 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granularity Graph Pooling for Video-based Person Re-Identification
Paper and Code
Sep 23, 2022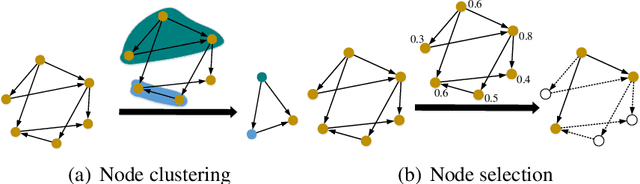
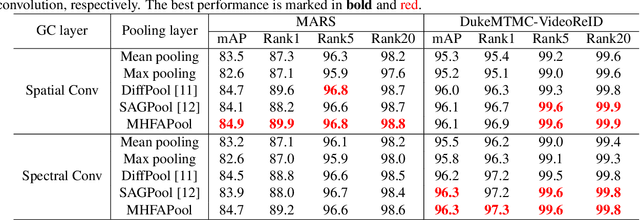
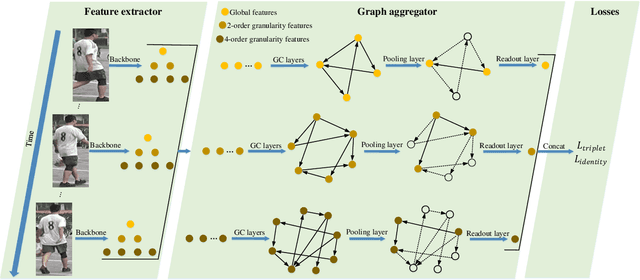
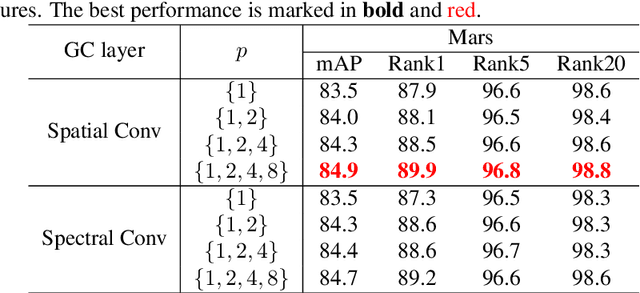
The video-based person re-identification (ReID) aims to identify the given pedestrian video sequence across multiple non-overlapping cameras. To aggregate the temporal and spatial features of the video samples, the graph neural networks (GNNs) are introduced. However, existing graph-based models, like STGCN, perform the \textit{mean}/\textit{max pooling} on node features to obtain the graph representation, which neglect the graph topology and node importance. In this paper, we propose the graph pooling network (GPNet) to learn the multi-granularity graph representation for the video retrieval, where the \textit{graph pooling layer} is implemented to downsample the graph. We first construct a multi-granular graph, whose node features denote image embedding learned by backbone, and edges are established between the temporal and Euclidean neighborhood nodes. We then implement multiple graph convolutional layers to perform the neighborhood aggregation on the graphs. To downsample the graph, we propose a multi-head full attention graph pooling (MHFAPool) layer, which integrates the advantages of existing node clustering and node selection pooling methods. Specifically, MHFAPool takes the main eigenvector of full attention matrix as the aggregation coefficients to involve the global graph information in each pooled nodes. Extensive experiments demonstrate that our GPNet achieves the competitive results on four widely-used datasets, i.e., MARS, DukeMTMC-VideoReID, iLIDS-VID and PRID-2011.