 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving reliability of uncertainty-aware gaze estimation with probability calibration
Jan 24, 2025



Current deep learning powered appearance based uncertainty-aware gaze estimation models produce inconsistent and unreliable uncertainty estimation that limits their adoptions in downstream applications. In this study, we propose a workflow to improve the accuracy of uncertainty estimation using probability calibration with a few post hoc samples. The probability calibration process employs a simple secondary regression model to compensate for inaccuracies in estimated uncertainties from the deep learning model. Training of the secondary model is detached from the main deep learning model and thus no expensive weight tuning is required. The added calibration process is lightweight and relatively independent from the deep learning process, making it fast to run and easy to implement. We evaluated the effectiveness of the calibration process under four potential application scenarios with two datasets that have distinctive image characteristics due to the data collection setups. The calibration process is most effective when the calibration and testing data share similar characteristics. Even under suboptimal circumstances that calibration and testing data differ, the calibration process can still make corrections to reduce prediction errors in uncertainty estimates made by uncalibrated models.
Stable In-hand Manipulation with Finger Specific Multi-agent Shadow Reward
Sep 13, 2023



Deep Reinforcement Learning has shown its capability to solve the high degrees of freedom in control and the complex interaction with the object in the multi-finger dexterous in-hand manipulation tasks. Current DRL approaches prefer sparse rewards to dense rewards for the ease of training but lack behavior constraints during the manipulation process, leading to aggressive and unstable policies that are insufficient for safety-critical in-hand manipulation tasks. Dense rewards can regulate the policy to learn stable manipulation behaviors with continuous reward constraints but are hard to empirically define and slow to converge optimally. This work proposes the Finger-specific Multi-agent Shadow Reward (FMSR) method to determine the stable manipulation constraints in the form of dense reward based on the state-action occupancy measure, a general utility of DRL that is approximated during the learning process. Information Sharing (IS) across neighboring agents enables consensus training to accelerate the convergence. The methods are evaluated in two in-hand manipulation tasks on the Shadow Hand. The results show FMSR+IS converges faster in training, achieving a higher task success rate and better manipulation stability than conventional dense reward. The comparison indicates FMSR+IS achieves a comparable success rate even with the behavior constraint but much better manipulation stability than the policy trained with a sparse reward.
Curriculum-based Sensing Reduction in Simulation to Real-World Transfer for In-hand Manipulation
Sep 13, 2023



Simulation to Real-World Transfer allows affordable and fast training of learning-based robots for manipulation tasks using Deep Reinforcement Learning methods. Currently, Sim2Real uses Asymmetric Actor-Critic approaches to reduce the rich idealized features in simulation to the accessible ones in the real world. However, the feature reduction from the simulation to the real world is conducted through an empirically defined one-step curtail. Small feature reduction does not sufficiently remove the actor's features, which may still cause difficulty setting up the physical system, while large feature reduction may cause difficulty and inefficiency in training. To address this issue, we proposed Curriculum-based Sensing Reduction to enable the actor to start with the same rich feature space as the critic and then get rid of the hard-to-extract features step-by-step for higher training performance and better adaptation for real-world feature space. The reduced features are replaced with random signals from a Deep Random Generator to remove the dependency between the output and the removed features and avoid creating new dependencies. The methods are evaluated on the Allegro robot hand in a real-world in-hand manipulation task. The results show that our methods have faster training and higher task performance than baselines and can solve real-world tasks when selected tactile features are reduced.
