 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Map as Language: Toward Unified Remote Sensing Vector Mapping
Jun 09, 2026Remote sensing vector mapping aims to generate structured maps of geospatial entities, such as buildings, roads, and water bodies, from remote sensing imagery. In practice, vector maps usually contain multiple category layers and heterogeneous entity structures, requiring a unified model for diverse mapping needs. However, existing methods typically represent vector objects as polygons or graphs, making them suitable only for specific categories: polygons poorly capture topological relations, while graphs often blur instance boundaries. We observe that language, as a natural medium for human communication, offers a flexible and expressive representation that can accommodate heterogeneous map elements, including geometry, semantics, and topolog. Motivated by this insight, we propose Vector Map as Language (VecLang), a unified paradigm that reformulates multiclass vector mapping as structured text generation. VecLang encodes the common elements of different geospatial entities into a GeoJSON-like vector language, enabling cross-category modeling within a shared textual format. To generate this language reliably, we design a progressive vision-language mapping framework that first localizes vectorization units and then generates structured map elements. We further introduce Hierarchical Vector Language Optimization, which uses reinforcement learning to improve syntax validity, content fidelity, and map executability. We also build VecMap-Bench with 54K images and 800K instances, supporting training and evaluation across standard and generalization settings. Extensive experiments demonstrate that VecLang handles both single-class and multiclass vector mapping while achieving strong cross-dataset and open-vocabulary generalization. The model and dataset are publicly available at https://github.com/yyyyll0ss/VecLang.
Text-to-CAD Retrieval: a Strong Baseline
May 07, 2026Text-based retrieval of Computer-Aided Design (CAD) models is a critical yet underexplored task for the reuse of legacy industrial designs. Existing CAD repositories are typically searched using filenames or directories, which limits the efficiency, scalability, and accuracy of design retrieval. In this paper, we formally introduce text-to-CAD retrieval as a new cross-modal retrieval task, aiming to retrieve semantically relevant CAD models from large-scale databases given natural language queries. Leveraging paired text-CAD annotations from the Text2CAD dataset, we establish a practical benchmark for this task. To achieve text-based retrieval, we propose a unified framework that learns multi-modal CAD embeddings from both procedural sequences and geometric point clouds. Specifically, a sequence encoder captures the construction logic of CAD models, while a point encoder extracts explicit geometric features. A text encoder is used to learn semantic representations of textual queries. During training, we introduce a novel feature decoder that reconstructs masked sequence features via cross-attention with text and point features, encouraging implicit multi-modal alignment. At inference time, we remove this auxiliary decoder to enable efficient retrieval using concatenated sequence-point features. Our framework serves as a strong baseline for text-to-CAD retrieval and lays the foundation for downstream CAD generation paradigms, such as retrieval-augmented generation. The source code will be released.
Computer-Aided Design Generation by Cascaded Discrete Diffusion Model
May 06, 2026Recent deep learning approaches seek to automate CAD creation by representing a model as a sequence of discrete commands and parameters, and then generating them using autoregressive models or continuous diffusion operating in Euclidean embedding space. However, continuous diffusion perturbs representations in a continuous Euclidean domain that does not reflect the inherently discrete and heterogeneous nature of CAD tokens, often producing perturbed representations that map to semantically invalid symbols. To overcome this limitation, we propose a cascaded discrete diffusion framework for CAD generation, which consists of a command diffusion for generating CAD commands and a parameter diffusion conditioned on CAD commands. Unlike isotropic Gaussian perturbation, the forward process of our approach operates directly over categorical token distributions using delicate transition matrices. For commands, we adopt an absorbing-state transition matrix that progressively corrupts tokens to a designated symbol; for parameters, we introduce specific transition matrices tailored to heterogeneous attributes: a Gaussian kernel for coordinate continuity, a scale-invariant kernel for dimensional values, and a prior-preserving kernel for boolean attributes. The reverse process is achieved by two denoising networks: a Transformer-based encoder for command recovery, and a parameter network with extra local self-attention for command-level interaction and cross-attention for conditional injection. Experiments on the DeepCAD dataset show that the proposed approach surpasses existing autoregressive and continuous diffusion models on unconditional generation metrics, while qualitative results validate effective controllability in conditional generation tasks. Source codes will be released.
