 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASTER: A Computer-Vision-Assisted Wireless Channel Simulator for Gesture Recognition
Nov 13, 2023



In this paper, a computer-vision-assisted simulation method is proposed to address the issue of training dataset acquisition for wireless hand gesture recognition. In the existing literature, in order to classify gestures via the wireless channel estimation, massive training samples should be measured in a consistent environment, consuming significant efforts. In the proposed CASTER simulator, however, the training dataset can be simulated via existing videos. Particularly, a gesture is represented by a sequence of snapshots, and the channel impulse response of each snapshot is calculated via tracing the rays scattered off a primitive-based hand model. Moreover, CASTER simulator relies on the existing videos to extract the motion data of gestures. Thus, the massive measurements of wireless channel can be eliminated. The experiments demonstrate a 90.8% average classification accuracy of simulation-to-reality inference.
A self-supervised learning-based 6-DOF grasp planning method for manipulator
Jan 30, 2021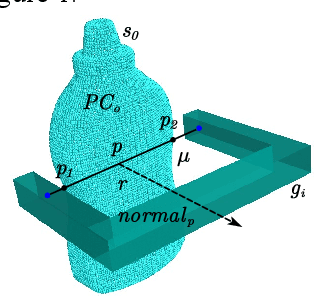
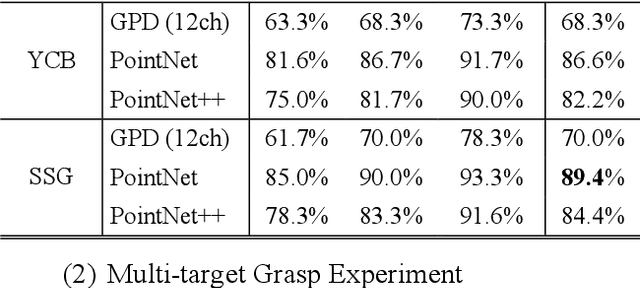
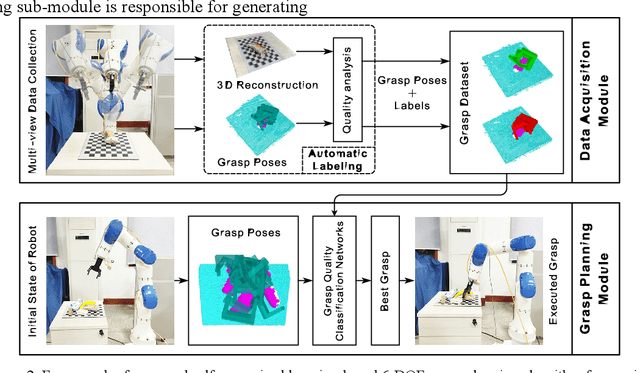
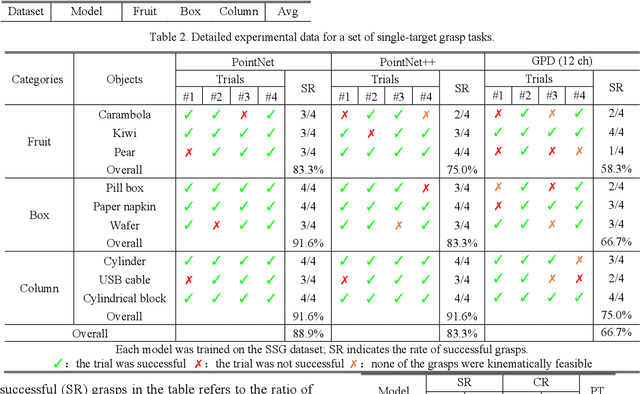
To realize a robust robotic grasping system for unknown objects in an unstructured environment, large amounts of grasp data and 3D model data for the object are required, the sizes of which directly affect the rate of successful grasps. To reduce the time cost of data acquisition and labeling and increase the rate of successful grasps, we developed a self-supervised learning mechanism to control grasp tasks performed by manipulators. First, a manipulator automatically collects the point cloud for the objects from multiple perspectives to increase the efficiency of data acquisition. The complete point cloud for the objects is obtained by utilizing the hand-eye vision of the manipulator, and the TSDF algorithm. Then, the point cloud data for the objects is used to generate a series of six-degrees-of-freedom grasp poses, and the force-closure decision algorithm is used to add the grasp quality label to each grasp pose to realize the automatic labeling of grasp data. Finally, the point cloud in the gripper closing area corresponding to each grasp pose is obtained; it is then used to train the grasp-quality classification model for the manipulator. The results of data acquisition experiments demonstrate that the proposed method allows high-quality data to be obtained. The simulated results prove the effectiveness of the proposed grasp-data acquisition method. The results of performing actual grasping experiments demonstrate that the proposed self-supervised learning method can increase the rate of successful grasps for the manipulator.
Adversarial Examples versus Cloud-based Detectors: A Black-box Empirical Study
Jan 13, 2019
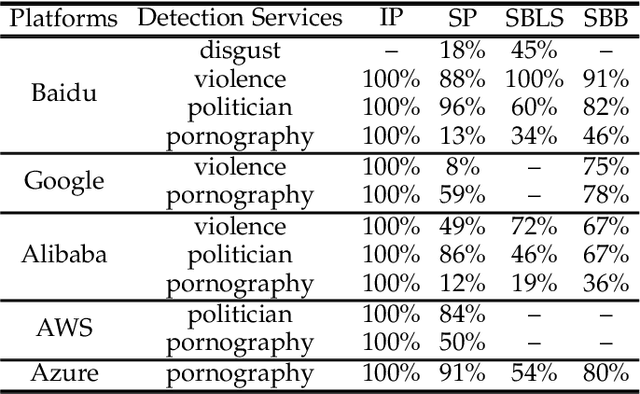

Deep learning has been broadly leveraged by major cloud providers such as Google, AWS, Baidu, to offer various computer vision related services including image auto-classification, object identification and illegal image detection. While many recent works demonstrated that deep learning classification models are vulnerable to adversarial examples, real-world cloud-based image detection services are more complex than classification and there is little literature about adversarial example attacks on detection services. In this paper, we mainly focus on studying the security of real-world cloud-based image detectors. Specifically, (1) based on effective semantic segmentation, we propose four different attacks to generate semantics-aware adversarial examples via only interacting with black-box APIs; and (2) we make the first attempt to conduct an extensive empirical study of black-box attacks against real-world cloud-based image detectors. Through evaluations on five popular cloud platforms including AWS, Azure, Google Cloud, Baidu Cloud and Alibaba Cloud, we demonstrate that our IP attack has a success rate of approximately 100%, and semantic segmentation based attacks (e.g., SP, SBLS, SBB) have a a success rate over 90% among different detection services, such as violence, politician and pornography detection. We discuss the possible defenses to address these security challenges in cloud-based detectors.