 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Hybrid Video Compression Framework Using Reference-Guided Restoration Network
Mar 21, 2023



Recent deep-learning-based video compression methods brought coding gains over conventional codecs such as AVC and HEVC. However, learning-based codecs generally require considerable computation time and model complexity. In this paper, we propose a new lightweight hybrid video codec consisting of a conventional video codec(HEVC / VVC), a lossless image codec, and our new restoration network. Precisely, our encoder consists of the conventional video encoder and a lossless image encoder, transmitting a lossy-compressed video bitstream along with a losslessly-compressed reference frame. The decoder is constructed with corresponding video/image decoders and a new restoration network, which enhances the compressed video in two-step processes. In the first step, a network trained with a large video dataset restores the details lost by the conventional encoder. Then, we further boost the video quality with the guidance of a reference image, which is a losslessly compressed video frame. The reference image provides video-specific information, which can be utilized to better restore the details of a compressed video. Experimental results show that the proposed method achieves comparable performance to top-tier methods, even when applied to HEVC. Nevertheless, our method has lower complexity, a faster run time, and can be easily integrated into existing conventional codecs.
LC-FDNet: Learned Lossless Image Compression with Frequency Decomposition Network
Dec 13, 2021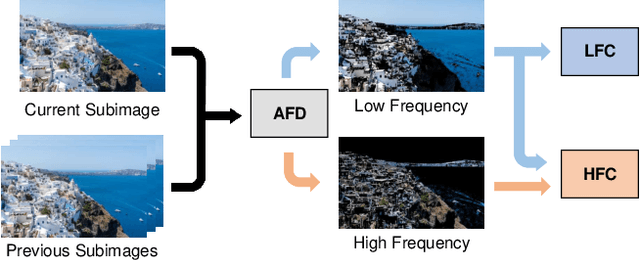
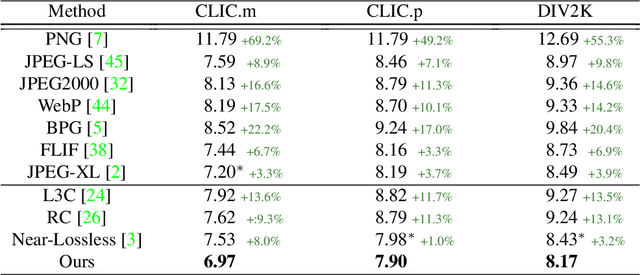
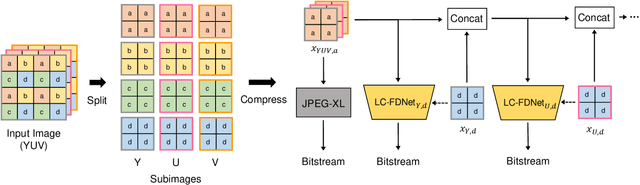
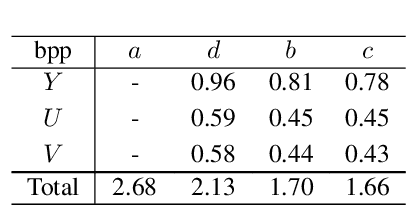
Recent learning-based lossless image compression methods encode an image in the unit of subimages and achieve comparable performances to conventional non-learning algorithms. However, these methods do not consider the performance drop in the high-frequency region, giving equal consideration to the low and high-frequency areas. In this paper, we propose a new lossless image compression method that proceeds the encoding in a coarse-to-fine manner to separate and process low and high-frequency regions differently. We initially compress the low-frequency components and then use them as additional input for encoding the remaining high-frequency region. The low-frequency components act as a strong prior in this case, which leads to improved estimation in the high-frequency area. In addition, we design the frequency decomposition process to be adaptive to color channel, spatial location, and image characteristics. As a result, our method derives an image-specific optimal ratio of low/high-frequency components. Experiments show that the proposed method achieves state-of-the-art performance for benchmark high-resolution datasets.