 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Inferring User Socioeconomic Status with Mobility Records
Nov 15, 2022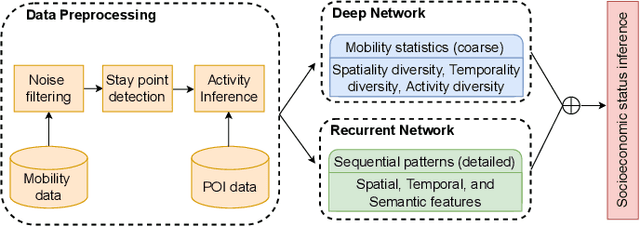
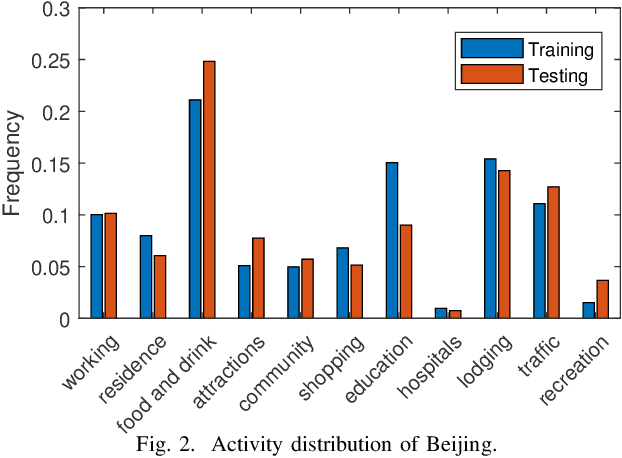
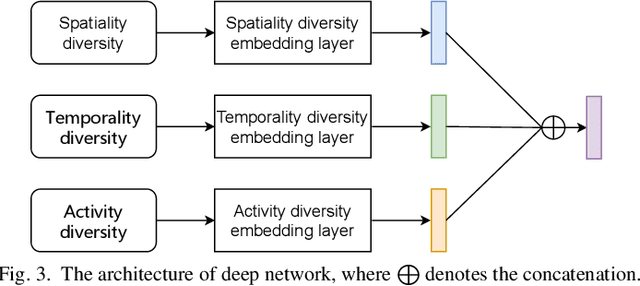
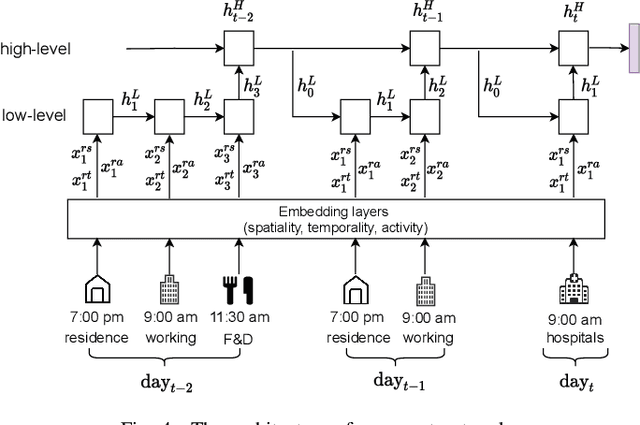
When users move in a physical space (e.g., an urban space), they would have some records called mobility records (e.g., trajectories) generated by devices such as mobile phones and GPS devices. Naturally, mobility records capture essential information of how users work, live and entertain in their daily lives, and therefore, they have been used in a wide range of tasks such as user profile inference, mobility prediction and traffic management. In this paper, we expand this line of research by investigating the problem of inferring user socioeconomic statuses (such as prices of users' living houses as a proxy of users' socioeconomic statuses) based on their mobility records, which can potentially be used in real-life applications such as the car loan business. For this task, we propose a socioeconomic-aware deep model called DeepSEI. The DeepSEI model incorporates two networks called deep network and recurrent network, which extract the features of the mobility records from three aspects, namely spatiality, temporality and activity, one at a coarse level and the other at a detailed level. We conduct extensive experiments on real mobility records data, POI data and house prices data. The results verify that the DeepSEI model achieves superior performance than existing studies. All datasets used in this paper will be made publicly available.
