 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlmieyar-Oryx-BloomBench: A Bilingual Multimodal Benchmark for Cognitively Informed Evaluation of Vision-Language Models
Jun 04, 2026Despite the rapid progress of Vision-Language Models (VLMs), the field lacks benchmarks that rigorously diagnose their true reasoning abilities and chart meaningful progress toward human-like multimodal intelligence. Most existing evaluations focus on piecemeal or disconnected tasks, obscuring critical cognitive weaknesses and providing little insight for targeted improvement. To address this gap, we introduce BloomBench, part of the Almieyar benchmarking series, the first cognitively human-grounded, bilingual (English-Arabic) multimodal benchmark for VLMs. Grounded in Bloom's Taxonomy, BloomBench systematically evaluates six levels of cognition (Remember, Understand, Apply, Analyze, Evaluate, Create) through carefully designed image-question-answer tasks. Built with a semi-automated pipeline and validated through a stratified hybrid quality assurance protocol, it ensures scalability, cultural inclusivity, and linguistic fidelity. Leveraging this framework, we conduct a comprehensive study of state-of-the-art VLMs to diagnose their cognitive profiles. Our analysis reveals a sharp cognitive asymmetry: while state-of-the-art models achieve strong performance ceilings in semantic understanding, they struggle substantially with factual recall and creative synthesis. This demonstrates that current general multimodal proficiency masks deeper limitations in specific cognitive layers. Furthermore, our study highlights a critical performance gap between Arabic and English, exposing limitations in current cross-lingual multimodal reasoning. These findings establish a foundation for developing more cognitively aligned and inclusive VLMs. The benchmark framework and dataset is available at: https://github.com/qcri/Almieyar-Oryx-BloomBench.
Fanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
User-assisted Video Reflection Removal
Sep 07, 2020


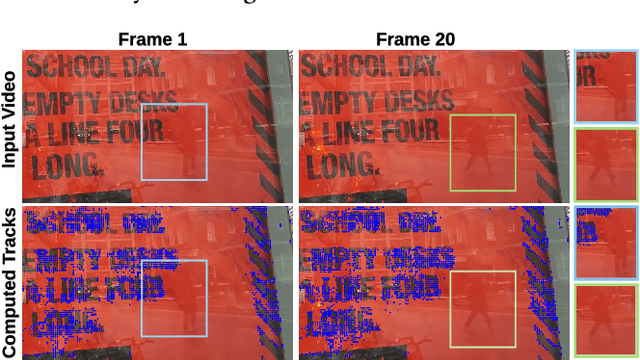
Reflections in videos are obstructions that often occur when videos are taken behind reflective surfaces like glass. These reflections reduce the quality of such videos, lead to information loss and degrade the accuracy of many computer vision algorithms. A video containing reflections is a combination of background and reflection layers. Thus, reflection removal is equivalent to decomposing the video into two layers. This, however, is a challenging and ill-posed problem as there is an infinite number of valid decompositions. To address this problem, we propose a user-assisted method for video reflection removal. We rely on both spatial and temporal information and utilize sparse user hints to help improve separation. The key idea of the proposed method is to use motion cues to separate the background layer from the reflection layer with minimal user assistance. We show that user-assistance significantly improves the layer separation results. We implement and evaluate the proposed method through quantitative and qualitative results on real and synthetic videos. Our experiments show that the proposed method successfully removes reflection from video sequences, does not introduce visual distortions, and significantly outperforms the state-of-the-art reflection removal methods in the literature.
