 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End QGAN-Based Image Synthesis via Neural Noise Encoding and Intensity Calibration
Mar 19, 2026Quantum Generative Adversarial Networks (QGANs) offer a promising path for learning data distributions on near-term quantum devices. However, existing QGANs for image synthesis avoid direct full-image generation, relying on classical post-processing or patch-based methods. These approaches dilute the quantum generator's role and struggle to capture global image semantics. To address this, we propose ReQGAN, an end-to-end framework that synthesizes an entire N=2^D-pixel image using a single D-qubit quantum circuit. ReQGAN overcomes two fundamental bottlenecks hindering direct pixel generation: (1) the rigid classical-to-quantum noise interface and (2) the output mismatch between normalized quantum statistics and the desired pixel-intensity space. We introduce a learnable Neural Noise Encoder for adaptive state preparation and a differentiable Intensity Calibration module to map measurements to a stable, visually meaningful pixel domain. Experiments on MNIST and Fashion-MNIST demonstrate that ReQGAN achieves stable training and effective image synthesis under stringent qubit budgets, with ablation studies verifying the contribution of each component.
Quantum Conflict Measurement in Decision Making for Out-of-Distribution Detection
May 10, 2025Quantum Dempster-Shafer Theory (QDST) uses quantum interference effects to derive a quantum mass function (QMF) as a fuzzy metric type from information obtained from various data sources. In addition, QDST uses quantum parallel computing to speed up computation. Nevertheless, the effective management of conflicts between multiple QMFs in QDST is a challenging question. This work aims to address this problem by proposing a Quantum Conflict Indicator (QCI) that measures the conflict between two QMFs in decision-making. Then, the properties of the QCI are carefully investigated. The obtained results validate its compliance with desirable conflict measurement properties such as non-negativity, symmetry, boundedness, extreme consistency and insensitivity to refinement. We then apply the proposed QCI in conflict fusion methods and compare its performance with several commonly used fusion approaches. This comparison demonstrates the superiority of the QCI-based conflict fusion method. Moreover, the Class Description Domain Space (C-DDS) and its optimized version, C-DDS+ by utilizing the QCI-based fusion method, are proposed to address the Out-of-Distribution (OOD) detection task. The experimental results show that the proposed approach gives better OOD performance with respect to several state-of-the-art baseline OOD detection methods. Specifically, it achieves an average increase in Area Under the Receiver Operating Characteristic Curve (AUC) of 1.2% and a corresponding average decrease in False Positive Rate at 95% True Negative Rate (FPR95) of 5.4% compared to the optimal baseline method.
Adaptive Graph Convolutional Subspace Clustering
May 05, 2023Spectral-type subspace clustering algorithms have shown excellent performance in many subspace clustering applications. The existing spectral-type subspace clustering algorithms either focus on designing constraints for the reconstruction coefficient matrix or feature extraction methods for finding latent features of original data samples. In this paper, inspired by graph convolutional networks, we use the graph convolution technique to develop a feature extraction method and a coefficient matrix constraint simultaneously. And the graph-convolutional operator is updated iteratively and adaptively in our proposed algorithm. Hence, we call the proposed method adaptive graph convolutional subspace clustering (AGCSC). We claim that by using AGCSC, the aggregated feature representation of original data samples is suitable for subspace clustering, and the coefficient matrix could reveal the subspace structure of the original data set more faithfully. Finally, plenty of subspace clustering experiments prove our conclusions and show that AGCSC outperforms some related methods as well as some deep models.
Learning idempotent representation for subspace clustering
Jul 29, 2022
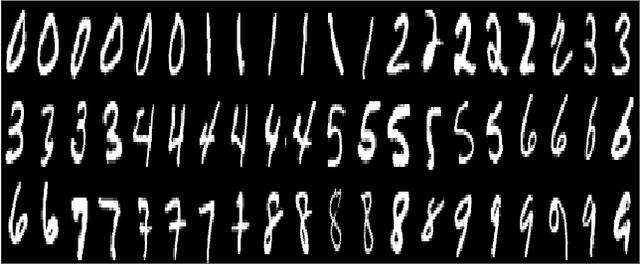


The critical point for the successes of spectral-type subspace clustering algorithms is to seek reconstruction coefficient matrices which can faithfully reveal the subspace structures of data sets. An ideal reconstruction coefficient matrix should have two properties: 1) it is block diagonal with each block indicating a subspace; 2) each block is fully connected. Though there are various spectral-type subspace clustering algorithms have been proposed, some defects still exist in the reconstruction coefficient matrices constructed by these algorithms. We find that a normalized membership matrix naturally satisfies the above two conditions. Therefore, in this paper, we devise an idempotent representation (IDR) algorithm to pursue reconstruction coefficient matrices approximating normalized membership matrices. IDR designs a new idempotent constraint for reconstruction coefficient matrices. And by combining the doubly stochastic constraints, the coefficient matrices which are closed to normalized membership matrices could be directly achieved. We present the optimization algorithm for solving IDR problem and analyze its computation burden as well as convergence. The comparisons between IDR and related algorithms show the superiority of IDR. Plentiful experiments conducted on both synthetic and real world datasets prove that IDR is an effective and efficient subspace clustering algorithm.