Confidence-aware 3D Gaze Estimation and Evaluation Metric
Mar 17, 2023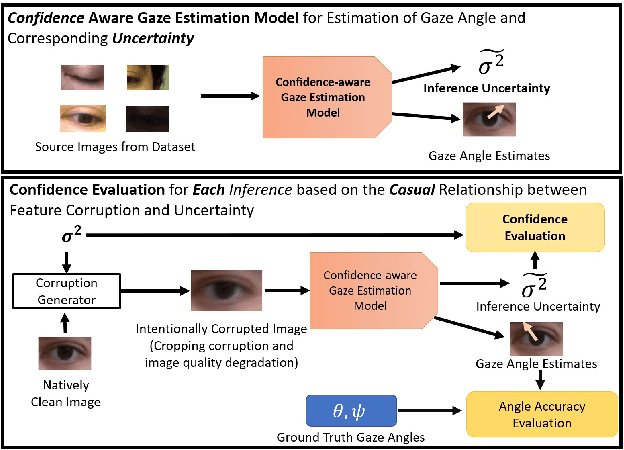

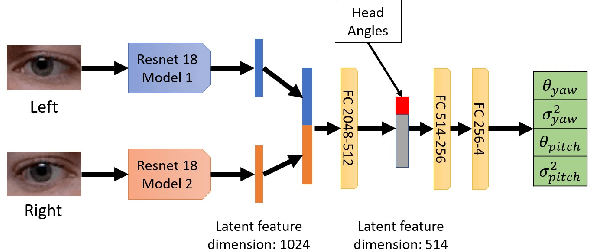
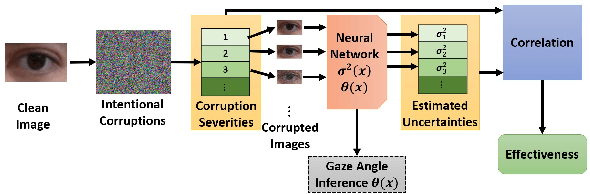
Deep learning appearance-based 3D gaze estimation is gaining popularity due to its minimal hardware requirements and being free of constraint. Unreliable and overconfident inferences, however, still limit the adoption of this gaze estimation method. To address the unreliable and overconfident issues, we introduce a confidence-aware model that predicts uncertainties together with gaze angle estimations. We also introduce a novel effectiveness evaluation method based on the causality between eye feature degradation and the rise in inference uncertainty to assess the uncertainty estimation. Our confidence-aware model demonstrates reliable uncertainty estimations while providing angular estimation accuracies on par with the state-of-the-art. Compared with the existing statistical uncertainty-angular-error evaluation metric, the proposed effectiveness evaluation approach can more effectively judge inferred uncertainties' performance at each prediction.
A Multi-Agent Approach for Adaptive Finger Cooperation in Learning-based In-Hand Manipulation
Oct 11, 2022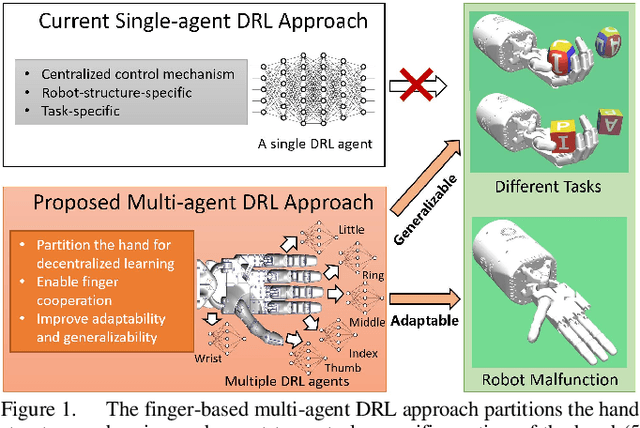
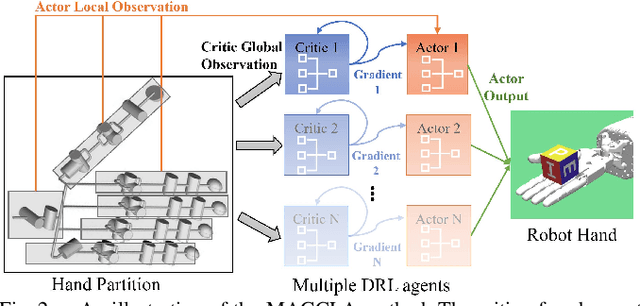
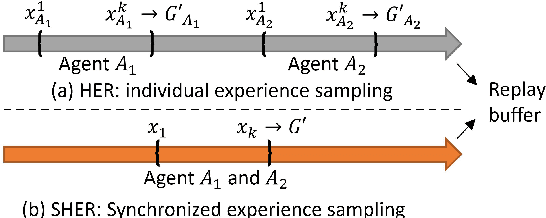
In-hand manipulation is challenging for a multi-finger robotic hand due to its high degrees of freedom and the complex interaction with the object. To enable in-hand manipulation, existing deep reinforcement learning based approaches mainly focus on training a single robot-structure-specific policy through the centralized learning mechanism, lacking adaptability to changes like robot malfunction. To solve this limitation, this work treats each finger as an individual agent and trains multiple agents to control their assigned fingers to complete the in-hand manipulation task cooperatively. We propose the Multi-Agent Global-Observation Critic and Local-Observation Actor (MAGCLA) method, where the critic can observe all agents' actions globally, and the actor only locally observes its neighbors' actions. Besides, conventional individual experience replay may cause unstable cooperation due to the asynchronous performance increment of each agent, which is critical for in-hand manipulation tasks. To solve this issue, we propose the Synchronized Hindsight Experience Replay (SHER) method to synchronize and efficiently reuse the replayed experience across all agents. The methods are evaluated in two in-hand manipulation tasks on the Shadow dexterous hand. The results show that SHER helps MAGCLA achieve comparable learning efficiency to a single policy, and the MAGCLA approach is more generalizable in different tasks. The trained policies have higher adaptability in the robot malfunction test compared to the baseline multi-agent and single-agent approaches.
