 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMORDA: A Synthetic Dataset to Facilitate Adaptation of Object Detectors to Unseen Real-target Domain While Preserving Performance on Real-source Domain
Jan 09, 2025



Deep neural network (DNN) based perception models are indispensable in the development of autonomous vehicles (AVs). However, their reliance on large-scale, high-quality data is broadly recognized as a burdensome necessity due to the substantial cost of data acquisition and labeling. Further, the issue is not a one-time concern, as AVs might need a new dataset if they are to be deployed to another region (real-target domain) that the in-hand dataset within the real-source domain cannot incorporate. To mitigate this burden, we propose leveraging synthetic environments as an auxiliary domain where the characteristics of real domains are reproduced. This approach could enable indirect experience about the real-target domain in a time- and cost-effective manner. As a practical demonstration of our methodology, nuScenes and South Korea are employed to represent real-source and real-target domains, respectively. That means we construct digital twins for several regions of South Korea, and the data-acquisition framework of nuScenes is reproduced. Blending the aforementioned components within a simulator allows us to obtain a synthetic-fusion domain in which we forge our novel driving dataset, MORDA: Mixture Of Real-domain characteristics for synthetic-data-assisted Domain Adaptation. To verify the value of synthetic features that MORDA provides in learning about driving environments of South Korea, 2D/3D detectors are trained solely on a combination of nuScenes and MORDA. Afterward, their performance is evaluated on the unforeseen real-world dataset (AI-Hub) collected in South Korea. Our experiments present that MORDA can significantly improve mean Average Precision (mAP) on AI-Hub dataset while that on nuScenes is retained or slightly enhanced.
Scalable Object Detection on Embedded Devices Using Weight Pruning and Singular Value Decomposition
Mar 17, 2023
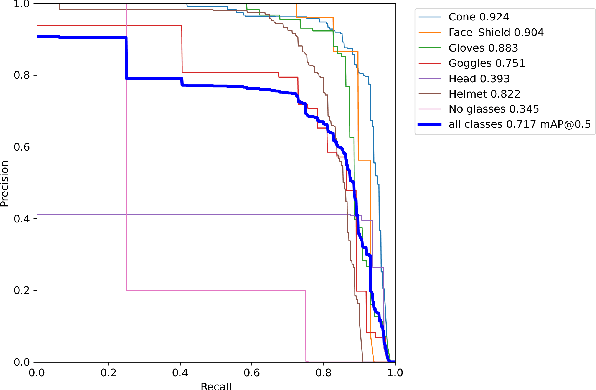
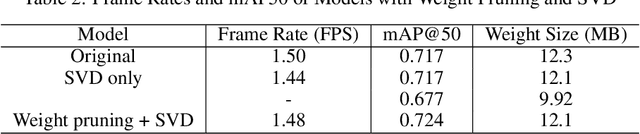
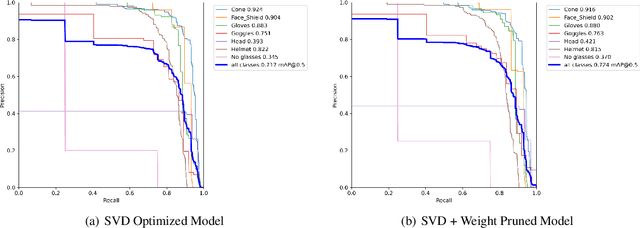
This paper presents a method for optimizing object detection models by combining weight pruning and singular value decomposition (SVD). The proposed method was evaluated on a custom dataset of street work images obtained from https://universe.roboflow.com/roboflow-100/street-work. The dataset consists of 611 training images, 175 validation images, and 87 test images with 7 classes. We compared the performance of the optimized models with the original unoptimized model in terms of frame rate, mean average precision (mAP@50), and weight size. The results show that the weight pruning + SVD model achieved a 0.724 mAP@50 with a frame rate of 1.48 FPS and a weight size of 12.1 MB, outperforming the original model (0.717 mAP@50, 1.50 FPS, and 12.3 MB). Precision-recall curves were also plotted for all models. Our work demonstrates that the proposed method can effectively optimize object detection models while balancing accuracy, speed, and model size.
Context-Based Trit-Plane Coding for Progressive Image Compression
Mar 13, 2023