Data Generation Scheme for Thermal Modality with Edge-Guided Adversarial Conditional Diffusion Model
Aug 07, 2024In challenging low light and adverse weather conditions,thermal vision algorithms,especially object detection,have exhibited remarkable potential,contrasting with the frequent struggles encountered by visible vision algorithms. Nevertheless,the efficacy of thermal vision algorithms driven by deep learning models remains constrained by the paucity of available training data samples. To this end,this paper introduces a novel approach termed the edge guided conditional diffusion model. This framework aims to produce meticulously aligned pseudo thermal images at the pixel level,leveraging edge information extracted from visible images. By utilizing edges as contextual cues from the visible domain,the diffusion model achieves meticulous control over the delineation of objects within the generated images. To alleviate the impacts of those visible-specific edge information that should not appear in the thermal domain,a two-stage modality adversarial training strategy is proposed to filter them out from the generated images by differentiating the visible and thermal modality. Extensive experiments on LLVIP demonstrate ECDM s superiority over existing state-of-the-art approaches in terms of image generation quality.
How Image Generation Helps Visible-to-Infrared Person Re-Identification?
Oct 04, 2022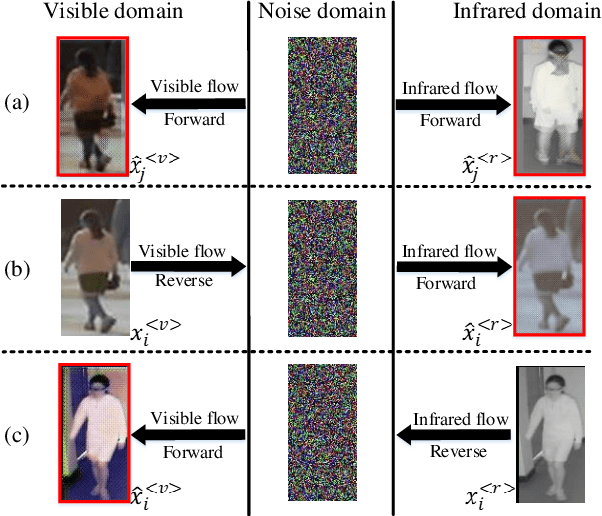



Compared to visible-to-visible (V2V) person re-identification (ReID), the visible-to-infrared (V2I) person ReID task is more challenging due to the lack of sufficient training samples and the large cross-modality discrepancy. To this end, we propose Flow2Flow, a unified framework that could jointly achieve training sample expansion and cross-modality image generation for V2I person ReID. Specifically, Flow2Flow learns bijective transformations from both the visible image domain and the infrared domain to a shared isotropic Gaussian domain with an invertible visible flow-based generator and an infrared one, respectively. With Flow2Flow, we are able to generate pseudo training samples by the transformation from latent Gaussian noises to visible or infrared images, and generate cross-modality images by transformations from existing-modality images to latent Gaussian noises to missing-modality images. For the purpose of identity alignment and modality alignment of generated images, we develop adversarial training strategies to train Flow2Flow. Specifically, we design an image encoder and a modality discriminator for each modality. The image encoder encourages the generated images to be similar to real images of the same identity via identity adversarial training, and the modality discriminator makes the generated images modal-indistinguishable from real images via modality adversarial training. Experimental results on SYSU-MM01 and RegDB demonstrate that both training sample expansion and cross-modality image generation can significantly improve V2I ReID accuracy.
