 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilDIRE: A Small, Fast, Cheap and Lightweight Diffusion Synthesized Deepfake Detection
Jun 02, 2024A dramatic influx of diffusion-generated images has marked recent years, posing unique challenges to current detection technologies. While the task of identifying these images falls under binary classification, a seemingly straightforward category, the computational load is significant when employing the "reconstruction then compare" technique. This approach, known as DIRE (Diffusion Reconstruction Error), not only identifies diffusion-generated images but also detects those produced by GANs, highlighting the technique's broad applicability. To address the computational challenges and improve efficiency, we propose distilling the knowledge embedded in diffusion models to develop rapid deepfake detection models. Our approach, aimed at creating a small, fast, cheap, and lightweight diffusion synthesized deepfake detector, maintains robust performance while significantly reducing operational demands. Maintaining performance, our experimental results indicate an inference speed 3.2 times faster than the existing DIRE framework. This advance not only enhances the practicality of deploying these systems in real-world settings but also paves the way for future research endeavors that seek to leverage diffusion model knowledge.
Scalable Object Detection on Embedded Devices Using Weight Pruning and Singular Value Decomposition
Mar 17, 2023
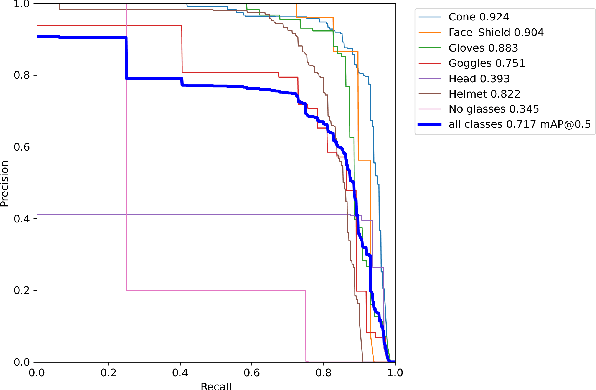
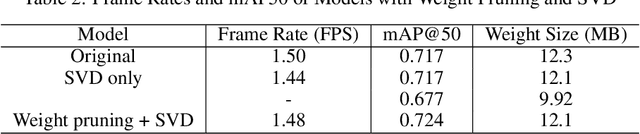
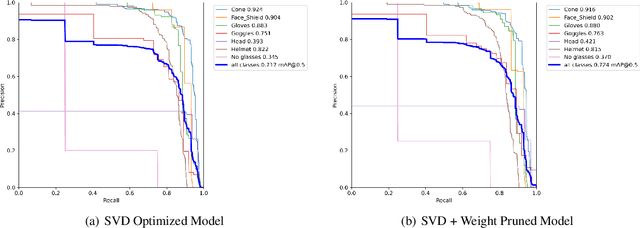
This paper presents a method for optimizing object detection models by combining weight pruning and singular value decomposition (SVD). The proposed method was evaluated on a custom dataset of street work images obtained from https://universe.roboflow.com/roboflow-100/street-work. The dataset consists of 611 training images, 175 validation images, and 87 test images with 7 classes. We compared the performance of the optimized models with the original unoptimized model in terms of frame rate, mean average precision (mAP@50), and weight size. The results show that the weight pruning + SVD model achieved a 0.724 mAP@50 with a frame rate of 1.48 FPS and a weight size of 12.1 MB, outperforming the original model (0.717 mAP@50, 1.50 FPS, and 12.3 MB). Precision-recall curves were also plotted for all models. Our work demonstrates that the proposed method can effectively optimize object detection models while balancing accuracy, speed, and model size.