 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Spatial Propagation Network for Sparsity-Adaptive Depth Refinement
Apr 30, 2024The main function of depth completion is to compensate for an insufficient and unpredictable number of sparse depth measurements of hardware sensors. However, existing research on depth completion assumes that the sparsity -- the number of points or LiDAR lines -- is fixed for training and testing. Hence, the completion performance drops severely when the number of sparse depths changes significantly. To address this issue, we propose the sparsity-adaptive depth refinement (SDR) framework, which refines monocular depth estimates using sparse depth points. For SDR, we propose the masked spatial propagation network (MSPN) to perform SDR with a varying number of sparse depths effectively by gradually propagating sparse depth information throughout the entire depth map. Experimental results demonstrate that MPSN achieves state-of-the-art performance on both SDR and conventional depth completion scenarios.
Versatile Depth Estimator Based on Common Relative Depth Estimation and Camera-Specific Relative-to-Metric Depth Conversion
Mar 20, 2023



A typical monocular depth estimator is trained for a single camera, so its performance drops severely on images taken with different cameras. To address this issue, we propose a versatile depth estimator (VDE), composed of a common relative depth estimator (CRDE) and multiple relative-to-metric converters (R2MCs). The CRDE extracts relative depth information, and each R2MC converts the relative information to predict metric depths for a specific camera. The proposed VDE can cope with diverse scenes, including both indoor and outdoor scenes, with only a 1.12\% parameter increase per camera. Experimental results demonstrate that VDE supports multiple cameras effectively and efficiently and also achieves state-of-the-art performance in the conventional single-camera scenario.
Image Anomaly Detection and Localization with Position and Neighborhood Information
Nov 29, 2022Anomaly detection and localization are essential in many areas, where collecting enough anomalous samples for training is almost impossible. To overcome this difficulty, many existing methods use a pre-trained network to encode input images and non-parametric modeling to estimate the encoded feature distribution. In the modeling process, however, they overlook that position and neighborhood information affect the distribution of normal features. To use the information, in this paper, the normal distribution is estimated with conditional probability given neighborhood features, which is modeled with a multi-layer perceptron network. At the same time, positional information can be used by