Multi-Granularity Graph Pooling for Video-based Person Re-Identification
Sep 23, 2022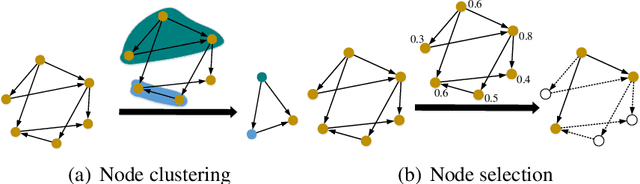
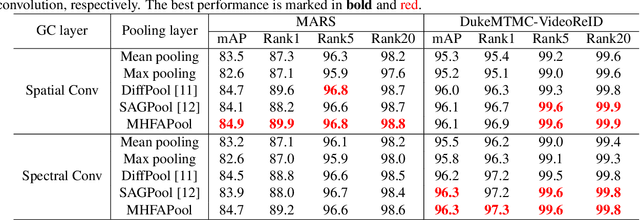
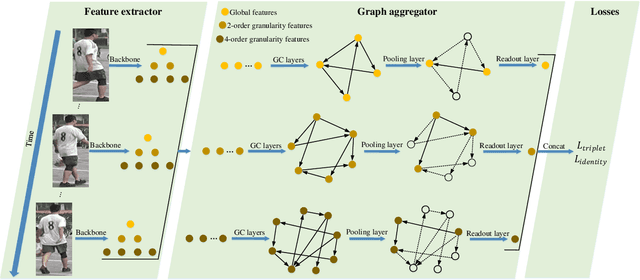
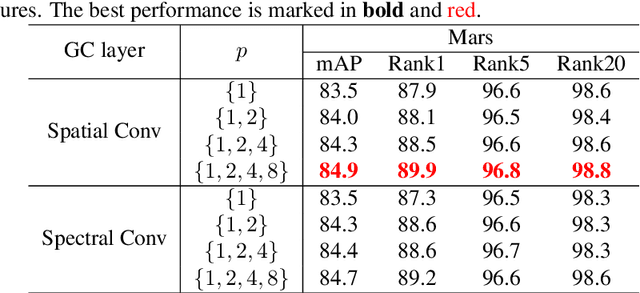
The video-based person re-identification (ReID) aims to identify the given pedestrian video sequence across multiple non-overlapping cameras. To aggregate the temporal and spatial features of the video samples, the graph neural networks (GNNs) are introduced. However, existing graph-based models, like STGCN, perform the \textit{mean}/\textit{max pooling} on node features to obtain the graph representation, which neglect the graph topology and node importance. In this paper, we propose the graph pooling network (GPNet) to learn the multi-granularity graph representation for the video retrieval, where the \textit{graph pooling layer} is implemented to downsample the graph. We first construct a multi-granular graph, whose node features denote image embedding learned by backbone, and edges are established between the temporal and Euclidean neighborhood nodes. We then implement multiple graph convolutional layers to perform the neighborhood aggregation on the graphs. To downsample the graph, we propose a multi-head full attention graph pooling (MHFAPool) layer, which integrates the advantages of existing node clustering and node selection pooling methods. Specifically, MHFAPool takes the main eigenvector of full attention matrix as the aggregation coefficients to involve the global graph information in each pooled nodes. Extensive experiments demonstrate that our GPNet achieves the competitive results on four widely-used datasets, i.e., MARS, DukeMTMC-VideoReID, iLIDS-VID and PRID-2011.
