 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
Llama Guard 3-1B-INT4: Compact and Efficient Safeguard for Human-AI Conversations
Nov 18, 2024This paper presents Llama Guard 3-1B-INT4, a compact and efficient Llama Guard model, which has been open-sourced to the community during Meta Connect 2024. We demonstrate that Llama Guard 3-1B-INT4 can be deployed on resource-constrained devices, achieving a throughput of at least 30 tokens per second and a time-to-first-token of 2.5 seconds or less on a commodity Android mobile CPU. Notably, our experiments show that Llama Guard 3-1B-INT4 attains comparable or superior safety moderation scores to its larger counterpart, Llama Guard 3-1B, despite being approximately 7 times smaller in size (440MB).
Serdab: An IoT Framework for Partitioning Neural Networks Computation across Multiple Enclaves
May 12, 2020


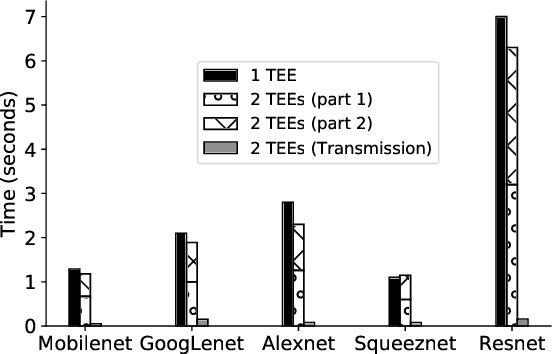
Recent advances in Deep Neural Networks (DNN) and Edge Computing have made it possible to automatically analyze streams of videos from home/security cameras over hierarchical clusters that include edge devices, close to the video source, as well as remote cloud compute resources. However, preserving the privacy and confidentiality of users' sensitive data as it passes through different devices remains a concern to most users. Private user data is subject to attacks by malicious attackers or misuse by internal administrators who may use the data in activities that are not explicitly approved by the user. To address this challenge, we present Serdab, a distributed orchestration framework for deploying deep neural network computation across multiple secure enclaves (e.g., Intel SGX). Secure enclaves provide a guarantee on the privacy of the data/code deployed inside it. However, their limited hardware resources make them inefficient when solely running an entire deep neural network. To bridge this gap, Serdab presents a DNN partitioning strategy to distribute the layers of the neural network across multiple enclave devices or across an enclave device and other hardware accelerators. Our partitioning strategy achieves up to 4.7x speedup compared to executing the entire neural network in one enclave.
Analysis of PCA Algorithms in Distributed Environments
May 13, 2015

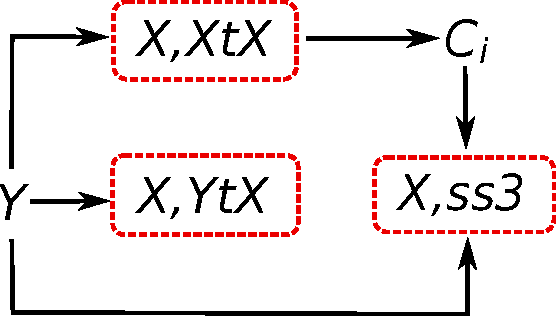
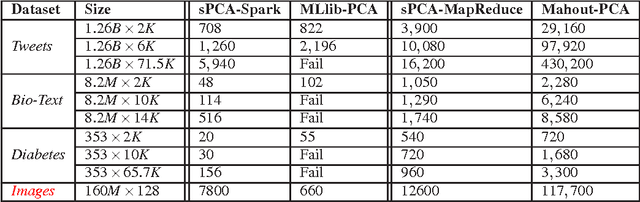
Classical machine learning algorithms often face scalability bottlenecks when they are applied to large-scale data. Such algorithms were designed to work with small data that is assumed to fit in the memory of one machine. In this report, we analyze different methods for computing an important machine learing algorithm, namely Principal Component Analysis (PCA), and we comment on its limitations in supporting large datasets. The methods are analyzed and compared across two important metrics: time complexity and communication complexity. We consider the worst-case scenarios for both metrics, and we identify the software libraries that implement each method. The analysis in this report helps researchers and engineers in (i) understanding the main bottlenecks for scalability in different PCA algorithms, (ii) choosing the most appropriate method and software library for a given application and data set characteristics, and (iii) designing new scalable PCA algorithms.