Physics-Guided Hierarchical Reward Mechanism for LearningBased Multi-Finger Object Grasping
May 26, 2022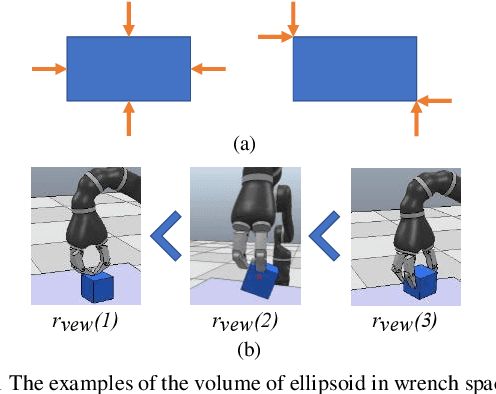
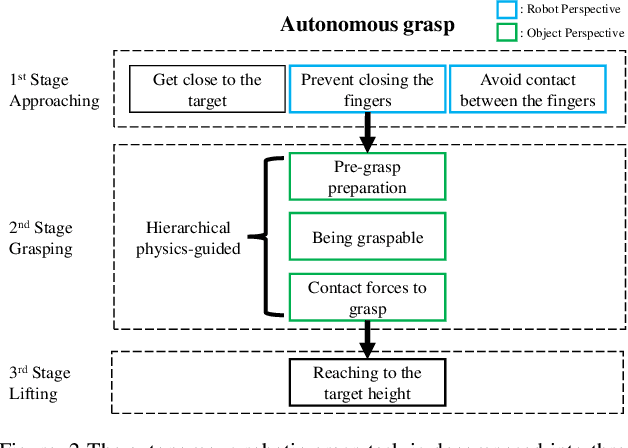
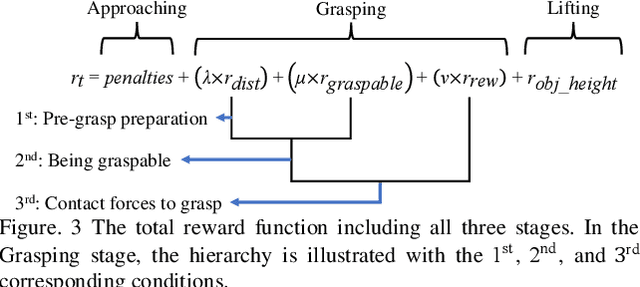

Autonomous grasping is challenging due to the high computational cost caused by multi-fingered robotic hands and their interactions with objects. Various analytical methods have been developed yet their high computational cost limits the adoption in real-world applications. Learning-based grasping can afford real-time motion planning thanks to its high computational efficiency. However, it needs to explore large search spaces during its learning process. The search space causes low learning efficiency, which has been the main barrier to its practical adoption. In this work, we develop a novel Physics-Guided Deep Reinforcement Learning with a Hierarchical Reward Mechanism, which combines the benefits of both analytical methods and learning-based methods for autonomous grasping. Different from conventional observation-based grasp learning, physics-informed metrics are utilized to convey correlations between features associated with hand structures and objects to improve learning efficiency and learning outcomes. Further, a hierarchical reward mechanism is developed to enable the robot to learn the grasping task in a prioritized way. It is validated in a grasping task with a MICO robot arm in simulation and physical experiments. The results show that our method outperformed the baseline in task performance by 48% and learning efficiency by 40%.