Pose-Aided Video-based Person Re-Identification via Recurrent Graph Convolutional Network
Sep 23, 2022

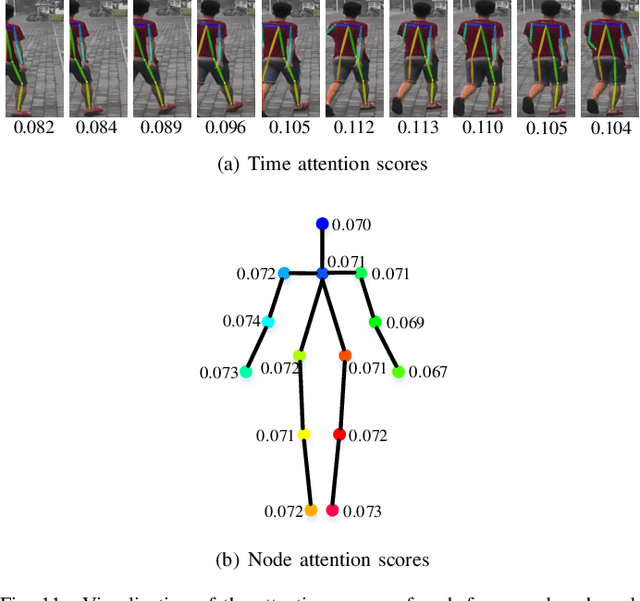
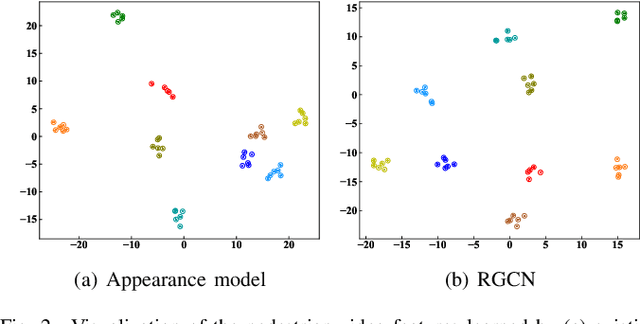
Existing methods for video-based person re-identification (ReID) mainly learn the appearance feature of a given pedestrian via a feature extractor and a feature aggregator. However, the appearance models would fail when different pedestrians have similar appearances. Considering that different pedestrians have different walking postures and body proportions, we propose to learn the discriminative pose feature beyond the appearance feature for video retrieval. Specifically, we implement a two-branch architecture to separately learn the appearance feature and pose feature, and then concatenate them together for inference. To learn the pose feature, we first detect the pedestrian pose in each frame through an off-the-shelf pose detector, and construct a temporal graph using the pose sequence. We then exploit a recurrent graph convolutional network (RGCN) to learn the node embeddings of the temporal pose graph, which devises a global information propagation mechanism to simultaneously achieve the neighborhood aggregation of intra-frame nodes and message passing among inter-frame graphs. Finally, we propose a dual-attention method consisting of node-attention and time-attention to obtain the temporal graph representation from the node embeddings, where the self-attention mechanism is employed to learn the importance of each node and each frame. We verify the proposed method on three video-based ReID datasets, i.e., Mars, DukeMTMC and iLIDS-VID, whose experimental results demonstrate that the learned pose feature can effectively improve the performance of existing appearance models.
Towards Complete-View and High-Level Pose-based Gait Recognition
Sep 23, 2022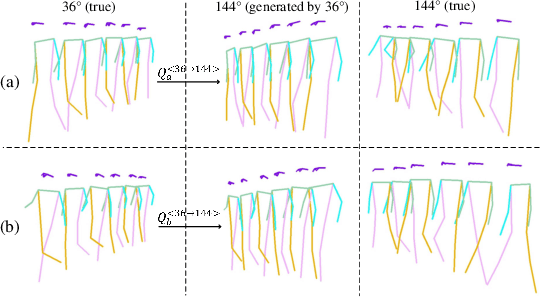
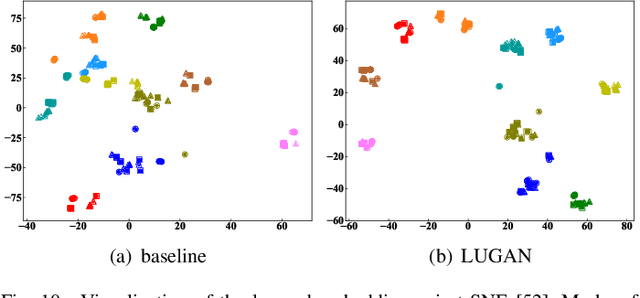
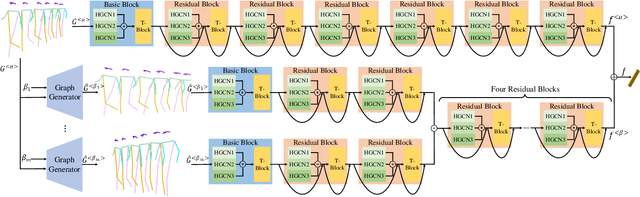
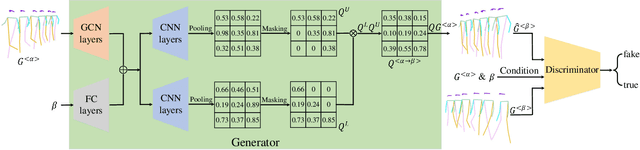