Unsupervised Single-Image Reflection Separation Using Perceptual Deep Image Priors
Sep 01, 2020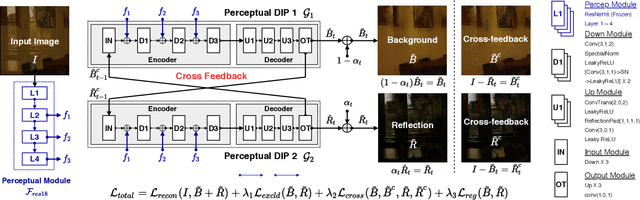
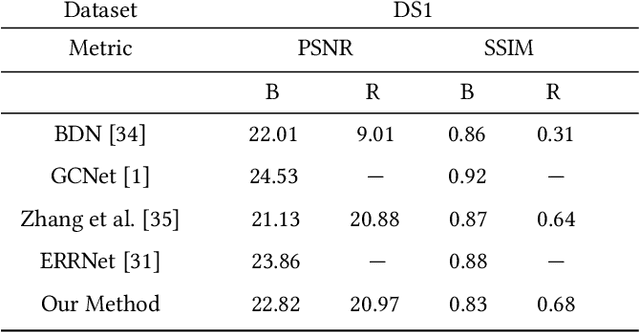

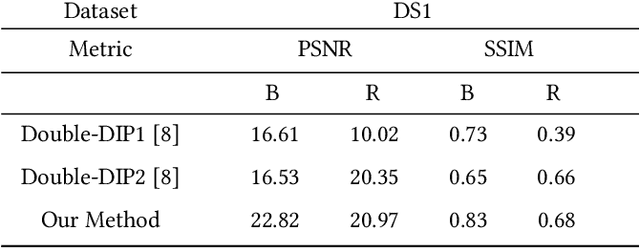
Reflections often degrade the quality of the image by obstructing the background scene. This is not desirable for everyday users, and it negatively impacts the performance of multimedia applications that process images with reflections. Most current methods for removing reflections utilize supervised-learning models. However, these models require an extensive number of image pairs to perform well, especially on natural images with reflection, which is difficult to achieve in practice. In this paper, we propose a novel unsupervised framework for single-image reflection separation. Instead of learning from a large dataset, we optimize the parameters of two cross-coupled deep convolutional networks on a target image to generate two exclusive background and reflection layers. In particular, we design a new architecture of the network to embed semantic features extracted from a pre-trained deep classification network, which gives more meaningful separation similar to human perception. Quantitative and qualitative results on commonly used datasets in the literature show that our method's performance is at least on par with the state-of-the-art supervised methods and, occasionally, better without requiring large training datasets. Our results also show that our method significantly outperforms the closest unsupervised method in the literature for removing reflections from single images.
Efficient and Scalable View Generation from a Single Image using Fully Convolutional Networks
Oct 20, 2018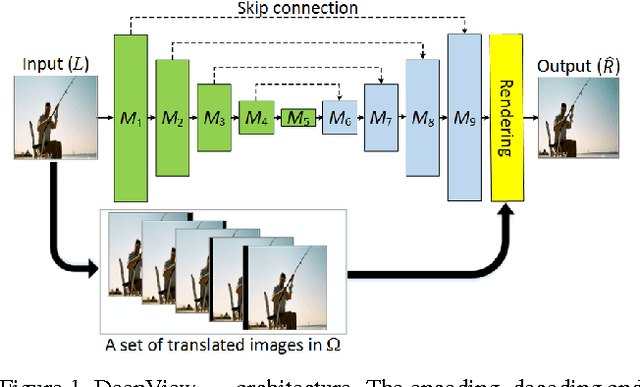



Single-image-based view generation (SIVG) is important for producing 3D stereoscopic content. Here, handling different spatial resolutions as input and optimizing both reconstruction accuracy and processing speed is desirable. Latest approaches are based on convolutional neural network (CNN), and they generate promising results. However, their use of fully connected layers as well as pre-trained VGG forces a compromise between reconstruction accuracy and processing speed. In addition, this approach is limited to the use of a specific spatial resolution. To remedy these problems, we propose exploiting fully convolutional networks (FCN) for SIVG. We present two FCN architectures for SIVG. The first one is based on combination of an FCN and a view-rendering network called DeepView$_{ren}$. The second one consists of decoupled networks for luminance and chrominance signals, denoted by DeepView$_{dec}$. To train our solutions we present a large dataset of 2M stereoscopic images. Results show that both of our architectures improve accuracy and speed over the state of the art. DeepView$_{ren}$ generates competitive accuracy to the state of the art, however, with the fastest processing speed of all. That is x5 times faster speed and x24 times lower memory consumption compared to the state of the art. DeepView$_{dec}$ has much higher accuracy, but with x2.5 times faster speed and x12 times lower memory consumption. We evaluated our approach with both objective and subjective studies.
