 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNUBIA: NeUral Based Interchangeability Assessor for Text Generation
May 01, 2020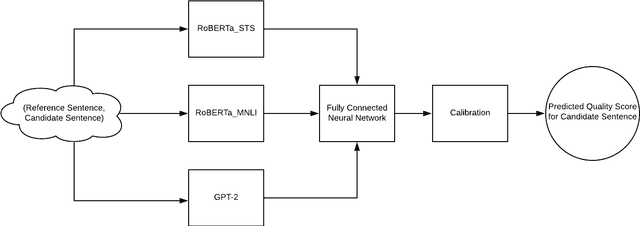


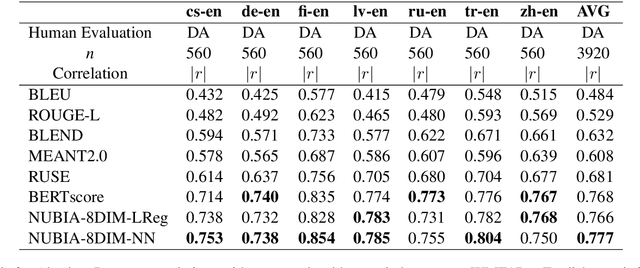
We present NUBIA, a methodology to build automatic evaluation metrics for text generation using only machine learning models as core components. A typical NUBIA model is composed of three modules: a neural feature extractor, an aggregator and a calibrator. We demonstrate an implementation of NUBIA which outperforms metrics currently used to evaluate machine translation, summaries and slightly exceeds/matches state of the art metrics on correlation with human judgement on the WMT segment-level Direct Assessment task, sentence-level ranking and image captioning evaluation. The model implemented is modular, explainable and set to continuously improve over time.
Towards Neural Language Evaluators
Oct 30, 2019We review three limitations of BLEU and ROUGE -- the most popular metrics used to assess reference summaries against hypothesis summaries, come up with criteria for what a good metric should behave like and propose concrete ways to use recent Transformers-based Language Models to assess reference summaries against hypothesis summaries.