Deep Reinforcement Learning with Adaptive Hierarchical Reward for MultiMulti-Phase Multi Multi-Objective Dexterous Manipulation
May 26, 2022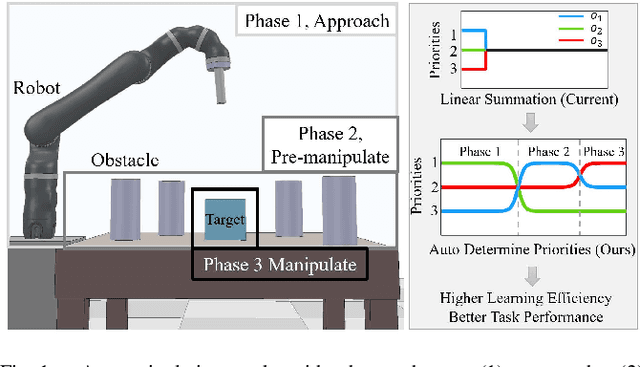
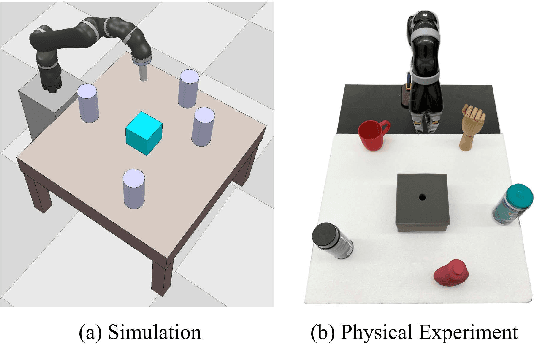
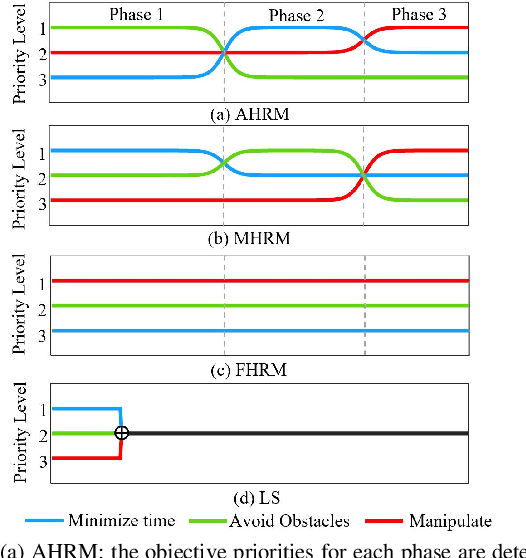
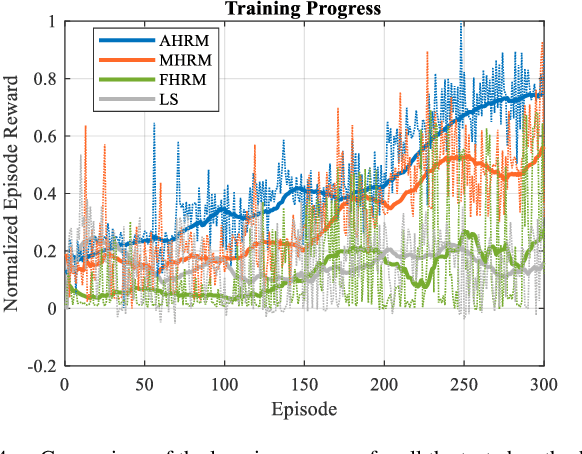
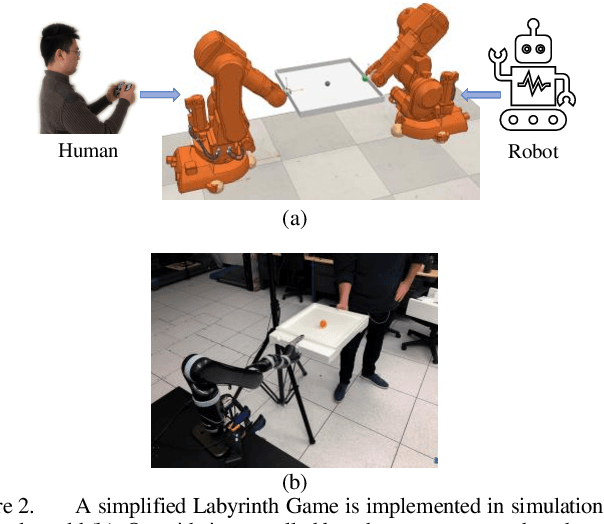
Dexterous manipulation tasks usually have multiple objectives, and the priorities of these objectives may vary at different phases of a manipulation task. Varying priority makes a robot hardly or even failed to learn an optimal policy with a deep reinforcement learning (DRL) method. To solve this problem, we develop a novel Adaptive Hierarchical Reward Mechanism (AHRM) to guide the DRL agent to learn manipulation tasks with multiple prioritized objectives. The AHRM can determine the objective priorities during the learning process and update the reward hierarchy to adapt to the changing objective priorities at different phases. The proposed method is validated in a multi-objective manipulation task with a JACO robot arm in which the robot needs to manipulate a target with obstacles surrounded. The simulation and physical experiment results show that the proposed method improved robot learning in task performance and learning efficiency.