The model-based gait recognition methods usually adopt the pedestrian walking postures to identify human beings. However, existing methods did not explicitly resolve the large intra-class variance of human pose due to camera views changing. In this paper, we propose to generate multi-view pose sequences for each single-view pose sample by learning full-rank transformation matrices via lower-upper generative adversarial network (LUGAN). By the prior of camera imaging, we derive that the spatial coordinates between cross-view poses satisfy a linear transformation of a full-rank matrix, thereby, this paper employs the adversarial training to learn transformation matrices from the source pose and target views to obtain the target pose sequences. To this end, we implement a generator composed of graph convolutional (GCN) layers, fully connected (FC) layers and two-branch convolutional (CNN) layers: GCN layers and FC layers encode the source pose sequence and target view, then CNN branches learn a lower triangular matrix and an upper triangular matrix, respectively, finally they are multiplied to formulate the full-rank transformation matrix. For the purpose of adversarial training, we further devise a condition discriminator that distinguishes whether the pose sequence is true or generated. To enable the high-level correlation learning, we propose a plug-and-play module, named multi-scale hypergraph convolution (HGC), to replace the spatial graph convolutional layer in baseline, which could simultaneously model the joint-level, part-level and body-level correlations. Extensive experiments on two large gait recognition datasets, i.e., CASIA-B and OUMVLP-Pose, demonstrate that our method outperforms the baseline model and existing pose-based methods by a large margin.
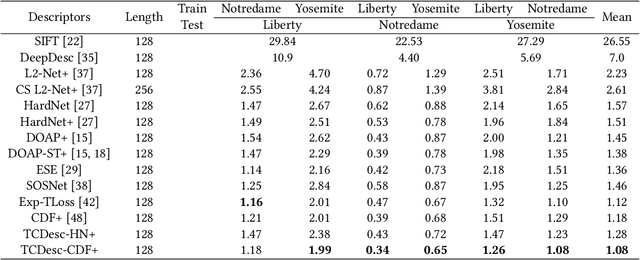
TCDesc: Learning Topology Consistent Descriptors for Image Matching
Sep 13, 2020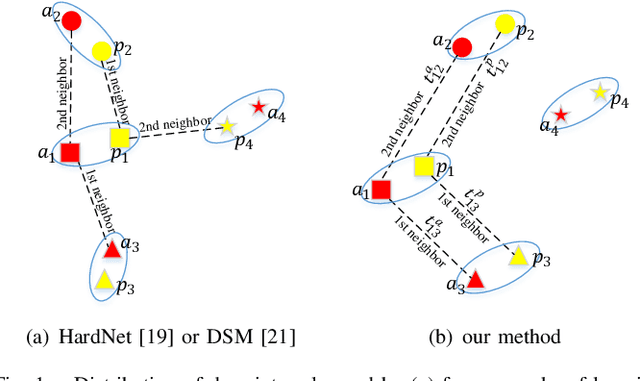
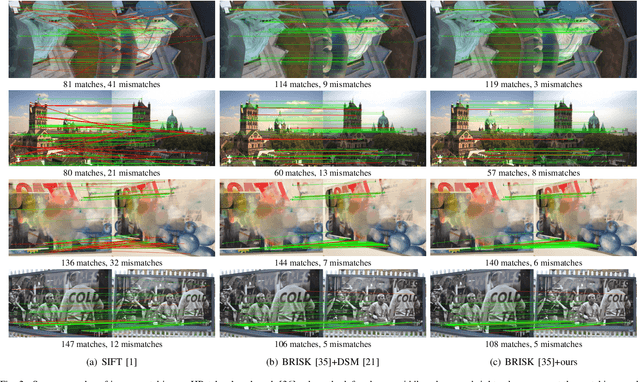
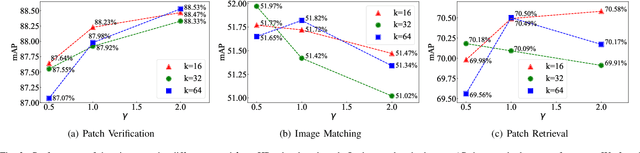

The constraint of neighborhood consistency or local consistency is widely used for robust image matching. In this paper, we focus on learning neighborhood topology consistent descriptors (TCDesc), while former works of learning descriptors, such as HardNet and DSM, only consider point-to-point Euclidean distance among descriptors and totally neglect neighborhood information of descriptors. To learn topology consistent descriptors, first we propose the linear combination weights to depict the topological relationship