 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAT ALBERT: Finding Answers in Large Texts using Semantic Similarity Attention Layer based on BERT
Aug 22, 2020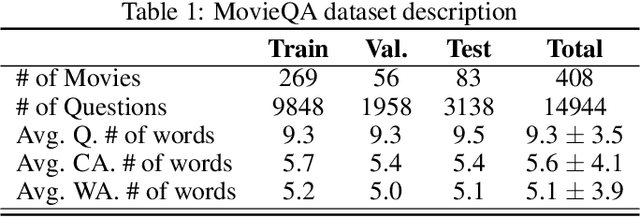

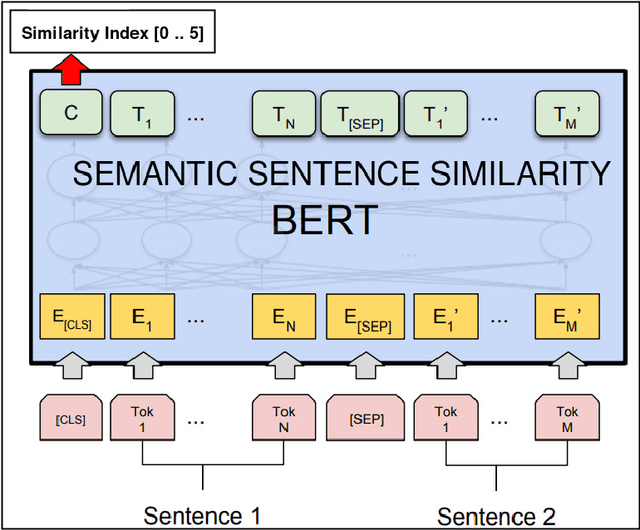

Machine based text comprehension has always been a significant research field in natural language processing. Once a full understanding of the text context and semantics is achieved, a deep learning model can be trained to solve a large subset of tasks, e.g. text summarization, classification and question answering. In this paper we focus on the question answering problem, specifically the multiple choice type of questions. We develop a model based on BERT, a state-of-the-art transformer network. Moreover, we alleviate the ability of BERT to support large text corpus by extracting the highest influence sentences through a semantic similarity model. Evaluations of our proposed model demonstrate that it outperforms the leading models in the MovieQA challenge and we are currently ranked first in the leader board with test accuracy of 87.79%. Finally, we discuss the model shortcomings and suggest possible improvements to overcome these limitations.