 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Image Denoising with Downsampled Invariance Loss and Conditional Blind-Spot Network
Apr 19, 2023
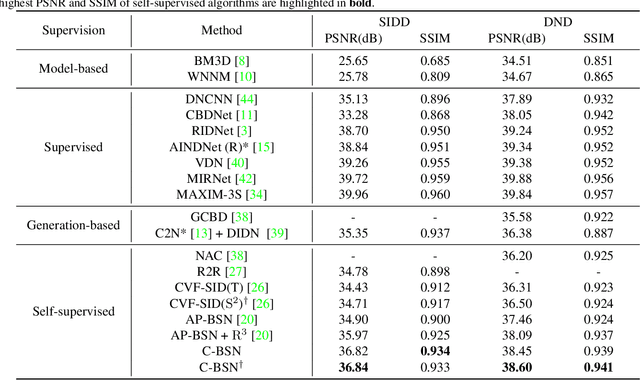
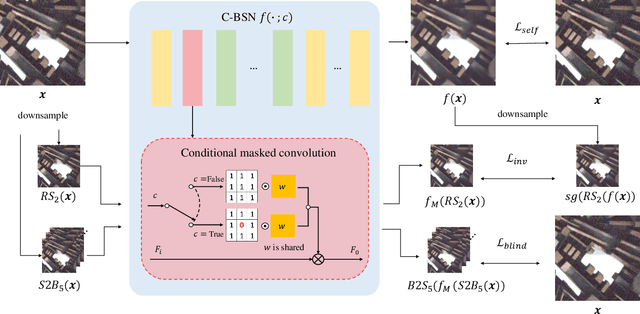

There have been many image denoisers using deep neural networks, which outperform conventional model-based methods by large margins. Recently, self-supervised methods have attracted attention because constructing a large real noise dataset for supervised training is an enormous burden. The most representative self-supervised denoisers are based on blind-spot networks, which exclude the receptive field's center pixel. However, excluding any input pixel is abandoning some information, especially when the input pixel at the corresponding output position is excluded. In addition, a standard blind-spot network fails to reduce real camera noise due to the pixel-wise correlation of noise, though it successfully removes independently distributed synthetic noise. Hence, to realize a more practical denoiser, we propose a novel self-supervised training framework that can remove real noise. For this, we derive the theoretic upper bound of a supervised loss where the network is guided by the downsampled blinded output. Also, we design a conditional blind-spot network (C-BSN), which selectively controls the blindness of the network to use the center pixel information. Furthermore, we exploit a random subsampler to decorrelate noise spatially, making the C-BSN free of visual artifacts that were often seen in downsample-based methods. Extensive experiments show that the proposed C-BSN achieves state-of-the-art performance on real-world datasets as a self-supervised denoiser and shows qualitatively pleasing results without any post-processing or refinement.
Lightweight Hybrid Video Compression Framework Using Reference-Guided Restoration Network
Mar 21, 2023



Recent deep-learning-based video compression methods brought coding gains over conventional codecs such as AVC and HEVC. However, learning-based codecs generally require considerable computation time and model complexity. In this paper, we propose a new lightweight hybrid video codec consisting of a conventional video codec(HEVC / VVC), a lossless image codec, and our new restoration network. Precisely, our encoder consists of the conventional video encoder and a lossless image encoder, transmitting a lossy-compressed video bitstream along with a losslessly-compressed reference frame. The decoder is constructed with corresponding video/image decoders and a new restoration network, which enhances the compressed video in two-step processes. In the first step, a network trained with a large video dataset restores the details lost by the conventional encoder. Then, we further boost the video quality with the guidance of a reference image, which is a losslessly compressed video frame. The reference image provides video-specific information, which can be utilized to better restore the details of a compressed video. Experimental results show that the proposed method achieves comparable performance to top-tier methods, even when applied to HEVC. Nevertheless, our method has lower complexity, a faster run time, and can be easily integrated into existing conventional codecs.
Image Anomaly Detection and Localization with Position and Neighborhood Information
Nov 29, 2022Anomaly detection and localization are essential in many areas, where collecting enough anomalous samples for training is almost impossible. To overcome this difficulty, many existing methods use a pre-trained network to encode input images and non-parametric modeling to estimate the encoded feature distribution. In the modeling process, however, they overlook that position and neighborhood information affect the distribution of normal features. To use the information, in this paper, the normal distribution is estimated with conditional probability given neighborhood features, which is modeled with a multi-layer perceptron network. At the same time, positional information can be used by building a histogram of representative features at each position. While existing methods simply resize the anomaly map into the resolution of an input image, the proposed method uses an additional refine network that is trained from synthetic anomaly images to perform better interpolation considering the shape and edge of the input image. For the popular industrial dataset, MVTec AD benchmark, the experimental results show \textbf{99.52\%} and \textbf{98.91\%} AUROC scores in anomaly detection and localization, which is state-of-the-art performance.