between center descriptor and its kNN descriptors, where the difference between center descriptor and the linear combination of its kNN descriptors is minimized. Then we propose the global mapping function which maps the local linear combination weights to the global topology vector and define the topology distance of matching descriptors as l1 distance between their topology vectors. Last we employ adaptive weighting strategy to jointly minimize topology distance and Euclidean distance, which automatically adjust the weight or attention of two distances in triplet loss. Our method has the following two advantages: (1) We are the first to consider neighborhood information of descriptors, while former works mainly focus on neighborhood consistency of feature points; (2) Our method can be applied in any former work of learning descriptors by triplet loss. Experimental results verify the generalization of our method: We can improve the performances of both HardNet and DSM on several benchmarks.
TCDesc: Learning Topology Consistent Descriptors
Jun 05, 2020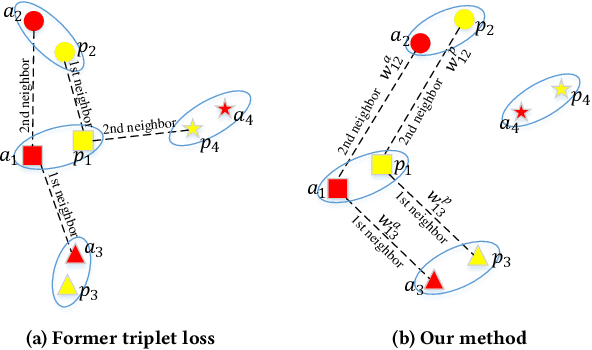
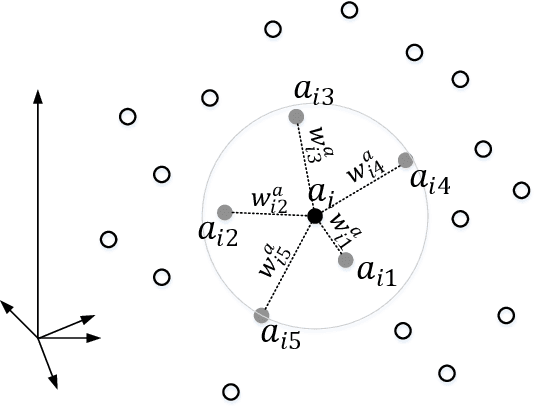
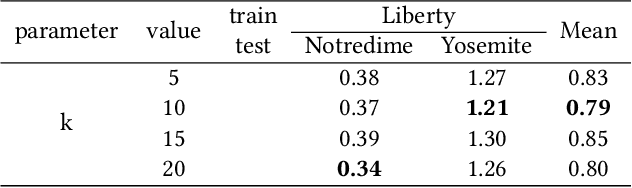
Triplet loss is widely used for learning local descriptors from image patch. However, triplet loss only minimizes the Euclidean distance between matching descriptors and maximizes that between the non-matching descriptors, which neglects the topology similarity between two descriptor sets. In this paper, we propose topology measure besides Euclidean distance to learn topology consistent descriptors by considering kNN descriptors of positive sample. First we establish a novel topology vector for each descriptor followed by Locally Linear Embedding (LLE) to indicate the topological relation among the descriptor and its kNN descriptors. Then we define topology distance between descriptors as the difference of their topology vectors. Last we employ the dynamic weighting strategy to fuse Euclidean distance and topology distance of matching descriptors and take the fusion result as the positive sample distance in the triplet loss. Experimental results on several benchmarks show that our method performs better than state-of-the-arts results and effectively improves the performance of triplet loss.