Forming Human-Robot Cooperation for Tasks with General Goal using Evolutionary Value Learning
Dec 19, 2020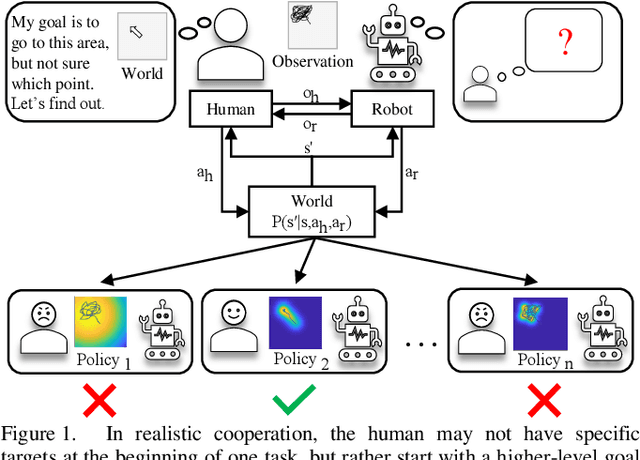
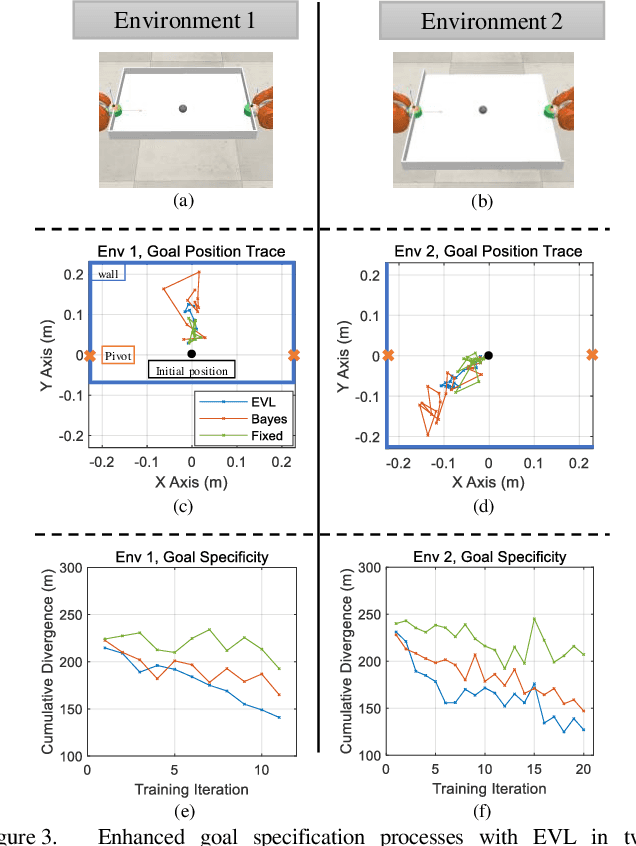
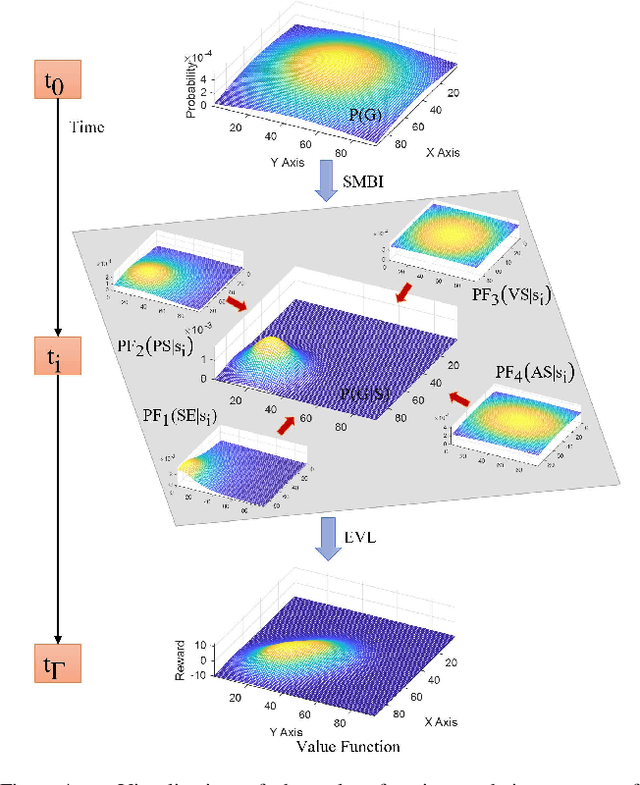
In human-robot cooperation, the robot cooperates with the human to accomplish the task together. Existing approaches assume the human has a specific goal during the cooperation, and the robot infers and acts toward it. However, in real-world environments, a human usually only has a general goal (e.g., general direction or area in motion planning) at the beginning of the cooperation which needs to be clarified to a specific goal (e.g., an exact position) during cooperation. The specification process is interactive and dynamic, which depends on the environment and the behavior of the partners. The robot that does not consider the goal specification process may cause frustration to the human partner, elongate the time to come to an agreement, and compromise or fail team performance. We present Evolutionary Value Learning (EVL) approach which uses a State-based Multivariate Bayesian Inference method to model the dynamics of goal specification process in HRC, and an Evolutionary Value Updating method to actively enhance the process of goal specification and cooperation formation. This enables the robot to simultaneously help the human to specify the goal and learn a cooperative policy in a Reinforcement Learning manner. In experiments with real human subjects, the robot equipped with EVL outperforms existing methods with faster goal specification processes and better team performance.
Meta Reinforcement Learning-Based Lane Change Strategy for Autonomous Vehicles
Aug 28, 2020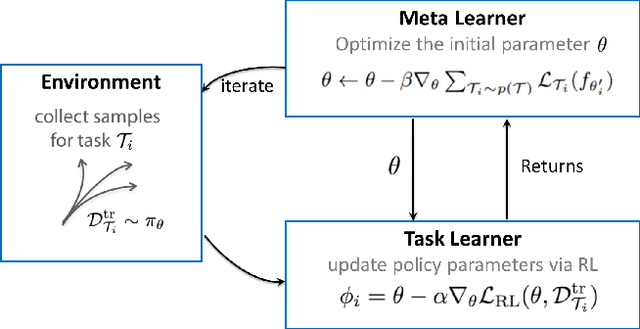
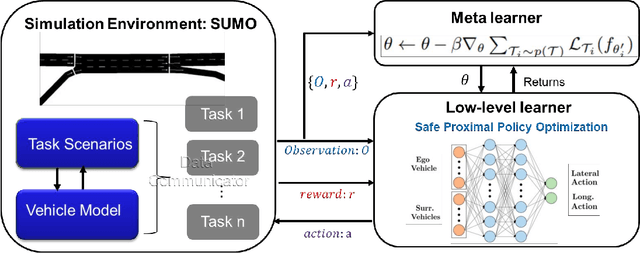
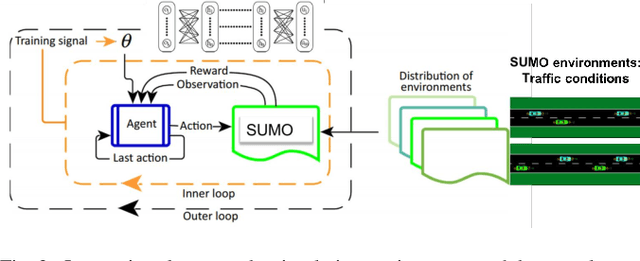
