 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-assisted Video Reflection Removal
Sep 07, 2020


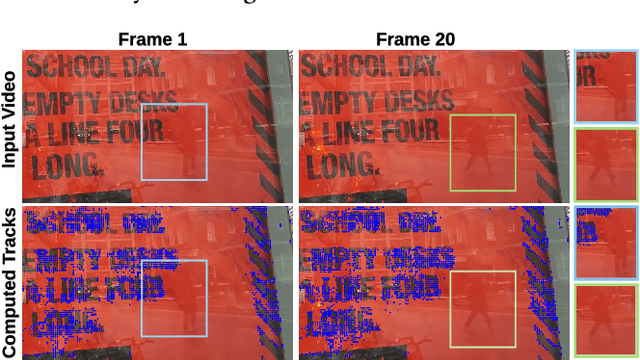
Reflections in videos are obstructions that often occur when videos are taken behind reflective surfaces like glass. These reflections reduce the quality of such videos, lead to information loss and degrade the accuracy of many computer vision algorithms. A video containing reflections is a combination of background and reflection layers. Thus, reflection removal is equivalent to decomposing the video into two layers. This, however, is a challenging and ill-posed problem as there is an infinite number of valid decompositions. To address this problem, we propose a user-assisted method for video reflection removal. We rely on both spatial and temporal information and utilize sparse user hints to help improve separation. The key idea of the proposed method is to use motion cues to separate the background layer from the reflection layer with minimal user assistance. We show that user-assistance significantly improves the layer separation results. We implement and evaluate the proposed method through quantitative and qualitative results on real and synthetic videos. Our experiments show that the proposed method successfully removes reflection from video sequences, does not introduce visual distortions, and significantly outperforms the state-of-the-art reflection removal methods in the literature.
Unsupervised Single-Image Reflection Separation Using Perceptual Deep Image Priors
Sep 01, 2020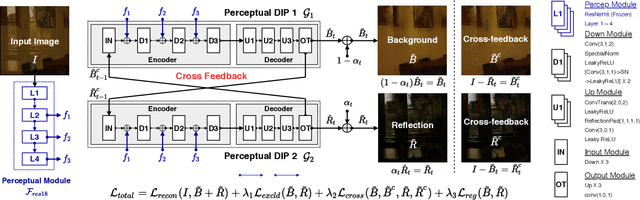
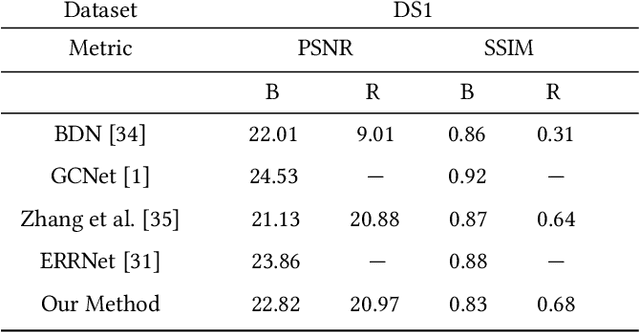

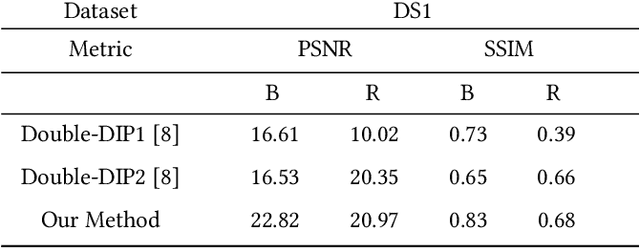
Reflections often degrade the quality of the image by obstructing the background scene. This is not desirable for everyday users, and it negatively impacts the performance of multimedia applications that process images with reflections. Most current methods for removing reflections utilize supervised-learning models. However, these models require an extensive number of image pairs to perform well, especially on natural images with reflection, which is difficult to achieve in practice. In this paper, we propose a novel unsupervised framework for single-image reflection separation. Instead of learning from a large dataset, we optimize the parameters of two cross-coupled deep convolutional networks on a target image to generate two exclusive background and reflection layers. In particular, we design a new architecture of the network to embed semantic features extracted from a pre-trained deep classification network, which gives more meaningful separation similar to human perception. Quantitative and qualitative results on commonly used datasets in the literature show that our method's performance is at least on par with the state-of-the-art supervised methods and, occasionally, better without requiring large training datasets. Our results also show that our method significantly outperforms the closest unsupervised method in the literature for removing reflections from single images.