 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Complete-View and High-Level Pose-based Gait Recognition
Paper and Code
Sep 23, 2022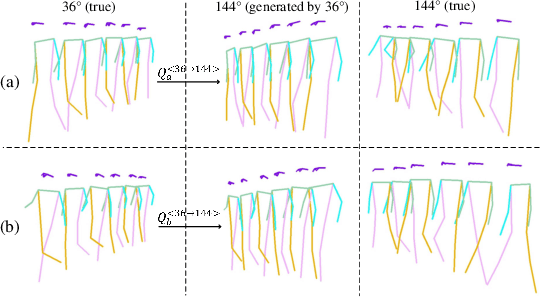
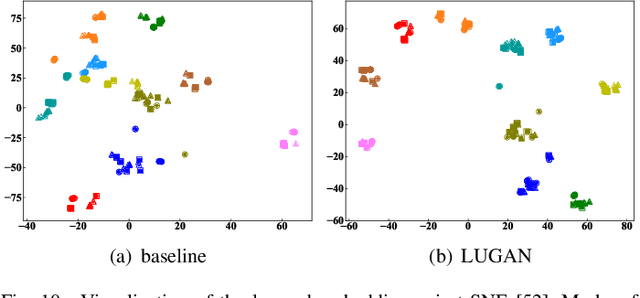
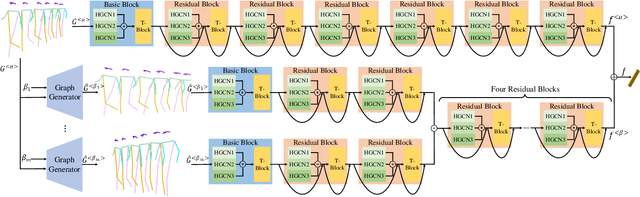
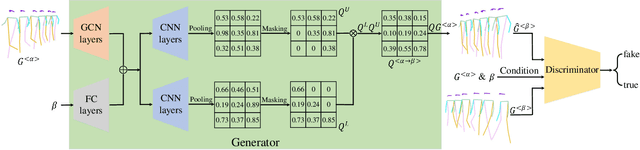
The model-based gait recognition methods usually adopt the pedestrian walking postures to identify human beings. However, existing methods did not explicitly resolve the large intra-class variance of human pose due to camera views changing. In this paper, we propose to generate multi-view pose sequences for each single-view pose sample by learning full-rank transformation matrices via lower-upper generative adversarial network (LUGAN). By the prior of camera imaging, we derive that the spatial coordinates between cross-view poses satisfy a linear transformation of a full-rank matrix, thereby, this paper employs the adversarial training to learn transformation matrices from the source pose and target views to obtain the target pose sequences. To this end, we implement a generator composed of graph convolutional (GCN) layers, fully connected (FC) layers and two-branch convolutional (CNN) layers: GCN layers and FC layers encode the source pose sequence and target view, then CNN branches learn a lower triangular matrix and an upper triangular matrix, respectively, finally they are multiplied to formulate the full-rank transformation matrix. For the purpose of adversarial training, we further devise a condition discriminator that distinguishes whether the pose sequence is true or generated. To enable the high-level correlation learning, we propose a plug-and-play module, named multi-scale hypergraph convolution (HGC), to replace the spatial graph convolutional layer in baseline, which could simultaneously model the joint-level, part-level and body-level correlations. Extensive experiments on two large gait recognition datasets, i.e., CASIA-B and OUMVLP-Pose, demonstrate that our method outperforms the baseline model and existing pose-based methods by a large margin.