building a histogram of representative features at each position. While existing methods simply resize the anomaly map into the resolution of an input image, the proposed method uses an additional refine network that is trained from synthetic anomaly images to perform better interpolation considering the shape and edge of the input image. For the popular industrial dataset, MVTec AD benchmark, the experimental results show \textbf{99.52\%} and \textbf{98.91\%} AUROC scores in anomaly detection and localization, which is state-of-the-art performance.
Depth Map Decomposition for Monocular Depth Estimation
Aug 23, 2022
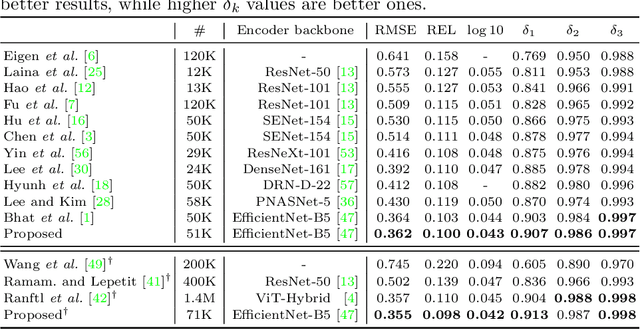
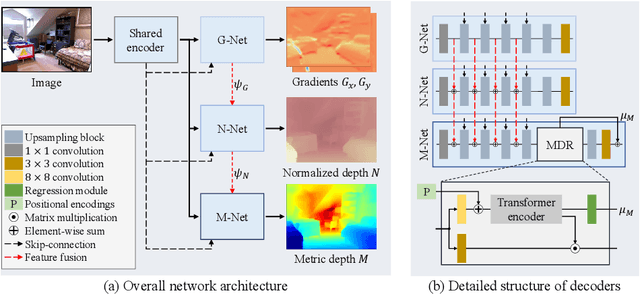
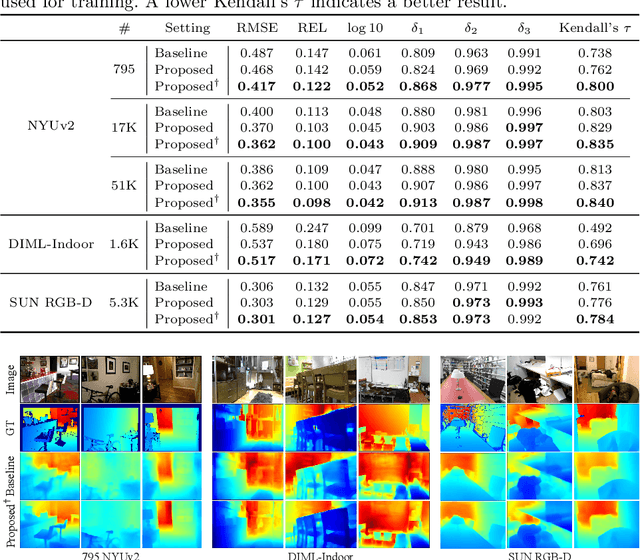
We propose a novel algorithm for monocular depth estimation that decomposes a metric depth map into a normalized depth map and scale features. The proposed network is composed of a shared encoder and three decoders, called G-Net, N-Net, and M-Net, which estimate gradient maps, a normalized depth map, and a metric depth map, respectively. M-Net learns to estimate metric depths more accurately using relative depth features extracted by G-Net and N-Net. The proposed algorithm has the advantage that it can use datasets without metric depth labels to improve the performance of metric depth estimation. Experimental results on various datasets demonstrate that the proposed algorithm not only provides competitive performance to state-of-the-art algorithms but also yields acceptable results even when only a small amount of metric depth data is available for its training.
RD-Optimized Trit-Plane Coding of Deep Compressed Image Latent Tensors
Mar 25, 2022
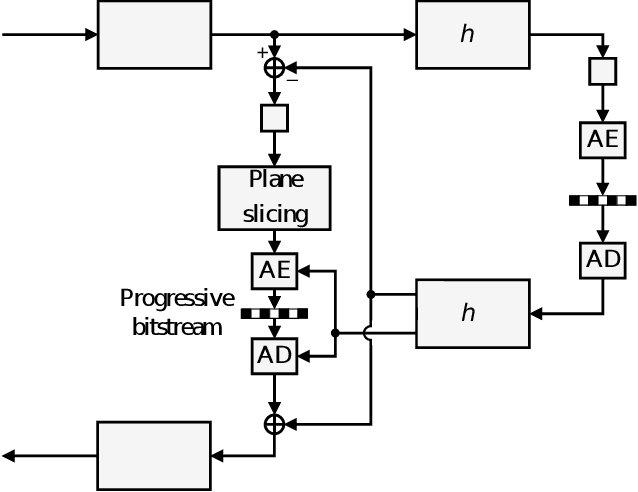
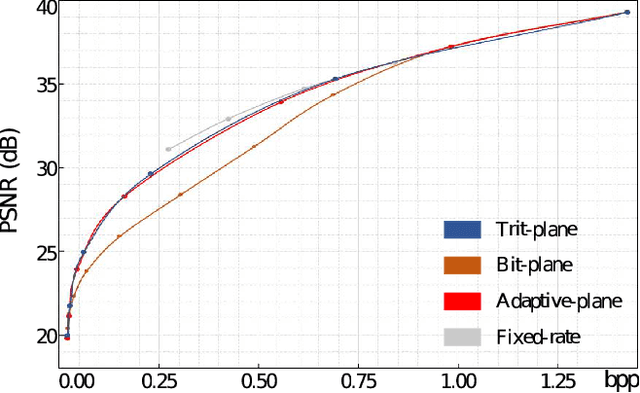

DPICT is the first learning-based image codec supporting fine granular scalability. In this paper, we describe how to implement two key components of DPICT efficiently: trit-plane slicing and RD-prioritized transmission. In DPICT, we transform an image into a latent tensor, represent the tensor in ternary digits (trits), and encode the trits in the decreasing order of significance. For entropy encoding, we should compute the probability of each trit, which demands high time complexity in both the encoder and the decoder. To reduce the complexity, we develop a parallel computing scheme for the probabilities and describe it in detail with pseudo-codes. Moreover, in this paper, we compare the trit-plane slicing in DPICT with the alternative bit-plane slicing. Experimental results show that the time complexity is reduced significantly by the parallel computing and that the trit-plane slicing provides better rate-distortion performances than the bit-plane slicing.