Recent advances in supervised learning and reinforcement learning have provided new opportunities to apply related methodologies to automated driving. However, there are still challenges to achieve automated driving maneuvers in dynamically changing environments. Supervised learning algorithms such as imitation learning can generalize to new environments by training on a large amount of labeled data, however, it can be often impractical or cost-prohibitive to obtain sufficient data for each new environment. Although reinforcement learning methods can mitigate this data-dependency issue by training the agent in a trial-and-error way, they still need to re-train policies from scratch when adapting to new environments. In this paper, we thus propose a meta reinforcement learning (MRL) method to improve the agent's generalization capabilities to make automated lane-changing maneuvers at different traffic environments, which are formulated as different traffic congestion levels. Specifically, we train the model at light to moderate traffic densities and test it at a new heavy traffic density condition. We use both collision rate and success rate to quantify the safety and effectiveness of the proposed model. A benchmark model is developed based on a pretraining method, which uses the same network structure and training tasks as our proposed model for fair comparison. The simulation results shows that the proposed method achieves an overall success rate up to 20% higher than the benchmark model when it is generalized to the new environment of heavy traffic density. The collision rate is also reduced by up to 18% than the benchmark model. Finally, the proposed model shows more stable and efficient generalization capabilities adapting to the new environment, and it can achieve 100% successful rate and 0% collision rate with only a few steps of gradient updates.
