 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactile Memory with Soft Robot: Robust Object Insertion via Masked Encoding and Soft Wrist
Jan 27, 2026Tactile memory, the ability to store and retrieve touch-based experience, is critical for contact-rich tasks such as key insertion under uncertainty. To replicate this capability, we introduce Tactile Memory with Soft Robot (TaMeSo-bot), a system that integrates a soft wrist with tactile retrieval-based control to enable safe and robust manipulation. The soft wrist allows safe contact exploration during data collection, while tactile memory reuses past demonstrations via retrieval for flexible adaptation to unseen scenarios. The core of this system is the Masked Tactile Trajectory Transformer (MAT$^\text{3}$), which jointly models spatiotemporal interactions between robot actions, distributed tactile feedback, force-torque measurements, and proprioceptive signals. Through masked-token prediction, MAT$^\text{3}$ learns rich spatiotemporal representations by inferring missing sensory information from context, autonomously extracting task-relevant features without explicit subtask segmentation. We validate our approach on peg-in-hole tasks with diverse pegs and conditions in real-robot experiments. Our extensive evaluation demonstrates that MAT$^\text{3}$ achieves higher success rates than the baselines over all conditions and shows remarkable capability to adapt to unseen pegs and conditions.
Learning Diffusion Policies from Demonstrations For Compliant Contact-rich Manipulation
Oct 25, 2024
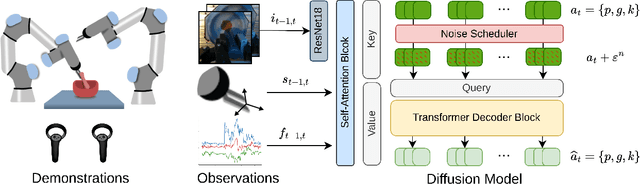

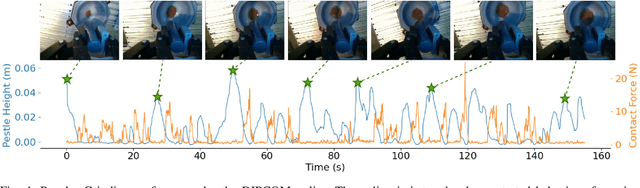
Robots hold great promise for performing repetitive or hazardous tasks, but achieving human-like dexterity, especially in contact-rich and dynamic environments, remains challenging. Rigid robots, which rely on position or velocity control, often struggle with maintaining stable contact and applying consistent force in force-intensive tasks. Learning from Demonstration has emerged as a solution, but tasks requiring intricate maneuvers, such as powder grinding, present unique difficulties. This paper introduces Diffusion Policies For Compliant Manipulation (DIPCOM), a novel diffusion-based framework designed for compliant control tasks. By leveraging generative diffusion models, we develop a policy that predicts Cartesian end-effector poses and adjusts arm stiffness to maintain the necessary force. Our approach enhances force control through multimodal distribution modeling, improves the integration of diffusion policies in compliance control, and extends our previous work by demonstrating its effectiveness in real-world tasks. We present a detailed comparison between our framework and existing methods, highlighting the advantages and best practices for deploying diffusion-based compliance control.
Learning Variable Compliance Control From a Few Demonstrations for Bimanual Robot with Haptic Feedback Teleoperation System
Jun 21, 2024



Automating dexterous, contact-rich manipulation tasks using rigid robots is a significant challenge in robotics. Rigid robots, defined by their actuation through position commands, face issues of excessive contact forces due to their inability to adapt to contact with the environment, potentially causing damage. While compliance control schemes have been introduced to mitigate these issues by controlling forces via external sensors, they are hampered by the need for fine-tuning task-specific controller parameters. Learning from Demonstrations (LfD) offers an intuitive alternative, allowing robots to learn manipulations through observed actions. In this work, we introduce a novel system to enhance the teaching of dexterous, contact-rich manipulations to rigid robots. Our system is twofold: firstly, it incorporates a teleoperation interface utilizing Virtual Reality (VR) controllers, designed to provide an intuitive and cost-effective method for task demonstration with haptic feedback. Secondly, we present Comp-ACT (Compliance Control via Action Chunking with Transformers), a method that leverages the demonstrations to learn variable compliance control from a few demonstrations. Our methods have been validated across various complex contact-rich manipulation tasks using single-arm and bimanual robot setups in simulated and real-world environments, demonstrating the effectiveness of our system in teaching robots dexterous manipulations with enhanced adaptability and safety.
Tactile-based Active Inference for Force-Controlled Peg-in-Hole Insertions
Sep 27, 2023



Reinforcement Learning (RL) has shown great promise for efficiently learning force control policies in peg-in-hole tasks. However, robots often face difficulties due to visual occlusions by the gripper and uncertainties in the initial grasping pose of the peg. These challenges often restrict force-controlled insertion policies to situations where the peg is rigidly fixed to the end-effector. While vision-based tactile sensors offer rich tactile feedback that could potentially address these issues, utilizing them to learn effective tactile policies is both computationally intensive and difficult to generalize. In this paper, we propose a robust tactile insertion policy that can align the tilted peg with the hole using active inference, without the need for extensive training on large datasets. Our approach employs a dual-policy architecture: one policy focuses on insertion, integrating force control and RL to guide the object into the hole, while the other policy performs active inference based on tactile feedback to align the tilted peg with the hole. In real-world experiments, our dual-policy architecture achieved 90% success rate into a hole with a clearance of less than 0.1 mm, significantly outperforming previous methods that lack tactile sensory feedback (5%). To assess the generalizability of our alignment policy, we conducted experiments with five different pegs, demonstrating its effective adaptation to multiple objects.