DPICT: Deep Progressive Image Compression Using Trit-Planes
Dec 12, 2021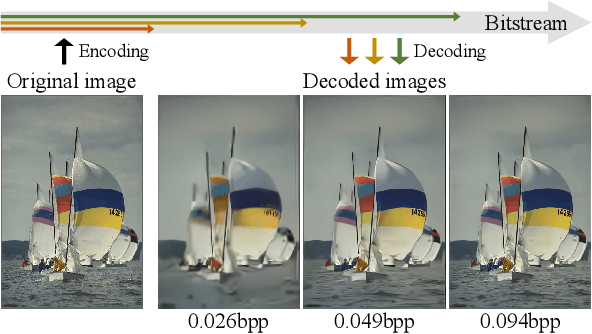
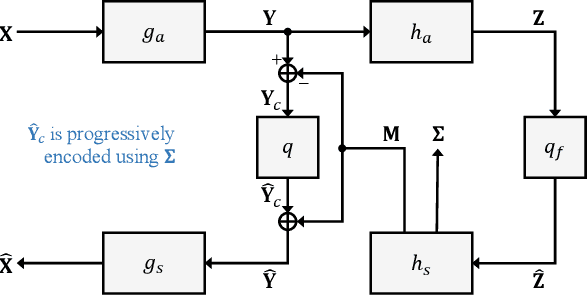
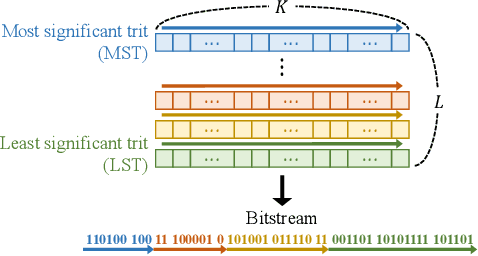
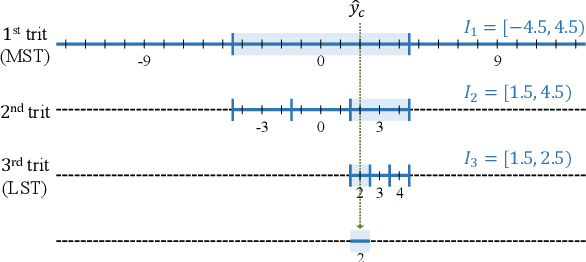
We propose the deep progressive image compression using trit-planes (DPICT) algorithm, which is the first learning-based codec supporting fine granular scalability (FGS). First, we transform an image into a latent tensor using an analysis network. Then, we represent the latent tensor in ternary digits (trits) and encode it into a compressed bitstream trit-plane by trit-plane in the decreasing order of significance. Moreover, within each trit-plane, we sort the trits according to their rate-distortion priorities and transmit more important information first. Since the compression network is less optimized for the cases of using fewer trit-planes, we develop a postprocessing network for refining reconstructed images at low rates. Experimental results show that DPICT outperforms conventional progressive codecs significantly, while enabling FGS transmission.