May 31, 2024



A globally robust deep neural network resists perturbations on all meaningful inputs. Current robustness certification methods emphasize local robustness, struggling to scale and generalize. This paper presents a systematic and efficient method to evaluate and verify global robustness for deep neural networks, leveraging the PAC verification framework for solid guarantees on verification results. We utilize probabilistic programs to characterize meaningful input regions, setting a realistic standard for global robustness. Additionally, we introduce the cumulative robustness curve as a criterion in evaluating global robustness. We design a statistical method that combines multi-level splitting and regression analysis for the estimation, significantly reducing the execution time. Experimental results demonstrate the efficiency and effectiveness of our verification method and its capability to find rare and diversified counterexamples for adversarial training.
How Image Generation Helps Visible-to-Infrared Person Re-Identification?
Oct 04, 2022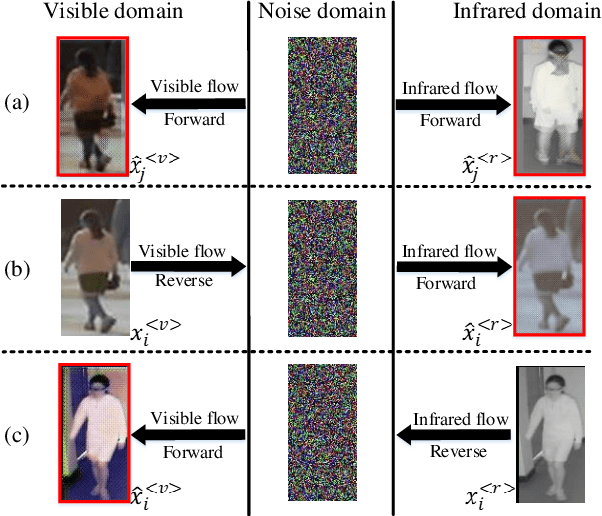



Compared to visible-to-visible (V2V) person re-identification (ReID), the visible-to-infrared (V2I) person ReID task is more challenging due to the lack of sufficient training samples and the large cross-modality discrepancy. To this end, we propose Flow2Flow, a unified framework that could jointly achieve training sample expansion and cross-modality image generation for V2I person ReID. Specifically, Flow2Flow learns bijective transformations from both the visible image domain and the infrared domain to a shared isotropic Gaussian domain with an invertible visible flow-based generator and an infrared one, respectively. With Flow2Flow, we are able to generate pseudo training samples by the transformation from latent Gaussian noises to visible or infrared images, and generate cross-modality images by transformations from existing-modality images to latent Gaussian noises to missing-modality images. For the purpose of identity alignment and modality alignment of generated images, we develop adversarial training strategies to train Flow2Flow. Specifically, we design an image encoder and a modality discriminator for each modality. The image encoder encourages the generated images to be similar to real images of the same identity via identity adversarial training, and the modality discriminator makes the generated images modal-indistinguishable from real images via modality adversarial training. Experimental results on SYSU-MM01 and RegDB demonstrate that both training sample expansion and cross-modality image generation can significantly improve V2I ReID accuracy.
Pose-Aided Video-based Person Re-Identification via Recurrent Graph Convolutional Network
Sep 23, 2022

