 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Aided Video-based Person Re-Identification via Recurrent Graph Convolutional Network
Paper and Code
Sep 23, 2022

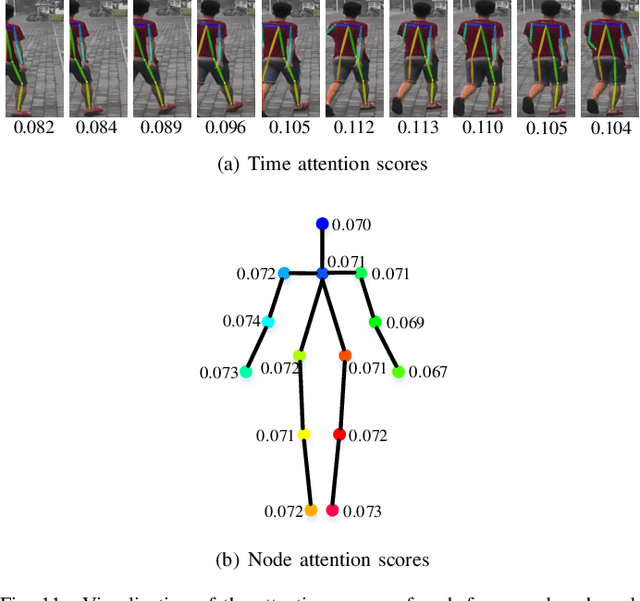
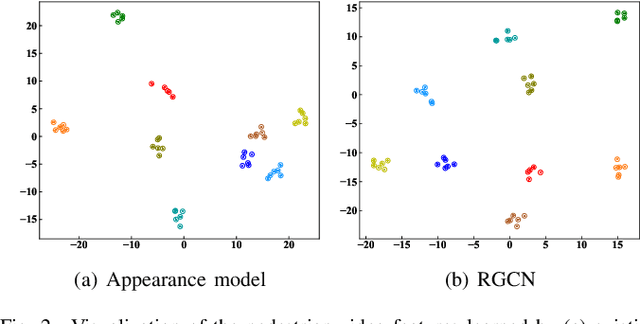
Existing methods for video-based person re-identification (ReID) mainly learn the appearance feature of a given pedestrian via a feature extractor and a feature aggregator. However, the appearance models would fail when different pedestrians have similar appearances. Considering that different pedestrians have different walking postures and body proportions, we propose to learn the discriminative pose feature beyond the appearance feature for video retrieval. Specifically, we implement a two-branch architecture to separately learn the appearance feature and pose feature, and then concatenate them together for inference. To learn the pose feature, we first detect the pedestrian pose in each frame through an off-the-shelf pose detector, and construct a temporal graph using the pose sequence. We then exploit a recurrent graph convolutional network (RGCN) to learn the node embeddings of the temporal pose graph, which devises a global information propagation mechanism to simultaneously achieve the neighborhood aggregation of intra-frame nodes and message passing among inter-frame graphs. Finally, we propose a dual-attention method consisting of node-attention and time-attention to obtain the temporal graph representation from the node embeddings, where the self-attention mechanism is employed to learn the importance of each node and each frame. We verify the proposed method on three video-based ReID datasets, i.e., Mars, DukeMTMC and iLIDS-VID, whose experimental results demonstrate that the learned pose feature can effectively improve the performance of existing appearance models.