 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Image Generation Helps Visible-to-Infrared Person Re-Identification?
Paper and Code
Oct 04, 2022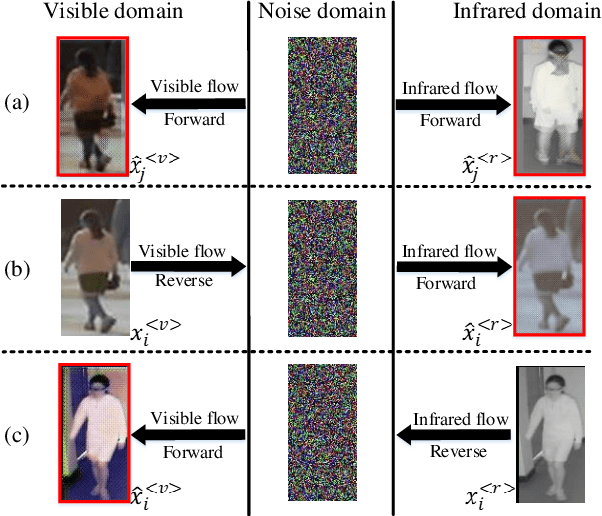



Compared to visible-to-visible (V2V) person re-identification (ReID), the visible-to-infrared (V2I) person ReID task is more challenging due to the lack of sufficient training samples and the large cross-modality discrepancy. To this end, we propose Flow2Flow, a unified framework that could jointly achieve training sample expansion and cross-modality image generation for V2I person ReID. Specifically, Flow2Flow learns bijective transformations from both the visible image domain and the infrared domain to a shared isotropic Gaussian domain with an invertible visible flow-based generator and an infrared one, respectively. With Flow2Flow, we are able to generate pseudo training samples by the transformation from latent Gaussian noises to visible or infrared images, and generate cross-modality images by transformations from existing-modality images to latent Gaussian noises to missing-modality images. For the purpose of identity alignment and modality alignment of generated images, we develop adversarial training strategies to train Flow2Flow. Specifically, we design an image encoder and a modality discriminator for each modality. The image encoder encourages the generated images to be similar to real images of the same identity via identity adversarial training, and the modality discriminator makes the generated images modal-indistinguishable from real images via modality adversarial training. Experimental results on SYSU-MM01 and RegDB demonstrate that both training sample expansion and cross-modality image generation can significantly improve V2I ReID accuracy.