 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Domain-Specific LLMs Faithful To The Islamic Worldview: Mirage or Technical Possibility?
Dec 11, 2023Large Language Models (LLMs) have demonstrated remarkable performance across numerous natural language understanding use cases. However, this impressive performance comes with inherent limitations, such as the tendency to perpetuate stereotypical biases or fabricate non-existent facts. In the context of Islam and its representation, accurate and factual representation of its beliefs and teachings rooted in the Quran and Sunnah is key. This work focuses on the challenge of building domain-specific LLMs faithful to the Islamic worldview and proposes ways to build and evaluate such systems. Firstly, we define this open-ended goal as a technical problem and propose various solutions. Subsequently, we critically examine known challenges inherent to each approach and highlight evaluation methodologies that can be used to assess such systems. This work highlights the need for high-quality datasets, evaluations, and interdisciplinary work blending machine learning with Islamic scholarship.
NUBIA: NeUral Based Interchangeability Assessor for Text Generation
May 01, 2020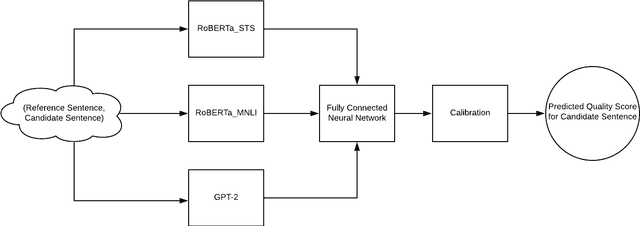


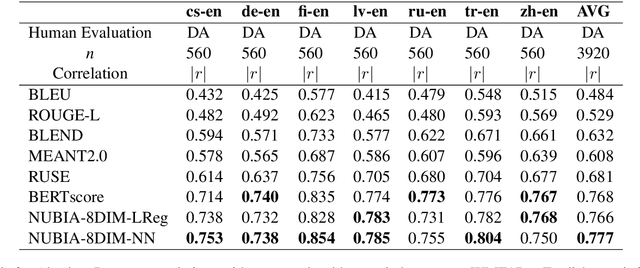
We present NUBIA, a methodology to build automatic evaluation metrics for text generation using only machine learning models as core components. A typical NUBIA model is composed of three modules: a neural feature extractor, an aggregator and a calibrator. We demonstrate an implementation of NUBIA which outperforms metrics currently used to evaluate machine translation, summaries and slightly exceeds/matches state of the art metrics on correlation with human judgement on the WMT segment-level Direct Assessment task, sentence-level ranking and image captioning evaluation. The model implemented is modular, explainable and set to continuously improve over time.