 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Scalable View Generation from a Single Image using Fully Convolutional Networks
Paper and Code
Oct 20, 2018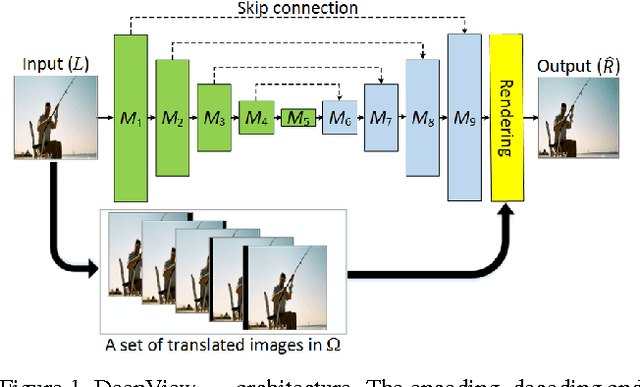



Single-image-based view generation (SIVG) is important for producing 3D stereoscopic content. Here, handling different spatial resolutions as input and optimizing both reconstruction accuracy and processing speed is desirable. Latest approaches are based on convolutional neural network (CNN), and they generate promising results. However, their use of fully connected layers as well as pre-trained VGG forces a compromise between reconstruction accuracy and processing speed. In addition, this approach is limited to the use of a specific spatial resolution. To remedy these problems, we propose exploiting fully convolutional networks (FCN) for SIVG. We present two FCN architectures for SIVG. The first one is based on combination of an FCN and a view-rendering network called DeepView$_{ren}$. The second one consists of decoupled networks for luminance and chrominance signals, denoted by DeepView$_{dec}$. To train our solutions we present a large dataset of 2M stereoscopic images. Results show that both of our architectures improve accuracy and speed over the state of the art. DeepView$_{ren}$ generates competitive accuracy to the state of the art, however, with the fastest processing speed of all. That is x5 times faster speed and x24 times lower memory consumption compared to the state of the art. DeepView$_{dec}$ has much higher accuracy, but with x2.5 times faster speed and x12 times lower memory consumption. We evaluated our approach with both objective and subjective studies.