 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of PCA Algorithms in Distributed Environments
Paper and Code
May 13, 2015

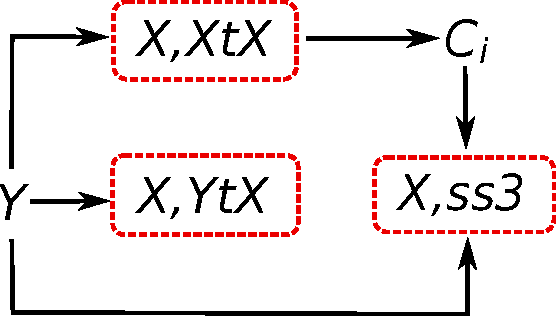
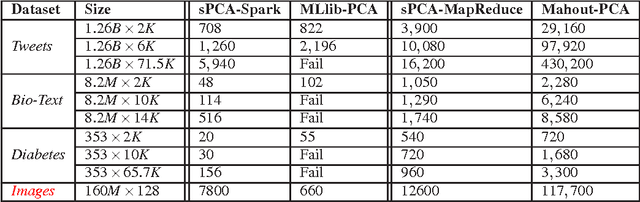
Classical machine learning algorithms often face scalability bottlenecks when they are applied to large-scale data. Such algorithms were designed to work with small data that is assumed to fit in the memory of one machine. In this report, we analyze different methods for computing an important machine learing algorithm, namely Principal Component Analysis (PCA), and we comment on its limitations in supporting large datasets. The methods are analyzed and compared across two important metrics: time complexity and communication complexity. We consider the worst-case scenarios for both metrics, and we identify the software libraries that implement each method. The analysis in this report helps researchers and engineers in (i) understanding the main bottlenecks for scalability in different PCA algorithms, (ii) choosing the most appropriate method and software library for a given application and data set characteristics, and (iii) designing new scalable PCA algorithms.