 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Disaster Damage Assessment in Satellite Imagery with Multi-Temporal Fusion
Apr 12, 2020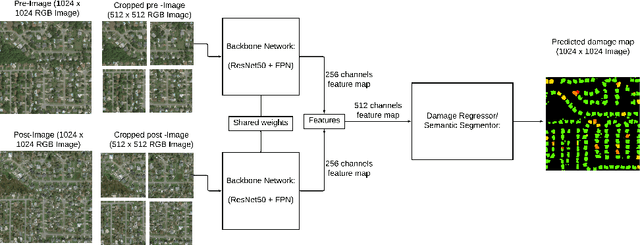


Automatic change detection and disaster damage assessment are currently procedures requiring a huge amount of labor and manual work by satellite imagery analysts. In the occurrences of natural disasters, timely change detection can save lives. In this work, we report findings on problem framing, data processing and training procedures which are specifically helpful for the task of building damage assessment using the newly released xBD dataset. Our insights lead to substantial improvement over the xBD baseline models, and we score among top results on the xView2 challenge leaderboard. We release our code used for the competition.
Towards Neural Language Evaluators
Oct 30, 2019We review three limitations of BLEU and ROUGE -- the most popular metrics used to assess reference summaries against hypothesis summaries, come up with criteria for what a good metric should behave like and propose concrete ways to use recent Transformers-based Language Models to assess reference summaries against hypothesis summaries.
AWE-CM Vectors: Augmenting Word Embeddings with a Clinical Metathesaurus
Dec 05, 2017
In recent years, word embeddings have been surprisingly effective at capturing intuitive characteristics of the words they represent. These vectors achieve the best results when training corpora are extremely large, sometimes billions of words. Clinical natural language processing datasets, however, tend to be much smaller. Even the largest publicly-available dataset of medical notes is three orders of magnitude smaller than the dataset of the oft-used "Google News" word vectors. In order to make up for limited training data sizes, we encode expert domain knowledge into our embeddings. Building on a previous extension of word2vec, we show that generalizing the notion of a word's "context" to include arbitrary features creates an avenue for encoding domain knowledge into word embeddings. We show that the word vectors produced by this method outperform their text-only counterparts across the board in correlation with clinical experts.