Trit-plane coding enables deep progressive image compression, but it cannot use autoregressive context models. In this paper, we propose the context-based trit-plane coding (CTC) algorithm to achieve progressive compression more compactly. First, we develop the context-based rate reduction module to estimate trit probabilities of latent elements accurately and thus encode the trit-planes compactly. Second, we develop the context-based distortion reduction module to refine partial latent tensors from the trit-planes and improve the reconstructed image quality. Third, we propose a retraining scheme for the decoder to attain better rate-distortion tradeoffs. Extensive experiments show that CTC outperforms the baseline trit-plane codec significantly in BD-rate on the Kodak lossless dataset, while increasing the time complexity only marginally. Our codes are available at https://github.com/seungminjeon-github/CTC.
RD-Optimized Trit-Plane Coding of Deep Compressed Image Latent Tensors
Mar 25, 2022
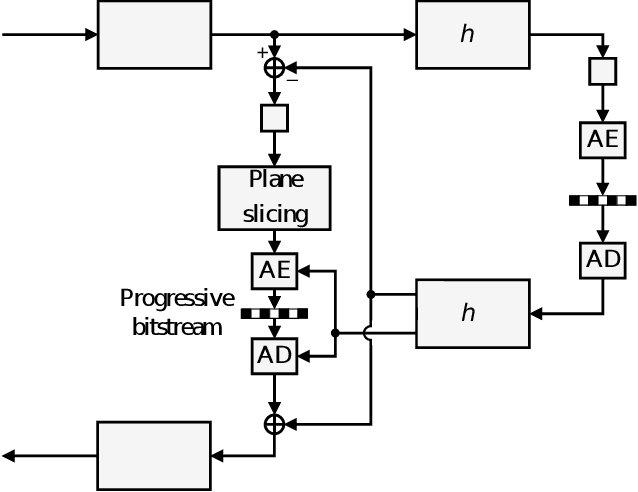
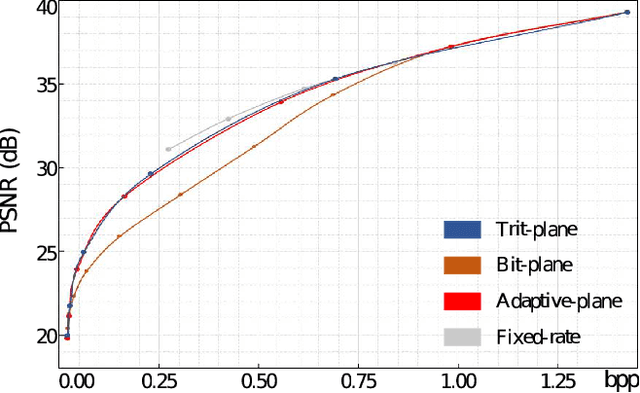

DPICT is the first learning-based image codec supporting fine granular scalability. In this paper, we describe how to implement two key components of DPICT efficiently: trit-plane slicing and RD-prioritized transmission. In DPICT, we transform an image into a latent tensor, represent the tensor in ternary digits (trits), and encode the trits in the decreasing order of significance. For entropy encoding, we should compute the probability of each trit, which demands high time complexity in both the encoder and the decoder. To reduce the complexity, we develop a parallel computing scheme for the probabilities and describe it in detail with pseudo-codes. Moreover, in this paper, we compare the trit-plane slicing in DPICT with the alternative bit-plane slicing. Experimental results show that the time complexity is reduced significantly by the parallel computing and that the trit-plane slicing provides better rate-distortion performances than the bit-plane slicing.
DPICT: Deep Progressive Image Compression Using Trit-Planes
Dec 12, 2021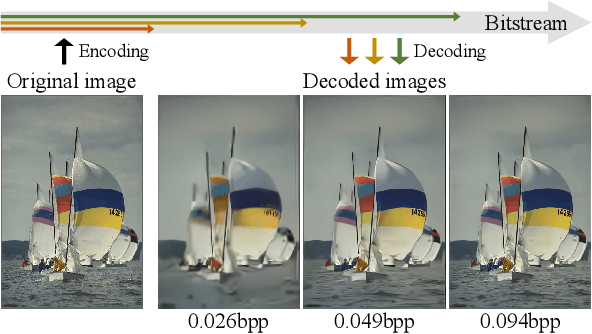
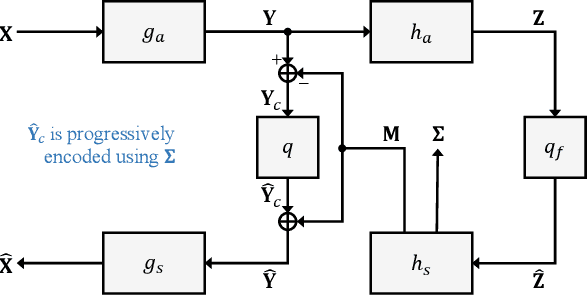
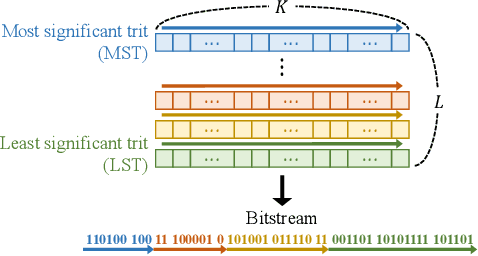
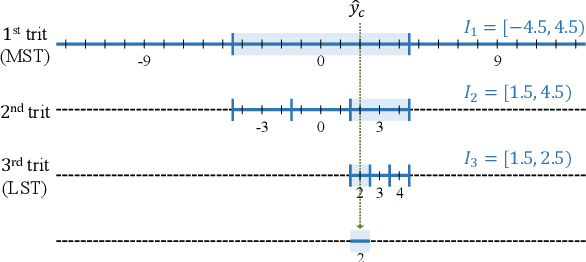
We propose the deep progressive image compression using trit-planes (DPICT) algorithm, which is the first learning-based codec supporting fine granular scalability (FGS). First, we transform an image into a latent tensor using an analysis network. Then, we represent the latent tensor in ternary digits (trits) and encode it into a compressed bitstream trit-plane by trit-plane in the decreasing order of significance. Moreover, within each trit-plane, we sort the trits according to their rate-distortion priorities and transmit more important information first. Since the compression network is less optimized for the cases of using fewer trit-planes, we develop a postprocessing network for refining reconstructed images at low rates. Experimental results show that DPICT outperforms conventional progressive codecs significantly, while enabling FGS transmission.