Large-scale, Fast and Accurate Shot Boundary Detection through Spatio-temporal Convolutional Neural Networks
Jul 27, 2017
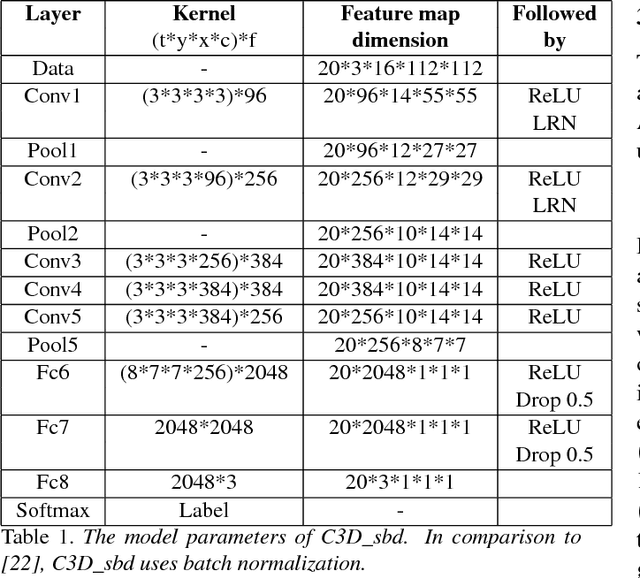
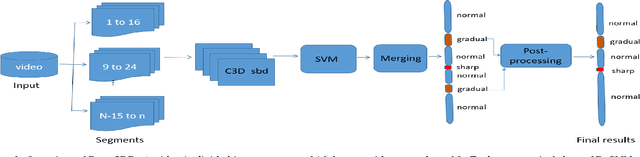
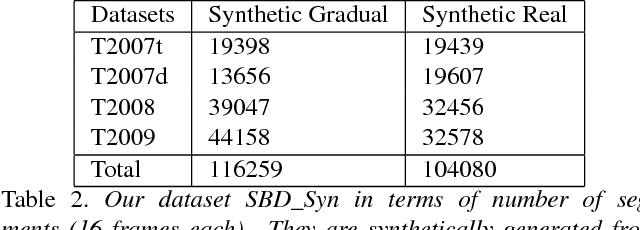
Shot boundary detection (SBD) is an important pre-processing step for video manipulation. Here, each segment of frames is classified as either sharp, gradual or no transition. Current SBD techniques analyze hand-crafted features and attempt to optimize both detection accuracy and processing speed. However, the heavy computations of optical flow prevents this. To achieve this aim, we present an SBD technique based on spatio-temporal Convolutional Neural Networks (CNN). Since current datasets are not large enough to train an accurate SBD CNN, we present a new dataset containing more than 3.5 million frames of sharp and gradual transitions. The transitions are generated synthetically using image compositing models. Our dataset contain additional 70,000 frames of important hard-negative no transitions. We perform the largest evaluation to date for one SBD algorithm, on real and synthetic data, containing more than 4.85 million frames. In comparison to the state of the art, we outperform dissolve gradual detection, generate competitive performance for sharp detections and produce significant improvement in wipes. In addition, we are up to 11 times faster than the state of the art.
Analysis of PCA Algorithms in Distributed Environments
May 13, 2015

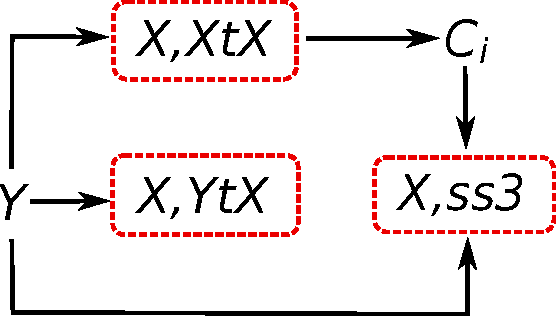
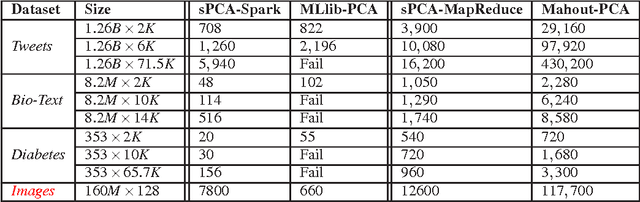
Classical machine learning algorithms often face scalability bottlenecks when they are applied to large-scale data. Such algorithms were designed to work with small data that is assumed to fit in the memory of one machine. In this report, we analyze different methods for computing an important machine learing algorithm, namely Principal Component Analysis (PCA), and we comment on its limitations in supporting large datasets. The methods are analyzed and compared across two important metrics: time complexity and communication complexity. We consider the worst-case scenarios for both metrics, and we identify the software libraries that implement each method. The analysis in this report helps researchers and engineers in (i) understanding the main bottlenecks for scalability in different PCA algorithms, (ii) choosing the most appropriate method and software library for a given application and data set characteristics, and (iii) designing new scalable PCA algorithms.