Entity Aware Syntax Tree Based Data Augmentation for Natural Language Understanding
Sep 06, 2022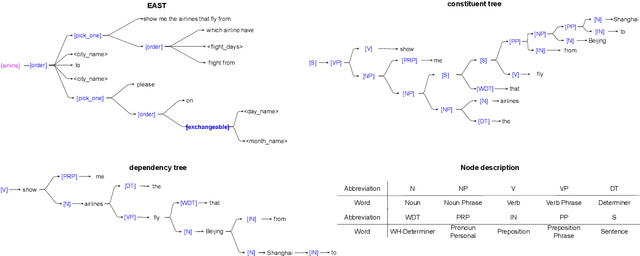

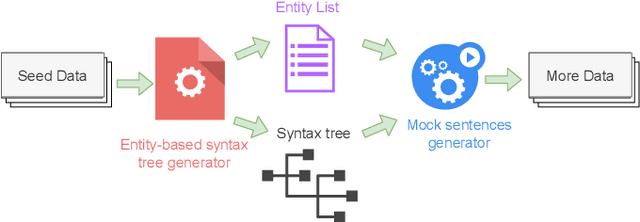
Understanding the intention of the users and recognizing the semantic entities from their sentences, aka natural language understanding (NLU), is the upstream task of many natural language processing tasks. One of the main challenges is to collect a sufficient amount of annotated data to train a model. Existing research about text augmentation does not abundantly consider entity and thus performs badly for NLU tasks. To solve this problem, we propose a novel NLP data augmentation technique, Entity Aware Data Augmentation (EADA), which applies a tree structure, Entity Aware Syntax Tree (EAST), to represent sentences combined with attention on the entity. Our EADA technique automatically constructs an EAST from a small amount of annotated data, and then generates a large number of training instances for intent detection and slot filling. Experimental results on four datasets showed that the proposed technique significantly outperforms the existing data augmentation methods in terms of both accuracy and generalization ability.
Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation
Sep 15, 2021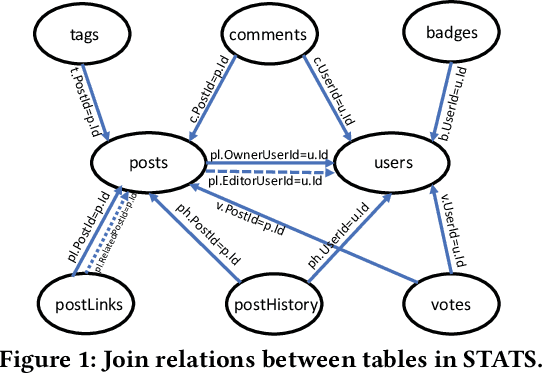
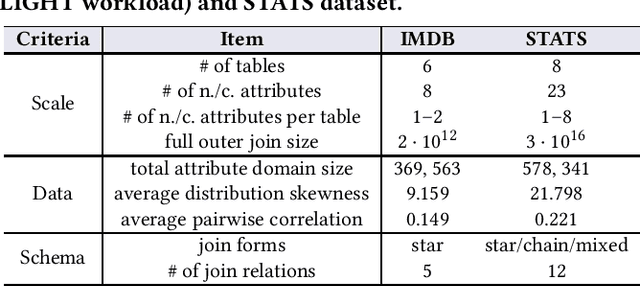
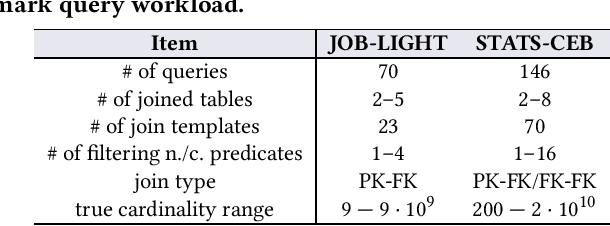
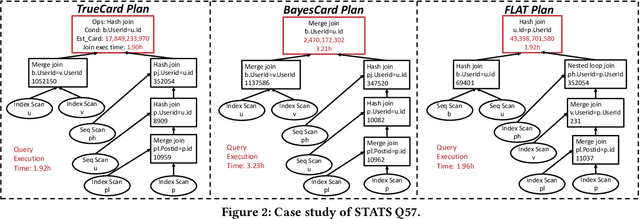
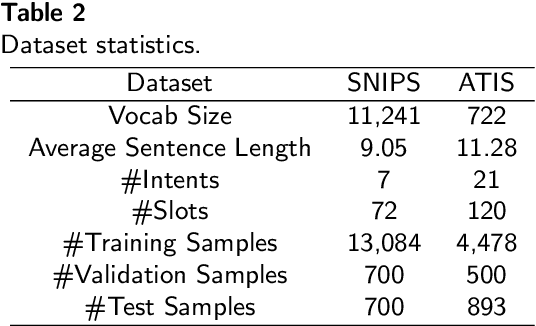
Cardinality estimation (CardEst) plays a significant role in generating high-quality query plans for a query optimizer in DBMS. In the last decade, an increasing number of advanced CardEst methods (especially ML-based) have been proposed with outstanding estimation accuracy and inference latency. However, there exists no study that systematically evaluates the quality of these methods and answer the fundamental problem: to what extent can these methods improve the performance of query optimizer in real-world settings, which is the ultimate goal of a CardEst method. In this paper, we comprehensively and systematically compare the effectiveness of CardEst methods in a real DBMS. We establish a new benchmark for CardEst, which contains a new complex real-world