Learn Task First or Learn Human Partner First? Deep Reinforcement Learning of Human-Robot Cooperation in Asymmetric Hierarchical Dynamic Task
Mar 01, 2020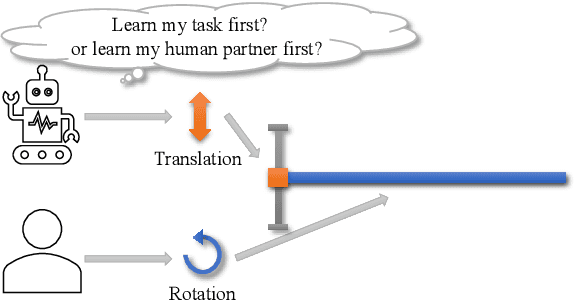
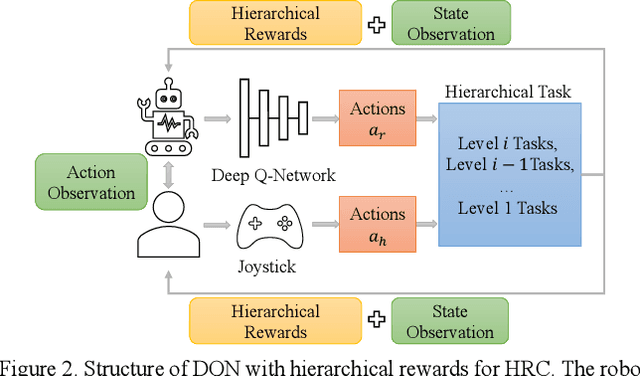
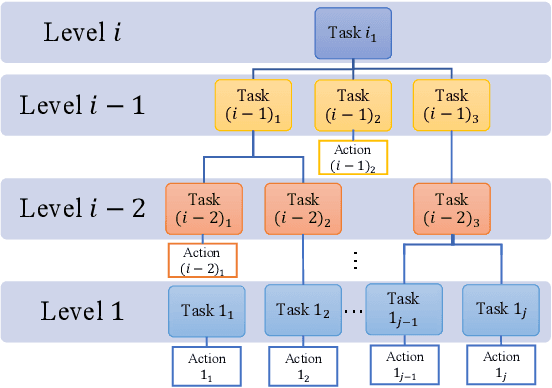
The deep reinforcement learning method for human-robot cooperation (HRC) is promising for its high performance when robots are learning complex tasks. However, the applicability of such an approach in a real-world context is limited due to long training time, additional training difficulty caused by inconsistent human performance and the inherent instability of policy exploration. With this approach, the robot has two dynamics to learn: how to accomplish the given physical task and how to cooperate with the human partner. Furthermore, the dynamics of the task and human partner are usually coupled, which means the observable outcomes and behaviors are coupled. It is hard for the robot to efficiently learn from coupled observations. In this paper, we hypothesize that the robot needs to learn the task separately from learning the behavior of the human partner to improve learning efficiency and outcomes. This leads to a fundamental question: Should the robot learn the task first or learn the human behavior first (Fig. 1)? We develop a novel hierarchical rewards mechanism with a task decomposition method that enables the robot to efficiently learn a complex hierarchical dynamic task and human behavior for better HRC. The algorithm is validated in a hierarchical control task in a simulated environment with human subject experiments, and we are able to answer the question by analyzing the collected experiment results.