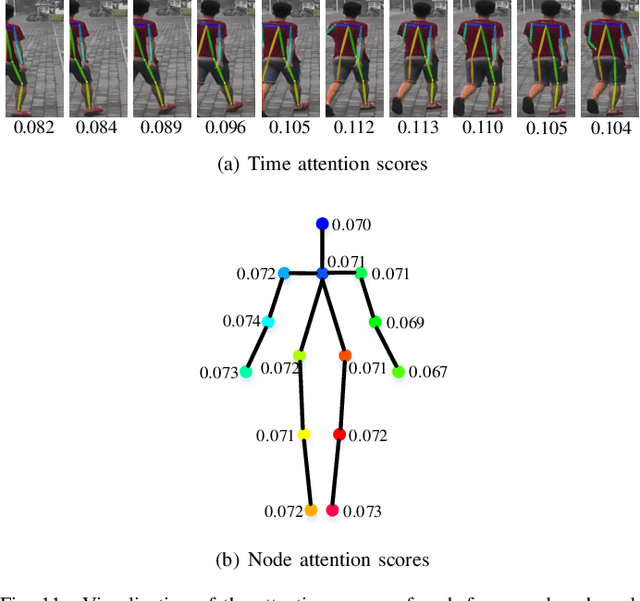
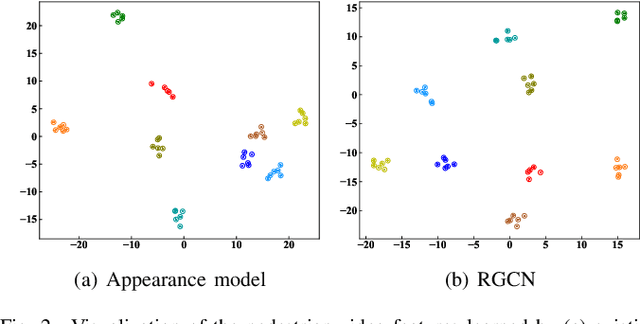
Existing methods for video-based person re-identification (ReID) mainly learn the appearance feature of a given pedestrian via a feature extractor and a feature aggregator. However, the appearance models would fail when different pedestrians have similar appearances. Considering that different pedestrians have different walking postures and body proportions, we propose to learn the discriminative pose feature beyond the appearance feature for video retrieval. Specifically, we implement a two-branch architecture to separately learn the appearance feature and pose feature, and then concatenate them together for inference. To learn the pose feature, we first detect the pedestrian pose in each frame through an off-the-shelf pose detector, and construct a temporal graph using the pose sequence. We then exploit a recurrent graph convolutional network (RGCN) to learn the node embeddings of the temporal pose graph, which devises a global information propagation mechanism to simultaneously achieve the neighborhood aggregation of intra-frame nodes and message passing among inter-frame graphs. Finally, we propose a dual-attention method consisting of node-attention and time-attention to obtain the temporal graph representation from the node embeddings, where the self-attention mechanism is employed to learn the importance of each node and each frame. We verify the proposed method on three video-based ReID datasets, i.e., Mars, DukeMTMC and iLIDS-VID, whose experimental results demonstrate that the learned pose feature can effectively improve the performance of existing appearance models.
Towards Complete-View and High-Level Pose-based Gait Recognition
Sep 23, 2022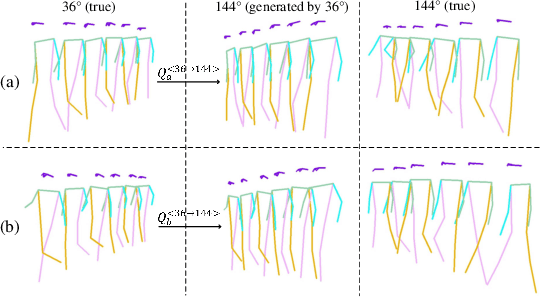
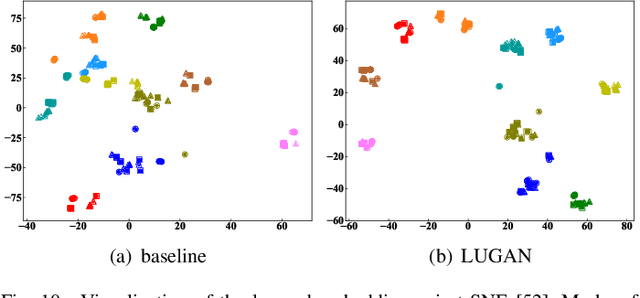
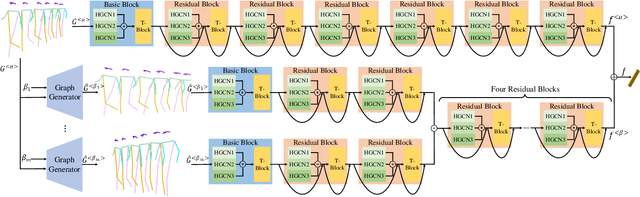
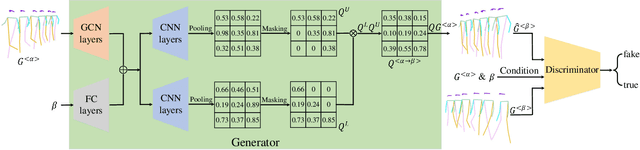
The model-based gait recognition methods usually adopt the pedestrian walking postures to identify human beings. However, existing methods did not explicitly resolve the large intra-class variance of human pose due to camera views changing. In this paper, we propose to generate multi-view pose sequences for each single-view pose sample by learning full-rank transformation matrices via lower-upper generative adversarial network (LUGAN). By the prior of camera imaging, we derive that the spatial coordinates between cross-view poses satisfy a linear transformation of a full-rank matrix, thereby, this paper employs the adversarial training to learn transformation matrices from the source pose and target views to obtain the target pose sequences. To this end, we implement a generator composed of graph convolutional (GCN) layers, fully connected (FC) layers and two-branch convolutional (CNN) layers: GCN layers and FC layers encode the source pose sequence and target view, then CNN branches learn a lower triangular matrix and an upper triangular matrix, respectively, finally they are multiplied to formulate the full-rank transformation matrix. For the purpose of adversarial training, we further devise a condition discriminator that distinguishes whether the pose sequence is true or generated. To enable the high-level correlation learning, we propose a plug-and-play module, named multi-scale hypergraph convolution (HGC), to replace the spatial graph convolutional layer in baseline, which could simultaneously model the joint-level, part-level and body-level correlations. Extensive experiments on two large gait recognition datasets, i.e., CASIA-B and OUMVLP-Pose, demonstrate that our method outperforms the baseline model and existing pose-based methods by a large margin.