 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Pic Swift: Enhancing Long-Text to Image Retrieval for Large-Scale Libraries
Paper and Code
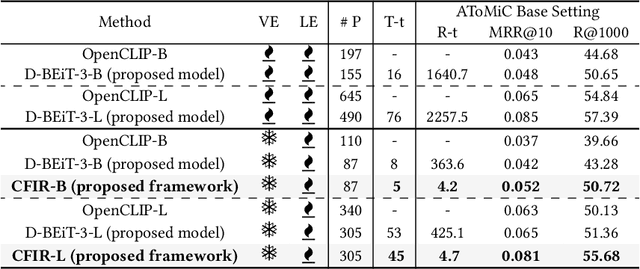
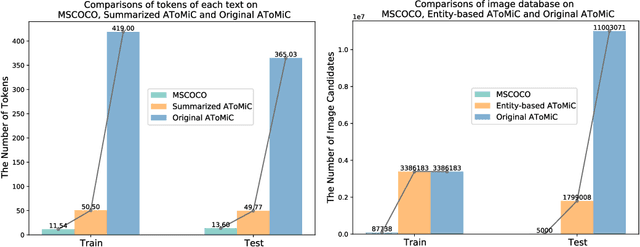
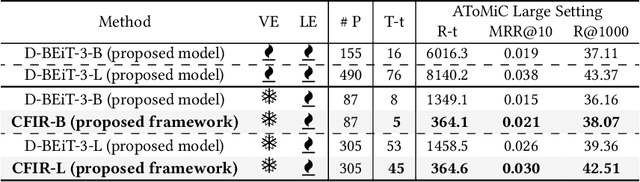
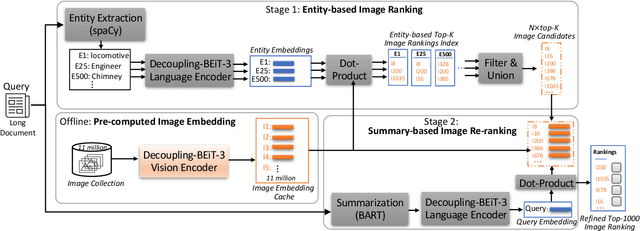
Text-to-image retrieval plays a crucial role across various applications, including digital libraries, e-commerce platforms, and multimedia databases, by enabling the search for images using text queries. Despite the advancements in Multimodal Large Language Models (MLLMs), which offer leading-edge performance, their applicability in large-scale, varied, and ambiguous retrieval scenarios is constrained by significant computational demands and the generation of injective embeddings. This paper introduces the Text2Pic Swift framework, tailored for efficient and robust retrieval of images corresponding to extensive textual descriptions in sizable datasets. The framework employs a two-tier approach: the initial Entity-based Ranking (ER) stage addresses the ambiguity inherent in lengthy text queries through a multiple-queries-to-multiple-targets strategy, effectively narrowing down potential candidates for subsequent analysis. Following this, the Summary-based Re-ranking (SR) stage further refines these selections based on concise query summaries. Additionally, we present a novel Decoupling-BEiT-3 encoder, specifically designed to tackle the challenges of ambiguous queries and to facilitate both stages of the retrieval process, thereby significantly improving computational efficiency via vector-based similarity assessments. Our evaluation, conducted on the AToMiC dataset, demonstrates that Text2Pic Swift outperforms current MLLMs by achieving up to an 11.06% increase in Recall@1000, alongside reductions in training and retrieval durations by 68.75% and 99.79%, respectively.