dataset STATS and a diverse query workload STATS-CEB. We integrate multiple most representative CardEst methods into an open-source database system PostgreSQL, and comprehensively evaluate their true effectiveness in improving query plan quality, and other important aspects affecting their applicability, ranging from inference latency, model size, and training time, to update efficiency and accuracy. We obtain a number of key findings for the CardEst methods, under different data and query settings. Furthermore, we find that the widely used estimation accuracy metric(Q-Error) cannot distinguish the importance of different sub-plan queries during query optimization and thus cannot truly reflect the query plan quality generated by CardEst methods. Therefore, we propose a new metric P-Error to evaluate the performance of CardEst methods, which overcomes the limitation of Q-Error and is able to reflect the overall end-to-end performance of CardEst methods. We have made all of the benchmark data and evaluation code publicly available at https://github.com/Nathaniel-Han/End-to-End-CardEst-Benchmark.
FSPN: A New Class of Probabilistic Graphical Model
Nov 20, 2020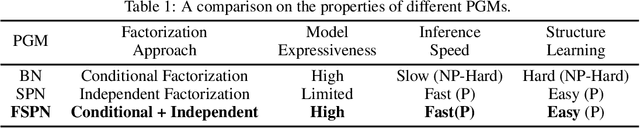
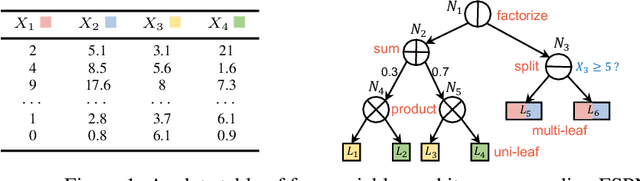
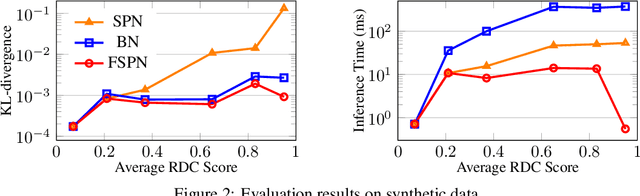
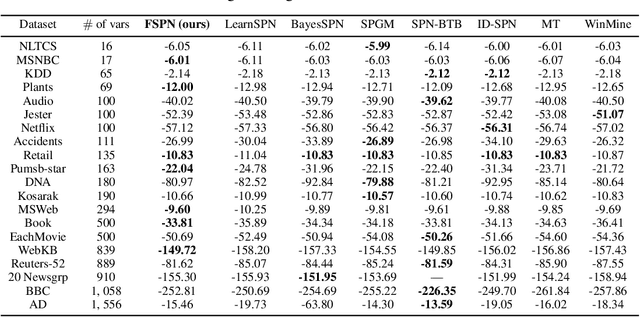
We introduce factorize sum split product networks (FSPNs), a new class of probabilistic graphical models (PGMs). FSPNs are designed to overcome the drawbacks of existing PGMs in terms of estimation accuracy and inference efficiency. Specifically, Bayesian networks (BNs) have low inference speed and performance of tree structured sum product networks(SPNs) significantly degrades in presence of highly correlated variables. FSPNs absorb their advantages by adaptively modeling the joint distribution of variables according to their dependence degree, so that one can simultaneously attain the two desirable goals: high estimation accuracy and fast inference speed. We present efficient probability inference and structure learning algorithms for FSPNs, along with a theoretical analysis and extensive evaluation evidence. Our experimental results on synthetic and benchmark datasets indicate the superiority of FSPN over other PGMs.