Real-Time Seizure Detection using EEG: A Comprehensive Comparison of Recent Approaches under a Realistic Setting
Jan 21, 2022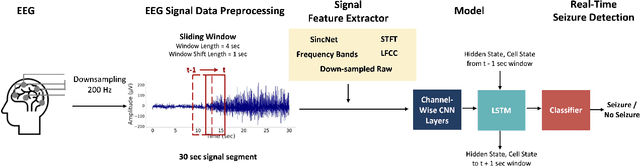
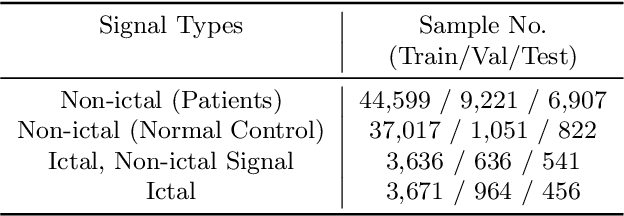
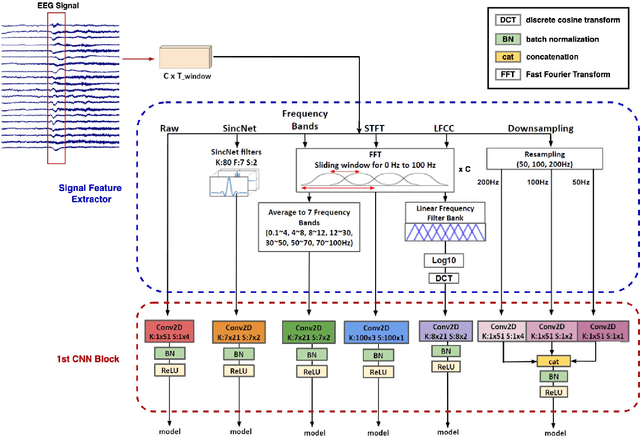
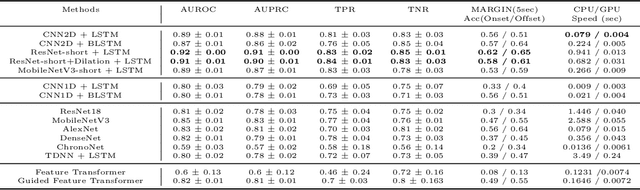
Electroencephalogram (EEG) is an important diagnostic test that physicians use to record brain activity and detect seizures by monitoring the signals. There have been several attempts to detect seizures and abnormalities in EEG signals with modern deep learning models to reduce the clinical burden. However, they cannot be fairly compared against each other as they were tested in distinct experimental settings. Also, some of them are not trained in real-time seizure detection tasks, making it hard for on-device applications. Therefore in this work, for the first time, we extensively compare multiple state-of-the-art models and signal feature extractors in a real-time seizure detection framework suitable for real-world application, using various evaluation metrics including a new one we propose to evaluate more practical aspects of seizure detection models. Our code is available at https://github.com/AITRICS/EEG_real_time_seizure_detection.
LC-FDNet: Learned Lossless Image Compression with Frequency Decomposition Network
Dec 13, 2021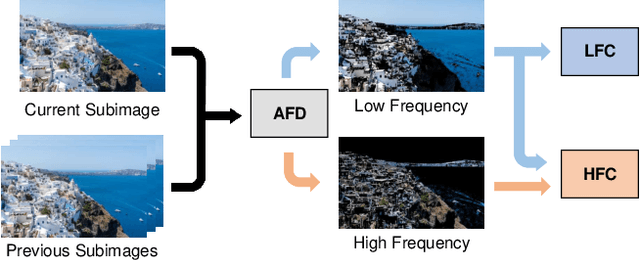
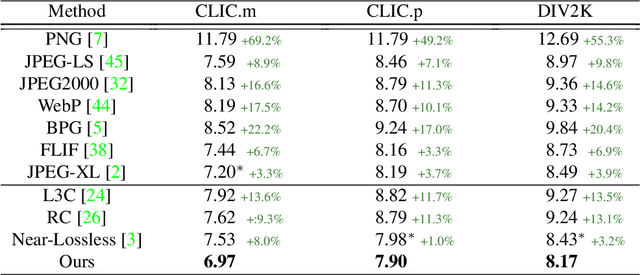
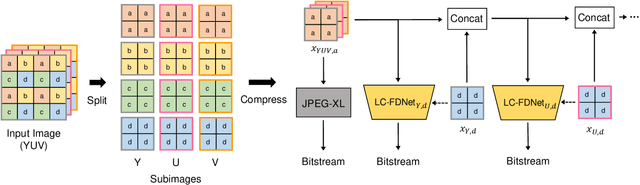
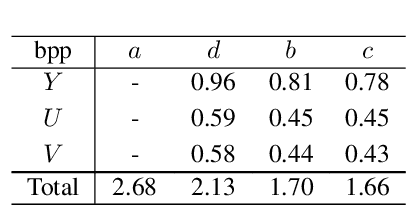
Recent learning-based lossless image compression methods encode an image in the unit of subimages and achieve comparable performances to conventional non-learning algorithms. However, these methods do not consider the performance drop in the high-frequency region, giving equal consideration to the low and high-frequency areas. In this paper, we propose a new lossless image compression method that proceeds the encoding in a coarse-to-fine manner to separate and process low and high-frequency regions differently. We initially compress the low-frequency components and then use them as additional input for encoding the remaining high-frequency region. The low-frequency components act as a strong prior in this case, which leads to improved estimation in the high-frequency area. In addition, we design the frequency decomposition process to be adaptive to color channel, spatial location, and image characteristics. As a result, our method derives an image-specific optimal ratio of low/high-frequency components. Experiments show that the proposed method achieves state-of-the-art performance for benchmark high-resolution datasets.