 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Speech ReaLLM -- Real-time Streaming Speech Recognition with Multimodal LLMs by Teaching the Flow of Time
Jun 13, 2024We introduce Speech ReaLLM, a new ASR architecture that marries "decoder-only" ASR with the RNN-T to make multimodal LLM architectures capable of real-time streaming. This is the first "decoder-only" ASR architecture designed to handle continuous audio without explicit end-pointing. Speech ReaLLM is a special case of the more general ReaLLM ("real-time LLM") approach, also introduced here for the first time. The idea is inspired by RNN-T: Instead of generating a response only at the end of a user prompt, generate after every input token received in real time (it is often empty). On Librispeech "test", an 80M Speech ReaLLM achieves WERs of 3.0% and 7.4% in real time (without an external LM or auxiliary loss). This is only slightly above a 3x larger Attention-Encoder-Decoder baseline. We also show that this way, an LLM architecture can learn to represent and reproduce the flow of time; and that a pre-trained 7B LLM can be fine-tuned to do reasonably well on this task.
SynthVSR: Scaling Up Visual Speech Recognition With Synthetic Supervision
Apr 03, 2023Recently reported state-of-the-art results in visual speech recognition (VSR) often rely on increasingly large amounts of video data, while the publicly available transcribed video datasets are limited in size. In this paper, for the first time, we study the potential of leveraging synthetic visual data for VSR. Our method, termed SynthVSR, substantially improves the performance of VSR systems with synthetic lip movements. The key idea behind SynthVSR is to leverage a speech-driven lip animation model that generates lip movements conditioned on the input speech. The speech-driven lip animation model is trained on an unlabeled audio-visual dataset and could be further optimized towards a pre-trained VSR model when labeled videos are available. As plenty of transcribed acoustic data and face images are available, we are able to generate large-scale synthetic data using the proposed lip animation model for semi-supervised VSR training. We evaluate the performance of our approach on the largest public VSR benchmark - Lip Reading Sentences 3 (LRS3). SynthVSR achieves a WER of 43.3% with only 30 hours of real labeled data, outperforming off-the-shelf approaches using thousands of hours of video. The WER is further reduced to 27.9% when using all 438 hours of labeled data from LRS3, which is on par with the state-of-the-art self-supervised AV-HuBERT method. Furthermore, when combined with large-scale pseudo-labeled audio-visual data SynthVSR yields a new state-of-the-art VSR WER of 16.9% using publicly available data only, surpassing the recent state-of-the-art approaches trained with 29 times more non-public machine-transcribed video data (90,000 hours). Finally, we perform extensive ablation studies to understand the effect of each component in our proposed method.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021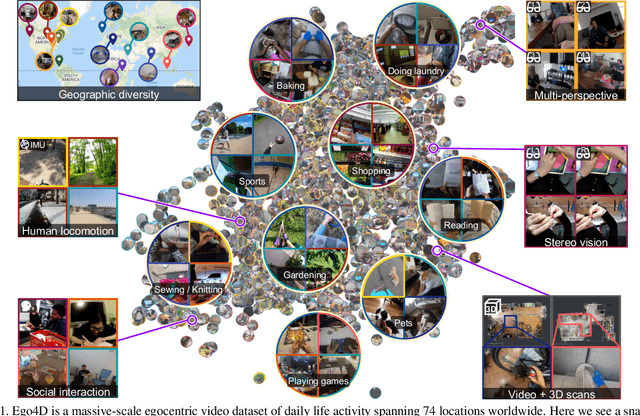
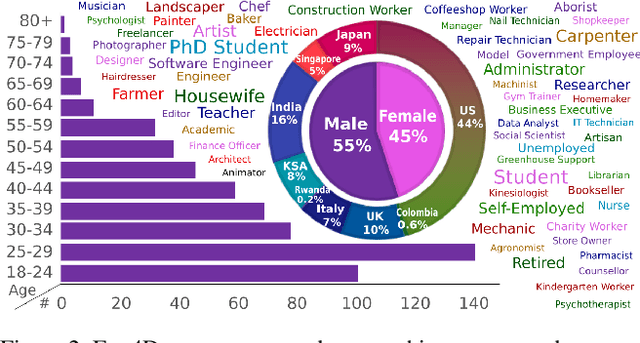

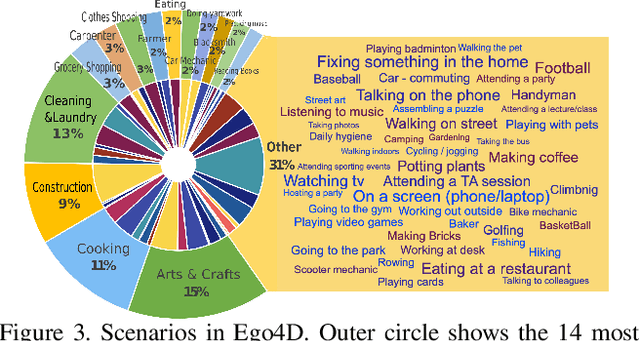
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/