 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-assisted Video Reflection Removal
Sep 07, 2020


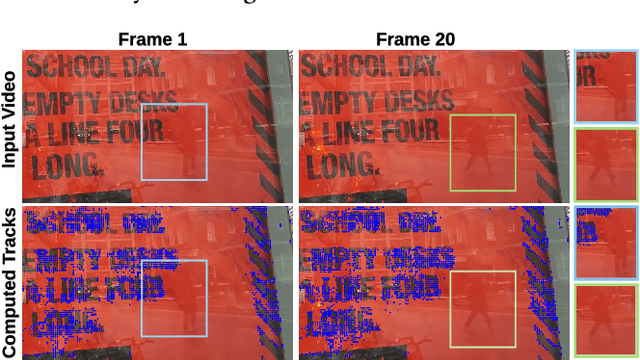
Reflections in videos are obstructions that often occur when videos are taken behind reflective surfaces like glass. These reflections reduce the quality of such videos, lead to information loss and degrade the accuracy of many computer vision algorithms. A video containing reflections is a combination of background and reflection layers. Thus, reflection removal is equivalent to decomposing the video into two layers. This, however, is a challenging and ill-posed problem as there is an infinite number of valid decompositions. To address this problem, we propose a user-assisted method for video reflection removal. We rely on both spatial and temporal information and utilize sparse user hints to help improve separation. The key idea of the proposed method is to use motion cues to separate the background layer from the reflection layer with minimal user assistance. We show that user-assistance significantly improves the layer separation results. We implement and evaluate the proposed method through quantitative and qualitative results on real and synthetic videos. Our experiments show that the proposed method successfully removes reflection from video sequences, does not introduce visual distortions, and significantly outperforms the state-of-the-art reflection removal methods in the literature.
FAT ALBERT: Finding Answers in Large Texts using Semantic Similarity Attention Layer based on BERT
Aug 22, 2020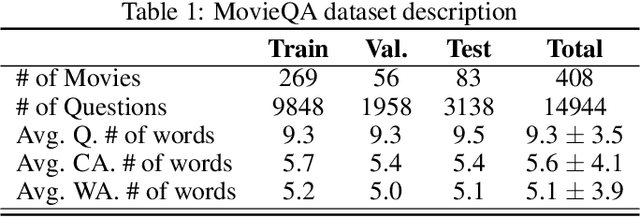

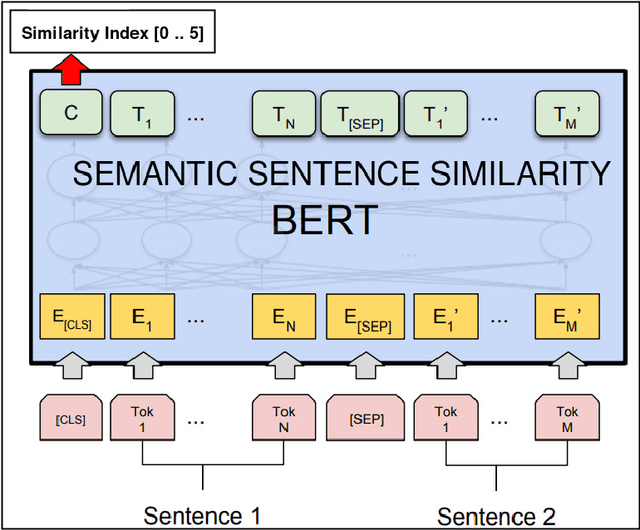

Machine based text comprehension has always been a significant research field in natural language processing. Once a full understanding of the text context and semantics is achieved, a deep learning model can be trained to solve a large subset of tasks, e.g. text summarization, classification and question answering. In this paper we focus on the question answering problem, specifically the multiple choice type of questions. We develop a model based on BERT, a state-of-the-art transformer network. Moreover, we alleviate the ability of BERT to support large text corpus by extracting the highest influence sentences through a semantic similarity model. Evaluations of our proposed model demonstrate that it outperforms the leading models in the MovieQA challenge and we are currently ranked first in the leader board with test accuracy of 87.79%. Finally, we discuss the model shortcomings and suggest possible improvements to overcome these limitations.